Introduction Part 1
You can access the slides for this lecture here.
Chip Multiprocessors
Below is an abstract (and over simplified) model of how architecture courses focusing on single core CPUs see a processor:

In the core of the processor we have an arithmetic logic unit (ALU) that performs the computations. We also have a set of registers that can hold the instructions' operands, as well as some additional control logic. There is also an on-chip cache holding recently accessed data and instructions. The processor fetches data and instruction from the main memory off chip.
In a chip multiprocessor, also called multicore processor, you have several instances of the core of the processor on a single chip:

In this example we have a dual-core. Each core is a duplicate of most of we will find in a single core CPU: ALU, registers, caches, etc. While a single core processor can only execute one instruction at a time, a multicore can execute n instructions at the same time
An interesting question to ask is: why were these chip multiprocessors invented?
Here are some pictures of transistors:
From a very simplistic point of view we can see these as ON/OFF switches that sometimes let the current flow and sometimes not. They are the basic block with which we construct the logic gates that are making the modern integrated circuits used in processors. Broadly speaking, the computing power of a CPU is function of the number of transistors it integrates.
if we consider the first processor commercialised, in 1971, it had in the order of thousands of transistors:

A few years later processors were made of tens of thousands of transistors. A few years later it was hundreds of thousands, and since the 2000s we are talking about millions of processors. Since that time processors also start to have multiple compute unites or cores. Before that they had only one.
Fast-forward closer to today we now have tens of billions of transistors in a single chip:

They also commonly integrate several compute units. The Intel i7 from 2011 has 6 cores. The Qualcomm Snapdragon chip is an embedded processor with 4 ARM64 cores. And a recent server processor with 64 cores. Why did processor started to have more and more cores? Why this increase in number of compute units (cores) per chip?
Core Count Increase
For over 40 years we have seen a continual increase in the power of processors. This has been driven primarily by improvements in silicon integrated circuit technology: circuits continue to integrate more and more transistors. Until the early 2000s, this translated into a direct increase of the single core CPU clock frequency, i.e. speed: transistors are smaller, we can pack more on a chip but they consume less, so they can be clocked faster. It was a good time to be a software programmer: if a program was too slow, just wait for the next generation of computers to get a speed boost.
But the basic circuit speed increase become limited. For power consumption and heat dissipation reasons, the clock frequency of CPUs has not seen any significant improvement since the mid 2000s. Other architectural approaches to increase single processor speed have also been exhausted.
Still, the amount of transistors that can be integrated in a single chip continued to increase. So, if the speed of a single processor cannot increase, and we can still put more transistor on a chip, the solution is to put more processors on a single chip, and try to have them work together somehow.
Say we want to create a dual-core processor. Will it be twice as fast as the single core version? It's not that simple and has several implications that we will cover in this course. First, in terms of hardware, what processor or what processor(s) to put on the multicore? How to connect them? How do they access memory? Second, from the software point of view, how can we program this multicore processor? Can we use the same programming paradigms and languages we used for single core CPUs? How can we express the parallelism that is inherent to chip multiprocessors?
The terms core and processor will be used interchangeably in the rest of this course
Moore's Law
This is not really a law, more an observation/prediction, made by an engineer named Gordon Moore. It states that the transistor count on integrated circuits doubles every 18 months.
The transistor count on a chip depends on two factors: the transistor size and the chip size. Consider the evolution of the feature size (basically transistor size) between the Intel 386 from 1985 and the Apple M1 Max from 2021:
| CPU | Feature (transistor) size | Die (chip) size | Transistors integrated |
|---|---|---|---|
| Intel 386 (1985) | 1.5 μm | 100 mm2 | 275,000 |
| Apple M1 Max (2021) | 5 nm | 420.2 mm2 | 57,000,000,000 |
As one can observe the size of a transistor saw a 300x decrease, while the size of the chip itself, only went down by 4x over the same period of time. We can conclude that the increase in transistors/chip is mostly due to transistor size reduction.
Smaller Used to Mean Faster, but not Anymore
Why do smaller transistor translate in faster circuits? From a high level point of view, due to their electric properties, smaller transistors have a faster switch delay. This means that they can be clocked with a higher frequency, making the overall circuit faster. This was the case in the good old days when clock frequency kept increasing, however that trend stopped in the early/mid 2000s: the transistors became so tightly packed together on the chip that power density and cooling became problematic: clocking them with too high of a frequency would basically melt the chip.
The End of Dennard Scaling and Single Core Performance Increase
Dennard Scaling was this law from a 1974 paper stating that, based on the electric properties of transistors, as they grew smaller and we packed more on the same chip, they consumed less power, so the power density stayed constant. At the time experts concluded that power consumption/heating would not be an issue as transistors became smaller and more tightly integrated.
This law broke down in the mid-2000s, mostly due to the high current leakage coming with smaller transistor sizes. This is illustrated on this graph:
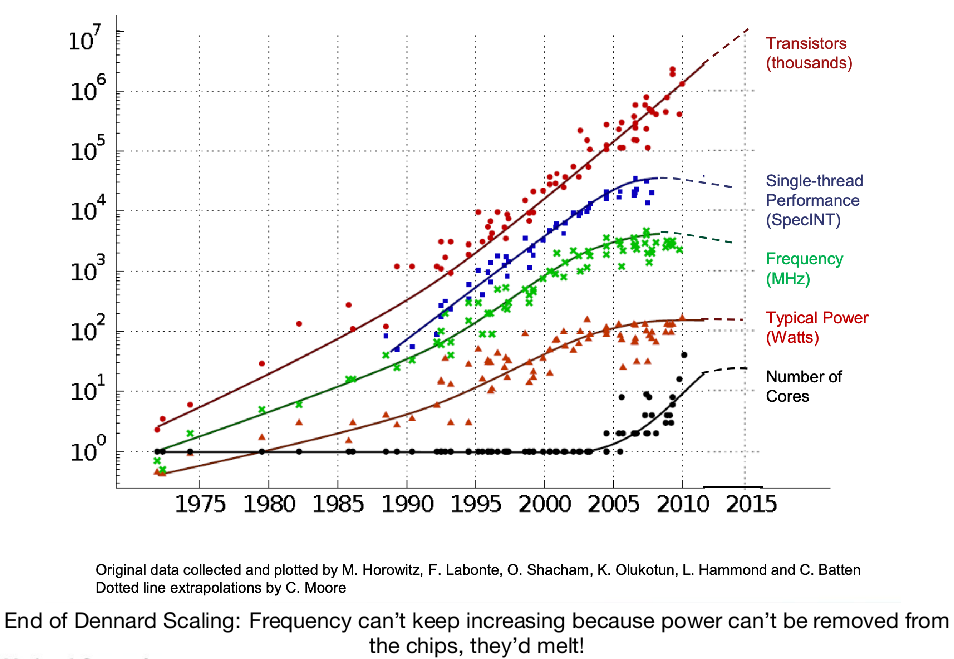
As one can see both the power and the frequency hit a plateau around that time, and single thread performance does to, proportionally. The number of transistors integrated keeps increasing, though.
Here is another view on the issue, if you look at single threaded integer performance:
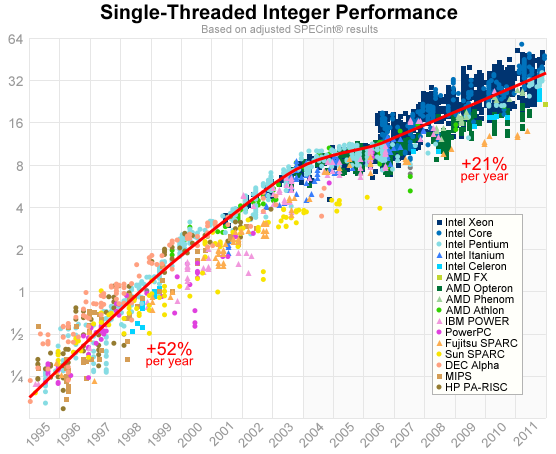
These numbers come from a standard benchmark named SPEC. As one can see the increase in performance has been more than divided by two. And if there is still some degree of increase, it does not come from frequency but from other improvements such as bigger caches or deeper / more parallel pipelines
Attempts at Increasing Single Core Performance
At that point we cannot increase the clock frequency, but we can still integrate more and more transistor in a chip. Is it possible to use these extra transistors to increase single core performance? It is indeed possible, although the solutions quickly showed limitations. Building several parallel pipelines was explored, to exploit Instruction Level Parallelism (ILP). However, ILP has diminished returns beyond ~4 pipelines. Another solution in to integrate bigger caches, but it becomes hard to get benefits past a certain size. In conclusion, efforts at increasing single core performance were quickly exhausted in the mid 2000s.
The "Solution": Multiple Cores
In the context previously described, an intuitive solution was to put multiple CPUs (cores) on a single integrated circuit (chip), named "multicore chip" or "chip multiprocessor", and to use these CPUs in parallel somehow to achieve higher performance. From the hardware point of view this represents a simpler to design vs. increasingly complex single core CPUs. But an important consideration is also that these processors cannot be programmed in the exact same way single core CPUs used to be programmed.
Multicore "Roadmap"
Below is an evolution (and projection) with time of the amount of cores per chip, as well as the feature size:
| Date | Number of cores | Feature size |
|---|---|---|
| 2006 | ~2 | 65 nm |
| 2008 | ~4 | 45 nm |
| 2010 | ~8 | 33 nm |
| 2012 | ~16 | 23 nm |
| 2014 | ~32 | 16 nm |
| 2016 | ~64 | 12 nm |
| 2018 | ~128 | 8 nm |
| 2020 | ~256 | 6 nm |
| 2022 | ~512 | 4 nm |
| 2024 | ~1024 | 3 nm |
| 2026 | ~2048 | 2 nm |
| scale discontinuity? | ||
| 2028 | ~4096 | |
| 2030 | ~8192 | |
| 2032 | ~16384 |
As one can see we went from the first dual cores in the 2000s to tens and even hundreds of cores today. This has been achieved with the help of a significant reduction in feature size, however it is unclear if this trend can continue as it becomes harder and harder to construct smaller processors.
Introduction Part 2
You can access the slides for this lecture here.
We have seen that due to several factors, in particular the clock frequency hitting a plateau in the mid 2000s, single core CPU performance could not increase anymore. As a result CPU manufacturers started to integrate multiple cores on a single chip, creating chip multiprocessors or multicores. Here we will discuss how to exploit the parallelism offered by these CPUs, and also give an overview of the course unit.
How to Use Multiple Cores?
How to leverage multiple cores? Of course one can run 2 separate programs, each running in a different process, on two different cores in parallel. This is fine, and these two programs can be old software originally written for single core processor, they don't need to be ported. But the real difficulty is when we want increased performance for a single application. So we need a collection of execution flows, such as threads, all working together to solve a given problem. Both cases are illustrated below:

Instruction- vs. Thread-Level Parallelism
Instruction-Level Parallelism. One way to exploit parallelism is through the use of instruction level parallelism (ILP). How does it work? Imagine we have a sequential program composed of a series of instructions to be executed one after the other. The compiler will take this program and is able to determine what instructions can be executed in parallel on multiple cores. Sometimes instructions can be even executed out of order, as long as there is no dependencies between them. This is illustrated below:

ILP is very practical because we just have to recompile the program, there is no need to modify the program i.e. no effort from the application programmer. However the amount of parallelism we can extract with such techniques is very limited, due to the dependencies between instructions.
Thread-Level Parallelism (TLP). Another way to exploit parallelism is to mostly rewrite your application with parallelism in mind. The programmer divides the program into (long) sequences of instructions that are executed concurrently, with some running in parallel on different cores:

The program executing is still represented as a process, and the sequences of instructions running concurrently are named threads. Now because of scheduling we do not have control over the order in which most of the threads' operations are realised, so for the computations to be meaningful the threads need to synchronise somehow.
Another important and related issue, is how to share data between threads. Threads belonging to the same program execute within a single process and they share an address space, i.e. they will read the same data at a given virtual address in memory. What happens if a thread reads a variable currently being written by another thread? What happen if two threads try to write the same variable at the same time? Obviously we don't want these things to happen and shared data access need to be properly synchronised: threads need to make sure they don't step on each other's feet when accessing shared data.
A set of threads can run concurrently on a single core. Thy will time-share the core, i.e. their execution will be interlaced and the total execution time for the set of threads will be the sum of each thread execution time. On a multicore processor, threads can run in parallel on different cores, and ideally the total execution time would be the time of the sequential version divided by the number of threads.

So contrary to ILP which is limited, TLP can really help to fully exploit the parallelism brought by multiple cores. However that means rewriting the application to use threads so there is some effort required from the application programmer. The application itself also needs to be suitable for being divided into several execution flows.
Data Parallelism
The data manipulated by certain programs, as well as the way it is manipulated, is very well-fitted for parallelism. For example it is the case with applications doing computations on single and multi-dimensional arrays. Here we have a matrix-matrix addition, where each element of the result matrix can be computed in parallel. This is called data parallelism. Many applications exploiting data parallelism perform the same or a very similar operation on all elements of a data set (an array, a matrix, etc.). In this example, where two matrices are summed, each thread (represented by a color) sums the two corresponding members of the operand matrices, and all of these sums can be done in parallel:

A few examples of application domains that lend themselves well to data parallelism are matrix/array operations (extensively used in AI applications), Fourier Transform, a lot of graphical computations like filters, anti-aliasing, texture mapping, light and shadow computations, etc. Differential equations applications are also good candidates, and these are extensively used in domains such as weather forecasting, engineering simulations, and financial modelling.
Complexity of Parallelism
Parallel programming is generally considered to be difficult, but depends a lot on the program structure:

In scenarios where all the parallel execution flows, let's say threads, are doing the same thing, and they don't share much data, then it can be quite straightforward. On the other end, in situations where all the threads are doing something different, or when they share a lot of data in write mode, when they communicate a lot and need to synchronise, then such programs can be quite hard to reason about, to develop, and to debug.
Chip Multiprocessor Considerations
Here are a few considerations with chip multiprocessors that we will cover in this course unit. First how should the hardware, the chip itself, be built. When we have multiple cores, how are they connected together? How are they connected to memory? Are they supposed to be used for particular programming patters such as data parallelism? or multithreading? If we want to build a multicore, should we use a lot of simple cores or just a few complex cores? Should the processor be general purpose, or specialised towards particular workloads?
We also have problematics regarding software, i.e. how to program these chip multiprocessors. Can we use a conventional programming language? Possibly an extended version of a popular language? Should we rather use a specific language, or a totally new approach?
Overview of Lectures
Beyond this introduction, we will cover in this course unit the following topics:
- Thread-based programming, thread synchronisation
- Cache coherency in homogeneous shared memory multiprocessors
- Memory consistency
- Hardware support for thread synchronisation
- Operating system support for threads, concurrency within the kernel
- Alternative programming views
- Speculation and transactional memory
- Heterogeneous processors/cores and programs
- Radical approaches (e.g. dataflow programming)
Shared Memory Programming
You can access the slides for this lecture here. All the code samples given here can be found online, alongside instructions on how to bring up the proper environment to build and execute them here.
Processes and Address Spaces
The process is the basic unit of execution for a program on top of an operating system: each program runs within its own process. A process executing on the CPU accesses memory with load and store instructions, indexing the memory with addresses. In the vast majority of modern processors virtual memory is enabled very early at boot time, and from that point every load/store instruction executed by the CPU targets a virtual address.
With virtual memory, the OS gives to each process the illusion that it can access all the memory.
The set of addresses the CPU can index with load/store instructions when running a given process is called the virtual address space (abbreviated as address space from now on).
It ranges from address 0 all the way to what the width of the address bus lets the CPU address, generally 48 bits (256 TB).
This (very large) size for the virtual address space of each process is unrelated to the amount of RAM in the computer: in practice the address space is very sparse and most of it is not actually mapped to physical memory.
On this example we have two address spaces (i.e. 2 processes), and both see something different in memory at address 0x42:

This is because through virtual memory, the address 0x42 is mapped to different locations in physical memory.
This mapping is achieved through the page table.
Each page table defines a unique virtual address space, and as such there is one page table per process.
This also allows to make sure processes cannot address anything outside their address space.
To leverage parallelism, two processes, i.e. two programs, can run on two different cores of a multicore processor. However, how can we use parallelism within the same program?
Threads
A thread is a flow of control executing a program It is a sequence of instructions executed on a CPU core A process can consist of one or multiple threads In other words, we can have for a single program several execution flows running on different cores and sharing a single address space.
In the example below we have two processes: A and B, each with its own address space:

In our example process A runs 3 threads, and they all see the green data.
Process B has 4 threads, and they see the same orange data.
A cannot access the orange data, and B cannot access the green data, because they run in disjoint address spaces.
However, all threads in A can access the green data, and all threads in B can access the orange data.
For example, if two threads in B read the memory at the address pointed by the red arrows, they will see the same value: x: threads communicate using shared memory, by accessing a common address space.
Seeing the same address space is very convenient for communications, that can be achieved through global variables or pointers to anywhere in the address space.
One can program with threads in various languages:
- C/C++/Fortran – using the POSIX threads (Pthread) library
- Java
- Many other languages: Python, C#, Haskell, Rust, etc.
Threads in C/C++ with Pthread
Pthread is the POSIX thread library available for C/C++ programs.
We use the pthread_create function to create and launch a thread.
It takes as parameter the function to run and optionally its arguments.
In the illustration below we have time flowing downwards.
The main thread of a process (that is automatically created by the OS when the program is started) calls pthread_create to create a child thread.
Children threads can use pthread_exit to stop their execution, and parent threads can call pthread_join to wait for another thread to finish:

A good chunk of this course unit, including lab exercises 1 and 2, will focus on shared memory programming in C/C++ with pthreads.
Use the Linux manual pages for the different pthread functions we'll cover (man pthread_*) and Google “pthreads” for lots of documentation.
In particular see the Oracle Multithreaded Programming Guide.
Here is an example of a simple pthread program:
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
#define NOWORKERS 5
// Function executed by all threads
void *thread_fn(void *arg) {
int id = (int)(long)arg;
printf("Thread %d running\n", id);
pthread_exit(NULL); // exit
// never reached
}
int main(void) {
// Each thread is controlled through a pthread_t data structure
pthread_t workers[NOWORKERS];
// Create and launch the threads
for(int i=0; i<NOWORKERS; i++)
if(pthread_create(&workers[i], NULL, thread_fn, (void *)(long)i)) {
perror("pthread_create");
return -1;
}
// Wait for threads to finish
for (int i = 0; i < NOWORKERS; i++)
if(pthread_join(workers[i], NULL)) {
perror("pthread_join");
return -1;
}
printf("All done\n");
}
This program creates 5 children threads which all print a message on the standard output then exit. The main thread waits for the 5 children to finish, and exit. This is all done using the functions we just covered.

Notice how an integer is passed as parameter to each thread's function: it is cast as a void * because this is what pthread_create expects (in case we want to pass something larger we would put a pointer to a larger data structure here).
That value is passed as the parameter arg to the thread's function.
In our example we cast it back to an int.
We use the threads' parameters to uniquely identify each thread with an id.
Assuming the source code is present in a source file named pthread.c, you can compile and run it as follows:
gcc pthread.c -o pthread -lpthread
./pthread
Threads in Java
There are two ways of defining a thread in Java:
- Creating a class that inherits from
java.lang.Thread. - Creating a class that implements
java.lang.Runnable.
The reason to be for the second approach is that it lets you inherit from something else than Thread, as multiple inheritance is not supported in Java.
With both approaches, one need to implement the run method to define what the thread does when it starts running.
From the parent, Thread.start start the execution of the thread, and Thread.join waits for a child to complete its execution.
Below is an example of a Java program with the exact same behaviour as our pthread C example, using the first approach (inheriting from java.lang.Thread):
class MyThread extends Thread {
int id;
MyThread(int id) { this.id = id; }
public void run() { System.out.println("Thread " + id + " running"); }
}
class Demo {
public static void main(String[] args) {
int NOWORKERS = 5;
MyThread[] threads = new MyThread[NOWORKERS];
for (int i = 0; i < NOWORKERS; i++)
threads[i] = new MyThread(i);
for (int i = 0; i < NOWORKERS; i++)
threads[i].start();
for (int i = 0; i < NOWORKERS; i++)
try {
threads[i].join();
} catch (InterruptedException e) { /* do nothing */ }
System.out.println("All done");
}
}
This example defines the MyThread class inheriting from Thread.
In the constructor MyThread we just initialise an identifier integer member variable id.
We implement the run method, it just prints the fact that the thread is running as well as its id.
In the main function we create an array of MyThread objects, one per thread we want to create.
Each is given a different id.
Then we launch them all in a loop with start, and we wait for each to finish with join.
We can compile and run it as follows:
javac java-thread.java
java Demo
The second approach to threads in Java, i.e. implementing the Runnable interface, is illustrated in the program below:
class MyRunnable implements Runnable {
int id;
MyRunnable(int id) { this.id = id; }
public void run() { System.out.println("Thread " + id + " running"); }
}
class Demo {
public static void main(String[] args) {
int NOWORKERS = 5;
Thread[] threads = new Thread[NOWORKERS];
for (int i = 0; i < NOWORKERS; i++) {
MyRunnable r = new MyRunnable(i);
threads[i] = new Thread(r);
}
for (int i = 0; i < NOWORKERS; i++)
threads[i].start();
for (int i = 0; i < NOWORKERS; i++)
try {
threads[i].join();
} catch (InterruptedException e) { /* do nothing */ }
System.out.println("All done");
}
}
Here we create a class MyRunnable implementing the interface in question.
For each thread we create a Thread object and we pass to the constructor a MyRunnable object instance.
Then we can call start and join on the thread objects.
Output of Our Example Programs
For both Java and C examples, an example output is:
Thread 1 running
Thread 0 running
Thread 2 running
Thread 4 running
Thread 3 running
All done
One can notice that over multiple execution, the same program will yield a different order. This illustrates the fact that without any form of synchronisation, the programmer has no control over the order of execution.: the OS scheduler decides, and it is nondeterministic. A possible scheduling scenario is:

Another possible scenario assuming a single core processor:

Of course this lack of control over the order of execution can be problematic in some situations where we really need a particular sequencing of certain thread operations, for example when a thread needs to accomplish a certain task before another thread can start doing its job. Later in the course unit we will see how to use synchronisation mechanisms to manage this.
Data Parallelism
As we saw previously, data parallelism is a relatively simple form of parallelism found in many applications such as computational science. There is data parallelism when we have some data structured in such a way that the operations to be performed on it can easily be parralelised. This is very suitable for parallelism, the goal is to divide the computations into chunks, computed in parallel.
Take for example the operation of summing two arrays, i.e. we sum each element of same index in A and B and put the result in C:

We can have a different thread realise each addition, or fewer threads each taking care of a subset of the additions. This type of parallelism is exploited in vector and array processors. General purpose CPU architectures have vector instructions extensions allowing things like applying the same operation on all elements of an array. For example Intel x86-64 use to have SSE and now AVX. From a very high level perspective, GPUs also work in that way.
Let's see a second example more in details, matrix-matrix multiplication. We'll use square matrices for the sake of simplicity. Recall that with matrix multiplication, each element of the result matrix is computed as the sum of the multiplication of the elements in one column of the first matrix with the element in one line of the second matrix:

How can we parallelise this operation? We can have 1 thread per element of the result matrix, each thread computing the value of the element in question With a n x n matrix that gives us n2 threads:

If we don't have a lot of cores we may want to create fewer threads, it is generally not very efficient to have more threads than cores So another strategy is to have a thread per row or per column of the result matrix:

- Finally, we can also create an arbitrary number of threads by dividing the number of elements of the result matrix by the number of threads that we want and have each thread take care of a subset of the elements:

Given all these strategies, there are two important questions with respect to the amount of effort/expertise required from the programmer:
- What is the best strategy to choose according to the situation? Does the programmer need to be an expert to perform this choice?
- How does the programmer indicate in the code the strategy to use? Is there a lot of code to add to a non-parallel version of the code? If we want to change strategy, do we have to rewrite most of the program?
The programmer's effort should in general be minimised if we want a particular parallel framework, programming language or style of programming to become popular/widespread. But of course it also depends on the performance gained from parallelisation Maybe it's okay to rewrite entirely an application with a given paradigm/language/framework if it results in a 10x speedup.
Implicit vs. Explicit Parallelism
Here is an example of C/C++ parallelisation framework called OpenMP:
#include <stdio.h>
#include <stdlib.h>
#include <omp.h>
#define N 1000
int A[N][N];
int B[N][N];
int C[N][N];
int main(int argc, char **argv) {
for(int i=0; i<N; i++)
for(int j=0; j<N; j++) {
A[i][j] = rand()%100;
B[i][j] = rand()%100;
}
#pragma omp parallel
{
for(int i=0; i<N; i++) // this loop is parallelized automatically
for(int j=0; j<N; j++) {
C[i][j] = 0;
for(int k=0; k<N; k++)
C[i][j] = C[i][j] + A[i][k] * B[k][j];
}
}
printf("matrix multiplication done\n");
return 0;
}
We can parallelise the matrix multiplication operation in a very simple way by adding a simple annotation in the code: #pragma omp parallel.
All the iterations of the first outer loop will then be done in parallel by different threads.
The programmer's effort is minimal: the framework is taking care of managing the threads, and also to spawn the ideal number of threads according to the machine executing the program.
We will cover OpenMP in more details later in this course unit.
To compile and run this program, assuming the source code is in a file named openmp.c:
gcc openmp.c -fopenmp -o openmp
./openmp
This notion of programmer's effort is linked to the concepts of explicit and implicit parallelism. With explicit parallelism, the programmer has to write/modify the application's code to indicate what should be done in parallel and what should be done sequentially. This ranges from writing all the threads' code manually, or just putting some annotations in sequential programs (e.g. our example with OpenMP). On the other hand, we have implicit parallelism, which requires absolutely no effort from the programmer: the system works out parallelism by itself. This is achieved for example by some languages able to make strong assumption about data sharing, for example pure functions in functional languages have no side effects so they can run in parallel.
Example Code for Implicit Parallelism
Here are a few examples of implicit parallelism. Languages like Fortran allow expression on arrays, and some of these operations will be automatically parralelised, for example summing all elements of two arrays:
A = B + C
If we have pure functions (functions that do not update anything but local variables), e.g. with a functional programming language, these functions can be executed in parallel.
In these examples the compiler can run f and g in parallel:
y = f(x) + g(z)
Another example:
p = h(f(x),g(z))
Automatic Parallelisation
In an ideal world, the compiler would take an ordinary sequential program and derive the parallelism automatically. Implicit parallelism is the best type of parallelism from the engineering effort point of view, because the programmer does not have to do anything. If we have a sequential program it would be great if the compiler can automatically extract all the parallelism. There was a lot of effort invested in such technologies at the time of the first parallel machines, before the multicore era. It works well on small programs but in the general case, analysing dependencies in order to define what can be done in parallel and what needs to be done sequentially becomes very hard. And of course the compiler needs to be conservative not to break the program, i.e. if it is not 100% sure that two steps can be run in parallel they need to run sequentially. So overall performance gains through implicit parallelism are quite limited, and to get major gains one need to go the explicit way.
Example Problems for Parallelisation
Below are a few examples of dependencies that a compiler may face when trying to extract parallelism automatically. They all regard parallelising all of some iterations of a loop.
Case 1. Here, in the first loop, 3 slots after the index computed at each iteration, we have a read dependency:
for (int i = 0 ; i < n-3 ; i++) {
a[i] = a[i+3] + b[i] ; // at iteration i, read dependency with index i+3
}
Case 2. Here we have another read dependency, this time 5 slots before the index computed at each iteration:
for (int i = 5 ; i < n ; i++) {
a[i] += a[i-5] * 2 ; // at iteration i, read dependency with index i-5
}
Case 3. Here, still a read dependency, and we don't know if the slot read is before or after the one being computed:
for (int i = 0 ; i < n ; i++) {
a[i] = a[i + j] + 1 ; // at iteration i, read dependency with index ???
}
Automatic Parallelisation
Let's consider case 1 above. We can illustrate the data dependency over a few iterations of the loop as follows:

If we parallelise naively and run each iteration in parallel, there is a chance for e.g. iteration 3 to finish before iteration 0, which would break the program. We can observe that the dependency has a positive offset: we read at each iteration what was in the array before the loop started. We are never supposed to read a value computed by the loop itself. So the solution to parallelise this loop is to internally make a new version of the array and read from an unmodified copy:
parrallel_for(int i=0; i<n-3; i++)
new_a[i] = a[i+3] + b[i];
a = new_a;
If we consider case 2 above, the trick we just presented does not work. Let's illustrate the dependency:

Because what we read at iteration i is supposed to have been written 5 iteration before, we can't rely on a read-only copy
Also, parallelising all iterations will break the program.
We observe that at a given time, there is no dependency between sets of 5 iterations, (e.g. iterations 5-9 or iterations 10-14).
The solution here is thus to limit the parallelism to 5.
Concerning case 3 above, because of the way the code is structured, it is not possible to automatically parallelise the loop.
Shared Memory
Everything in this lecture has been said on the basis that threads share memory In other words they can all access the same memory, and they will all see the same data at a given address Without shared memory, for example when the concurrent execution flows composing a parallel application run on separate machines, these execution flows have to communicate via messages, more like a distributed system.
Shared Memory Multiprocessors
You can access the slides for this lecture here.
We have previously introduced how to program with threads that share memory for communication. Here we will talk about how the hardware is set up to ensure that threads running on different cores can share memory by seeing a common address space. In particular, we will introduce the issue of cache coherency on multicore processor.
Multiprocessor Structure
The majority of general purpose multiprocessors are shared memory. In this model all the cores have a unified view on memory, e.g. in the figure on the top of the example below they can all read and write the data at address x in a coherent way. This is by opposition to distributed memory systems where each core or processor has its own local memory, and does not necessarily have a direct and coherent access to other processor's memory.

Shared memory multiprocessors are dominant because they are easier to program. However, shared memory hardware is usually more complex. In particular, each core on a shared memory multiprocessor has its own local cache, Here we will introduce the problem of cache coherency in shared memory multiprocessor systems. In the next lecture we'll see how it is managed concretely.
Caches
A high performance uniprocessor has the following structure:

Main memory is far too slow to keep up with modern processor speed it can take up to hundreds of cycles to access, versus the CPU registers that are accessed instantaneously/ So another type of on-chip memory is introduced, the cache. It is much faster than main memory, being accessed in a few cycles. It is also expensive, so its size is relatively small, and thus the cache is used to maintain a subset of the program data and instructions.
The cache can have multiple levels: generally in multiprocessors we have a level 1 and sometimes level 2 caches that are local to each core, and a shared last level cache.
If an entire program data-set can fit in the cache, the CPU can run at full speed. However, it is rarely the case on modern applications and new data/instructions needed by the program have to be fetched from memory (on each cache miss). Also, newly written data in cache must eventually be written back to main memory.
The Cache Coherency Problem
With just one CPU things are simple, data just written to the cache can be read correctly whether or not it has been written to memory. But things get more complicated when we have multiple processors. Indeed, several CPUs may share data, i.e. one can write a value that the other needs to read. How does that work with the cache?
Consider the following situation, illustrated on the schema below.
We have a dual-core with CPU A and B, and some data x in RAM.
CPU A first reads it, then updates it in its own cache into x'.
Then later we have CPU B that wishes to read the same data.
It's not in its cache, so it fetches it from memory, and ends up reading the old value x.

Clearly that is not OK: A and B expect to share memory and to see a common address space. Threads use shared memory for communications and after some data, e.g. a global variable, is updated by a thread running on a core, another thread running on another core expects to read the updated version of this data: cores equipped with caches must still have a coherent view on memory, this is the cache coherency problem.
The Cache Coherency Problem
An apparently obvious solution would be to ensure that every write in the cache is directly propagated to memory. It is called a write-through cache policy:

However, this would mean that every time we write we need to write to memory. And every time we read we also need to fetch from memory in case the data was updated. This is very slow and negates the cache benefits, thus it's not a good idea.
The Cache Coherency Problem
So how can we overcome these issues? Can we communicate cache-to-cache rather than always go through memory? In other words, when a new value is written in one cache, all other values somehow located in other caches somehow would need to be either updated or invalidated. Another issue is: what if two processors try to write to the same location. In other words how to avoid having two separate cache copies? This is what we refer to by cache coherency. So things are getting complex, and we need to develop a model. How to efficiently achieve cache coherency in a shared memory multiprocessor is the topic of the next lecture.
Cache Coherence in Multiprocessors
You can access the slides for this lecture here.
We have previously introduced the issue of cache coherence in multiprocessors. The problem is that with a multiprocessor each core has a local cache, and data in that cache may not be in sync with memory. We need to avoid situations where two cores have multiple copies of the same data with different values for that data. If we try to naively use in a multicore a traditional cache system (as used in single core CPUs), the following can happen:

- At first we have the data
xin memory and core A reads it then updates it tox'. For performance reasons A does not write the data in memory yet. - Later, B wants to read the data.
It's not in B's cache so it fetched it from memory: B reads
xwhich is not the last version of the data.
This of course breaks the program. So we need to define a protocol to make sure that all caches have a coherent view on memory. This involves cache to cache communication: for performance reasons, we want to avoid involving memory as much as we can.
Coping with Multiple Cores
Here we will cover a simple protocol named bus-based coherence or bus snooping. All the cores are interconnected with a bus that is also linked to memory:

Each core has have some special cache management hardware. This hardware can observe all the transactions on the bus and it is also able to modify the cache content independently of the core. With this hardware, when a given cache observes pertinent transactions on the bus, it can take appropriate actions Another way to look at this is that a cache can send messages to other caches, and receive messages from other caches.
Cache States, MSI Protocol
On the hardware we described we'll present now a cache coherence protocol, i.e. a way for the caches to exchange messages in order to maintain a coherent view on the memory's content for all cores.
Recall that caches hold data (and read/write it from/to memory) at the granularity of a cache line (generally 64 byte). Each cache has 2 control bits for each line it contains, encoding the state the line currently is in:

Each line can be can be in one of three different states:
- Modified state: the cache line is valid and has been written to but the latest
values have not been updated in memory yet
- A line can be in the modified state in at most 1 core
- Invalid: there may be an address match on this line but the data is
not valid
- We must go to memory and fetch it or get it from another cache
- Shared: implicit 3rd state, not invalid and not modified
- A valid cache entry exists and the line has the same values as main memory
- Several caches can have the same line in that state
These states can be illustrated as follows:



The Modified/Shared/Invalid states, as well as the transitions we'll describe next, define the MSI protocol.
Possible States for a Dual-Core CPU
Let's describe the MSI protocol on a dual core processor for the sake of simplicity. For a given cache line, we have the following possible states:

The different combinations of states on the dual core are as follows:
- (a) modified-invalid: one cache has the line in the modified state, i.e. the data in there is valid and not in sync with memory, and the other cache has the line in the invalid state.
- (b) invalid-invalid: we have the line invalid in both caches.
- (c) invalid-shared: the line is invalid in one cache, and shared (i.e. valid and in sync with memory) in the other cache.
- (d) shared-shared: the line is valid and in sync with memory in both caches.
By symmetry we also have (a') invalid-modified as well as (c') shared-invalid.
Recall that by definition if a cache has the data in the modified state, that cache should be the only one with a valid copy of the line in question, hence the states modified-shared and modified-modified, which break that rule, are not possible.
State Transitions
After we listed all the possible legal states, let's see now, for each state, how read and write operations on each of the two cores affect the state of the dual core. This regards 3 aspects:
- What are the messages sent between cores: we'll see messages requesting a cache line, messaging asking a remote core to invalidate a given line, and messages asking for both a line content as well as its invalidation from a remote cache.
- When memory needs to be involved, e.g. to fetch a cache line or to write it back.
- What are the state transitions between the state combinations listed above for our dual core.
State Transitions from (a) Modified-Invalid
Let's start with the modified/invalid state. In that state core 1 has the line modified, it's valid but not in sync with memory, and core 2 has the line invalid, it's in the cache but the content is out of date.
Read or Write on Core 1. If we have either a read or a write on core 1, these are just served by the cache (cache hits), no memory operation is involved, and there is no state transition.
Read on Core 2. If there is a read on core 2, because the line is invalid in its cache it cannot be served from there. So core 2 places a read request on the bus, which gets snooped by core 1. We can have only one cache in the modified state, so with this particular protocol we are aiming at a shared-shared final state. So core 1 writes back the data to memory to have it in sync, and goes to the shared state. Core 1 also sends the line content to core 2 that switches to the shared state. We end up in the (d) shared-shared state, i.e. both caches have the line valid and in sync with memory:
Write on Core 2. In case of a write on core 2, its cache has the line invalid, so it places a read request on the bus, which is snooped by core 1. Core 1 has the data in modified state so it first writes it back to memory, and then sends the line to core 2. Core 2 updates the line so it sends an invalidate message on the bus, and core 1 switches to the invalid state. Core 2 then switches to modified. Overall the state changes to (a'): invalid/modified:
State Transitions from (b) Invalid-Invalid
One may ask in what circumstances does a dual core ends up with the same cache line in the invalid state in both caches, knowing that what triggers the invalidation of a line in the cache of a given core is a write on the other core (i.e. that other core has the data in modified). A given cache line can be invalidated in both core following a write by an external actor, e.g. a device through Direct Memory Access.
Read on Core 1 or Core 2. In that state both caches have the line but its content is out of date. If there is a read on one core, the cache in question places a read request on the bus. Nobody answers and the cache then fetch the data from memory, switches the state to shared. The system ends up in the (c') shared-invalid or (c) invalid-shared state, according to which core performed the read. For example with core 1 performing the read:
Write on core 1 or 2. If there is a write on a core, the relevant cache does not know about the status of the line in other cores so it places a read request on the bus. Nobody answers so the line is fetched from memory and the write is performed in the cache so the writing core switch the state to modified. We end up in (a) modified-invalid or (a') invalid-modified according to which core performed the write operation, e.g. if it was core 1:
State Transitions from (c) Invalid-Shared
Read on Core 1. The line is in the invalid state on that cache, so it is present but the content is out of date. The other cache has the line in the shared state so it is present, valid, and in sync with memory. In case of a read on core 1, its cache places a read request on the bus, it is snooped by cache 2 which replies with the cache line. Core 1 switches to the shared state, and the system is now in the (d) shared-shared state:
Read on Core 2. In case of a read on core 2, the read is served from the cache, non memory operation is required, and there is no state transition: the system stays in (c) invalid-shared.
Write on Core 1. Because core 1 has the line in the invalid state, it starts by placing a read request on the bus. Core 2 snoops the request and replies with the data. It's in the shared state so no need for a writeback in memory. Core 1 wants to update the line, so it places an invalidate request on the bus. Core 2 receives it and switches to invalid. Finally core 1 performs the write and switches to modified. We end up in the (a) modified-invalid state:
Write on Core 2. In the case of a write on core 2, even if nobody needs to invalidate anything core 2 does not know it, so it places an invalidate message on the bus. Afterwards it performs the write in the cache and switches to the modified state. We end up in the (a') invalid-modified state:
State Transitions from (d) Shared-Shared
Read on Core 1 or Core 2. If there is a read on any of the cores, it is a cache hit, served from the cache.
Write on Core 1 or Core 2. If there is a write on a core, the core in question places an invalidate request on the bus. The other core snoops the request and switches to invalid, it was shared so there is no need for writeback. The first core can then perform the write and switches to the modified state, we end up in the (a) modified-invalid or (a') invalid-modified state depending on which core made the update, e.g. if it was core 1:
Beyond Two Cores
The MSI protocol generalises beyond 2 cores. Because of the way the snoopy bus works, the read and invalidate messages are in effect broadcasted to all cores. Any core with a valid value (shared or modified) can reply to a read request. For example here, core 1 has the line in the invalid state and wishes to perform a read so it broadcasts a read request on the bus and one of the cores having the line in the shared state replies:
When an invalidate request is received, any core in the shared state invalidates without writeback, as it is the case for core 3 and core 4 in this example:
When an invalidate message is received, a core in the modified state writes back before invalidating, e.g. core 4 in this example:
Write-Invalidate vs. Write-Update
There are two major types of snooping protocols:
- With write-invalidate, when a core updates a cache line, other copies of that line in other caches are invalidated. Future accesses on the other copies will require fetching the updated line from memory/other caches. It is the most widespread protocol, used in MSI, but also in other protocols such as MESI and MOESI, that we will cover next.
- With write-update:, when a core updates a cache line, the modification is broadcast to copies of that line in other caches: they are updated. This leads to a higher bus traffic compared to write-invalidate. Example of write-update protocols include Dragon and Firefly.
Cache Snooping Implications on Scalability
Given our description of the way cache snooping works, when an invalidate message is sent, it is important that all cores receive the message within a single bus cycle so that they all invalidate at the same time. If this does not happen, one core may have the time to perform a write during that process, which would break consistency.
This becomes harder to achieve as we connect higher numbers of cores together into a chip multiprocessor, because the invalidate signal takes more time to propagate. With more cores the bus capacitance is also higher and the bus cycle is longer. This seriously impacts performance. So overall, a cache snooping-based coherence protocol is a major limitation to the number of cores that can be supported by a CPU.
Multi-Level Caches
Many modern processors include several levels of cache. Generally, level 1 (L1) and 2 (L2) caches are per-core caches, while the level 3 (L3) cache is shared among cores:

Check out for example the technical data for the memory hierarchy of the Zen 4 micro architecture (Ryzen 7000 x86-64 processors) here with 3 levels of cache, L1 and L2 being per core, and L3 shared.
Inclusion Policy. An important design consideration for multi-level caches is the inclusion policy. It defines the fact that higher level caches must include the content of lower level caches or not. Here we will present the simplest policy: the inclusive policy. With this policy the higher-level caches are always a superset of lower level caches. In other words, a cache line present in a lower level cache is always also present in higher level caches.
With the inclusive policy cache misses bring data in lower-level caches from higher-level caches or memory. For example here misses on cache lines A and B brings them from L3 or memory into both L1 and L2 caches:

Should the cache miss require a fetch from memory, with the inclusive policy the cache line will similarly be brought into L1, L2, and L3 caches. A miss due to a line not being in L1 but present in L2 will trigger the transfer of the line from L2 to L1:

The inclusive policy makes that capacity evictions simply consists in dropping lines from lower level caches. If we take our previous example with the L1 cache full with A, B, and C, we can evict B from the L1 cache knowing it is still present in L2:

A capacity eviction in a higher level cache will trigger the eviction from the lower-level caches too, e.g. here L2 is full and A is evicted from both L2 and L1:

MSI and Multi-Level Caches. The simple MSI protocol we presented could apply to such a multi-level cache hierarchy as follows. First, the L3 cache is shared among all cores so there is no problem of coherence here.
In case of a read/write cache miss (cache line not present in local L1/L2, or cache line present but not valid), a read request is placed on the snoopy bus and it can be served from any L1/L2 cache having a valid version of the line. If no other L1/L2 cache has the line, it can be retrieved from the L3 cache in case it is present there. If not, it can be retrieved from memory.
When a core writes in the cache, it places an invalidation message on the bus. When this message is received by the other caches, they invalidate any copy of the line that may be present at levels L1 and L2.
There are others multi-level cache inclusion policies beyond the inclusive one. A good starting point to learn more about them is here.
MESI and MOESI Cache Coherence
You can access the slides for this lecture here.
Here we will present a few optimisations implemented on top of MSI. These optimisations give us two new protocols, MESI and MOESI.
Unnecessary Communication
In a snoopy bus-based cache coherence system, the bus itself is a critical resource, as it is shared by all cores. Only one component can use the bus at a time, so unnecessary use of the bus is a waste of time and impacts performance. In some scenarios, MSI can send a lot of unnecessary requests on the bus. Take for example the following case:

One core, core 2, has the data in the shared state. And all other cores have the data in the invalid state. If there is a write to core 2 we transition from invalid-invalid-invalid-shared to invalid-invalid-invalid-modified. MSI would still broadcast an invalidate request on the bus to all cores even if it's unnecessary.
However, in another scenario, for example when all cores have the data in the shared state, and there is a write on any of these cores, the broadcast is actually needed:

The central problem is that with MSI the core that writes does not know the status of the data on the other cores so it blindly broadcast invalidate messages. How can we differentiate these cases?
Optimising for Non-Shared Values
We need to distinguish between the two shared cases:
- In the first case a cache holds the only copy of a value which is in sync with memory (in other words it is not modified).
- In the second case a cache holds a copy of the value which is in sync with memory and there are also other copies in other caches.
In the first case we do not need to send an invalidate message on write, whereas in the second an invalidate message is needed:

MESI Protocol
The unshared case (first case described above) is very common: in real application, the majority of variables are unshared (e.g. all of a thread's local variables).
The key idea with MESI is to split the shared state into two states that corresponds to the two cases we have presented:
- Exclusive, in which a cache has the only copy of the cache line (and its content is in sync with memory)
- Truly shared, in which the cache holds one of several shared copies of the cache line (and once again its content is in sync with memory)
The relevant transitions are as follows. We switch to exclusive (E) after a read caused a fetch from memory. We switch to truly shared (S) after a read that gets value from another cache. These transitions are illustrated below:

MESI is a simple extension, but it yields a significant reduction in bus usage. Therefore, in practice MESI is more widely used than MSI. We won't cover MESI in details here, however a notable point is that a cache line eviction on a remote core can cause a line in the local core being in state truly shared to be the only remaining copy. In that case we should theoretically switch to exclusive but in practice it is hard to detect, so we stay in truly shared.
MOESI Protocol
MOESI is a further optimisation in which we split the modified state in two:
- Modified is the same as before, the cache contains a copy which differs from that in memory but there are no other copies.
- Owned: the cache contains a copy which differs from that in memory and there may be copies in other caches which are in state S, these copies having the same value as that of the owner.
This is illustrated below:

The owner is the only cache that can make changes without sending an invalidate message. MOESI allows the latest version of the cache line to be shared between caches without having to write it back to memory immediately. When it writes, the owner broadcasts the changes to the other copies, without a writeback:

Only when a cache line in state owned or modified gets evicted will any write back to memory be done.
Directory-Based Cache Coherence
You can access the slides for this lecture here.
Here we will cover a cache coherence protocol that is quite different from the bus-based protocols we have seen until now. It is named directory-based coherence protocol.
Directory Based Coherence
We have seen that shared bus based coherence does not scale well to large amount of cores. This is because only one entity can use the bus at a time. Can we implement a cache coherence protocol with a less directly connected network, such as a grid, or a general packet switched network:

One possible solution is to use a directory holding information about data (i.e. cache lines) in the memory We are going to describe a simple version of this scheme.
Directory Structure
The architecture of a directory-based cache coherence system is as follows:

Each core has a local cache. They are linked together through an interconnect network, as we mentioned something less directly connected than with bus-based coherence. The memory is also connected to the network. Attached to the network is also a component named the directory. The directory contains one entry for each possible cache line, so its size depends on the amount of memory. Each entry in the directory has n present bits, n being the number of cores. If one of these bits is set, it means that the corresponding cache has a copy of the line in question. For each entry there is also a dirty bit in the directory. When it is set it means that only 1 cache has the corresponding line, and that cache is the only owner of that line. In every cache each line also has a local valid bit, indicating the validity of the cache line, as well as a local dirty bit, indicating that the cache is the sole owner of the line or not. A core wishing to make a memory access may need to query the directory about the state of the line to be accessed.
Directory Protocol
Similarly to what we did for MSI, let's have a look at what happens upon core read/write operations in various scenarios, considering a dual-core CPU.
Read Hit in Local Cache. In that case a core wants to read some data, and it's present in the cache, indicated with the valid bit. There is no need to contact the directory and the core just reads from the cache:

Read miss in Local Cache. In case of a read miss (i.e. data is not present in the cache or the corresponding local valid bit is unset), the directory is consulted and the actions taken depend what happens in this scenario depends on the value of the directory dirty bit for that value.
- If the directory dirty bit is unset, first we consult the directory to see if another cache has the line in question: if that is the case, the line can be retrieved from that other cache. If no other cache has the line, it can be safely fetched from memory. The directory bit corresponding to the reading core is then set to 1, as well as the local valid bit in the cache of the reading core.
The two scenarios for a read miss in local cache with directory bit unset are illustrated below:

- If the directory dirty bit is set, we know that another cache has the last version of the cache line, and that it is the one and only owner of the line. So we force that core to sync with memory, and have it also send the line to the reading core. We can clear the directory dirty bit, as is no exclusive owner for that cache line anymore. The local valid bit is also set in the reading core, as well as the present bit in the directory for that core. This is illustrated below:

Write hit in Local Cache with Local Dirty Bit Set. In that case, we know the line in cache is valid, and that the reading core is the sole owner of that line: the write can be performed directly in the cache:

Write Hit in Local Cache with Local Dirty Bit Unset. In that case the writing core is not the sole owner of the cache line, so it consults the directory to know which caches have the line and sends invalidate messages to them. The corresponding bits in the directory can then be cleared. As the writing core is now the sole owner of the line, the local dirty bit is set and the directory dirty bit is set too.
Write Miss in Local Cache. Here again the actions to take depends on the value of the directory dirty bit for the cache line written.
- If the directory dirty bit is unset, the directory present bits are consulted to see if any cache has the line. If that is the case, the cache line is retrieved from the corresponding remote cache, and the writing core also sends an invalidate message to any remote cache having the line. If no remote cache has the line, it is fetched from memory. The present bit is set in the directory for the writing core, and the directory dirty bit is also set. Finally, the local dirty bit is set in the writing core.
This is illustrated below:

- If the directory dirty bit is set, it means that another core has the exclusive last version of the data. The writing core sends a message to the remote core, which updates memory and sends the cache line to the writing core. The writing core performs the write operation and sets its local dirty bit. In the directory, the dirty bit stays set because we still have an exclusive owner. However, the owner is now the writing core, so we set the presence bits accordingly.
This is illustrated below:

Analysis, NUMA Systems
We described a directory-based protocol that is roughly equivalent to the bus-based MSI protocol. There are multiple optimisations possible, but we won't go into details. The important thing to note is that, even if directory-based coherency is designed to scale to more cores than snooping, having a single directory centralising coherency metadata is a serious bottleneck. So the solution is to distribute this metadata, and have multiple directories, each taking care of a subset of the memory address space. This is often coupled with a distributed memory structures where part of the memory is physically local to the processor, and part is remote. This is particular to medium and large multiprocessor systems that have multiple CPU chips. The latency to access local and remote memory is different in these systems, and we talk about Non-Uniform memory Access, NUMA systems.
Here is an example of such system:

In this example we have 2 sockets, which means 2 processor chips, interconnected, so they can operate on a single shared address space. Part of the physical memory is local to socket 1 and part is local to socket 2. We also have 2 directories. Access non-local memory takes more time.
Drawbacks
Directory-based coherency is not a panacea and there are a few drawbacks. Without a common bus network many of the previous communications will take a significant number of CPU cycles. In the presence of long and possibly delays such protocols usually require replies to messages, handshakes, to work correctly, and many doubt that it can be made to work efficiently for heavily shared memory applications. Some machines that used directory-based coherency include SGI Origin, as well as the Intel Xeon Phi.
Synchronisation in Parallel Programming - Locks and Barriers
You can access the slides for this lecture here. All the code samples given here can be found online, alongside instructions on how to bring up the proper environment to build and execute them here.
We have seen previously how to program a shared memory processor using threads, execution flows that share a common address space which is very practical for communications. However, the examples we have seen were extremely simple: there was no need for threads to synchronise, apart from the final join operation. There was also no shared data between threads. Today we are going to see mechanisms that make synchronisation and data sharing (especially in write mode) possible.
Synchronisation Mechanisms
In a multithreaded program the threads are rarely completely independent: they need to wait for each other at particular points during the computations, and they need to communicate by sharing data, in particular in write mode (e.g. one thread writes a value in memory that is supposed to be read or updated by another thread). To allow all of this we use software constructs named synchronisation mechanisms. Here we will cover two mechanisms: barriers, that let threads wait for each other, and locks, allowing threads to share data safely. In the next lecture we will cover condition variables, that lets threads signal the occurrence of events to each other.
Barriers
A barrier allows selected threads to meet up at a certain point in the program execution. Upon reaching the barriers, all threads wait until the last one reaches it.
Consider this example:

We have the time flowing horizontally. Thread 2 reaches the barrier first, and it starts waiting for all the other threads to reach that point. Thread 1, then 3 do the same. When thread 4 reaches the barriers, it's the last one, so all threads resume execution.
Barriers are useful in many scenarios. For example with data parallelism, assuming an application is composed of multiple phases or steps. An example could be a first step in which threads first filter the input data, based on some rule, and then in a second step the threads perform some computation on the filtered data. We may want to have a barrier to make sure that the filtering step is finished in all threads before any starts the computing step:

Another use case is when, because of data dependencies, we can parallelise only a subset of a loop's iterations at a time. Recall the example from the lecture on shared memory programming. We can put a barrier in a loop to ensure that all the parallel iterations in one step are computed before going to the next step:

Barriers are very natural when threads are used to implement data parallelism@ we want the whole answer from a given step before proceeding to the next one.
Barrier Example
Let's write a simple C program using barriers, with the POSIX thread library. We will create 2 threads, which behaviour is illustrated below:

Each thread performs some kind of computations (green part). Then each thread reaches the barrier, and prints the fact that it has done so on the standard output. We will make sure that the amount of computations in one thread (thread 1) is much larger than the amount in the other thread (thread 2), so we should see thread 1 printing the fact that it has reached the barrier before thread 2 does so. Once the two threads are at the barrier, they should both resume execution, and they should print out the fact that they are past the barrier approximately at the same time. We'll repeat all that a few time in a loop.
This is the code for the program (you can access and download the full code here).
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
#include <unistd.h>
/* the number of loop iterations: */
#define ITERATIONS 10
/* make sure one thread spins much longer than the other one: */
#define T1_SPIN_AMOUNT 200000000
#define T2_SPIN_AMOUNT (10 * T1_SPIN_AMOUNT)
/* A data structure repreenting each thread: */
typedef struct {
int id; // thread unique id
int spin_amount; // how much time the thread will spin to emulate computations
pthread_barrier_t *barrier; // a pointer to the barrier
} worker;
void *thread_fn(void *data) {
worker *arg = (worker *)data;
int id = arg->id;
int iteration = 0;
while(iteration != ITERATIONS) {
/* busy loop to simulate activity */
for(int i=0; i<arg->spin_amount; i++);
printf("Thread %d done spinning, reached barrier\n", id);
/* sync on the barrier */
int ret = pthread_barrier_wait(arg->barrier);
if(ret != PTHREAD_BARRIER_SERIAL_THREAD && ret != 0) {
perror("pthread_barrier_wait");
exit(-1);
}
printf("Thread %d passed barrier\n", id);
iteration++;
}
pthread_exit(NULL);
}
int main(int argc, char **argv) {
pthread_t t1, t2;
pthread_barrier_t barrier;
worker w1 = {1, T1_SPIN_AMOUNT, &barrier};
worker w2 = {2, T2_SPIN_AMOUNT, &barrier};
if(pthread_barrier_init(&barrier, NULL, 2)) {
perror("pthread_barrier_init");
return -1;
}
if(pthread_create(&t1, NULL, thread_fn, (void *)&w1) ||
pthread_create(&t2, NULL, thread_fn, (void *)&w2)) {
perror("pthread_create");
return -1;
}
if(pthread_join(t1, NULL) || pthread_join(t2, NULL))
perror("phread_join");
return 0;
}
This code declares a data structure worker representing a thread.
It contains an integer identifier id, another integer spin_amount representing the amount of time the thread should spin to emulate the act of doing computations, and a pointer to a pthread_barrier_t data structure representing the barrier the thread will synchronise upon.
The barrier is initialised in the main function with pthread_barrier_init.
Notice the last parameter that indicates the amount of threads that will be waiting on the barrier (2).
An instance of worker is created for each thread in the main function, and the relevant instance is passed as parameter to each thread's function thread_fn.
The threads' function starts by spinning with a for loop.
As previously described the amount of time thread 2 spins is much higher than for thread 1.
The threads meet up at the barrier by both calling pthread_barrier_wait.
Locks: Motivational Example 1
We need locks to protect data that is shared between threads and that can be accessed in write mode by at least 1 thread. Let's motivate why this is very important. Assume that we have a cash machine, which supports various operations and among them cash withdrawal by a client. This is the pseudocode for the withdrawal function:
int withdrawal = get_withdrawal_amount(); /* amount the user is asking to withdraw */
int total = get_total_from_account(); /* total funds in user account */
/* check whether the user has enough funds in her account */
if(total < withdrawal)
abort("Not enough money!");
/* The user has enough money, deduct the withdrawal amount from here total */
total -= withdrawal;
update_total_funds(total);
/* give the money to the user */
spit_out_money(withdrawal);
First the cash machine queries the bank account to get the amount of money in the account. It also gets the amount the user wants to withdraw from some input. The machine then checks that the user has enough money to satisfy the request amount to withdraw. If not it returns an error. If the check passes, the machine compute the new value for the account balance and updates it, then spits out the money.
This all seems fine when there is only one cash machine, but consider what happens when concurrency comes into play, i.e. when we have multiple cash machines.
Let's assume we now have 2 transactions happening approximately at the same time from 2 different cash machines.
This could happen in the case of a shared bank account with multiple credit cards for example.
We assume that there is £105 on the account at first, and that the first transaction is a £100 withdrawal while the second is a £10 withdrawal.
One of these transactions should fail because there is not enough money to satisfy both: 100 + 10 > 105.
A possible scenario is as follows:
- Both threads get the total amount of money in the account in their local variable
total, both get 105. - Both threads perform the balance check against the withdrawal amount, both pass because
100 < 105and10 < 105. - Thread 1 then updates the account balance with
105-100 = 5and spits out £100. - Then thread 2 updates the account, with
105 - 10 = 95and spits out £10.
A total of £110 has been withdrawn, which is superior to the amount of money the account had in the first place. Even better, there is £95 left on the account. We have created free money!
Of course this behaviour is incorrect. It is called a race condition, when shared data (here the account balance) is accessed concurrently in write mode by at least 1 thread (here it is accessed in write mode by both cash machines i.e. threads). We need locks to solve that issue, to protect the shared data against races.
Locks: Motivational Example 2
Let's take a second, low-level example. Consider the i++ statement in a language like java or C. Let's assume that the compiler or the JVM is transforming this statement into the following machine instructions:
1. Load the current value of i from memory and copy it into a register
2. Add one to the value stored into the register
3. Store from the register to memory the new value of i
Let's assume that i is a global variable, accessible from 2 threads running concurrently on 2 different cores.
A possible scenario when the 2 threads execute i++ approximately at the same time is:

In this table time is flowing downwards.
Thread 1 loads i in a register, it's 7, then increments it, it becomes 8, and then stores 8 back in memory.
Next, thread 2 loads i, it's 8, increment it to 9, and stores back 9.
This behaviour is expected and correct.
The issue is that there are other scenarios possible, for example:

Here, both threads load 7 at the same time. Then they increment the local register, it becomes 8 in both cores And then they both store 8 back. This behaviour is not correct: once again we have a race condition because the threads are accessing a shared variable in write mode without proper synchronisation.
Note that this race condition can also very well happen on a single core where the threads' execution would be interlaced.
Critical Sections
The parts of code in a concurrent program where shared data is accessed are called critical sections. In our cash machine example, we can identify the critical section as follows:
int withdrawal = get_withdrawal_amount();
/* critical section starts */
int total = get_total_from_account();
if(total < withdrawal)
abort("Not enough money!");
total -= withdrawal;
update_total_funds(total);
/* critical section ends */
spit_out_money(withdrawal);
For our program to behave correctly without race conditions, the critical sections need to execute:
- Serially, i.e. only a single thread should be able to run a critical section at a time;
- Atomically: when a thread starts to execute a critical section, the thread must first finish executing the critical section in its entirety before another thread can enter the critical section.
A lock is a synchronisation primitive enforcing the serialisation and atomicity of critical sections.
Locks
Each critical section is protected by its own lock. Threads wishing to enter the critical section try to take the lock and:
- A thread attempting to take a free lock will get it.
- Other threads requesting the lock wait until the lock is released by its holder.
Let's see an example: we have two threads running in parallel. They both want to execute a critical section approximately at the same time. Both try to take the lock. Let's assume thread 1 tried slightly before thread 2 and gets the lock, it can then execute the critical section while thread 2 waits:

Once it has finished executing the critical section, thread 1 releases the lock. At that point thread 2 tries to take the lock again, succeeds, and start to execute the critical section:

When thread 2 is done with the critical section, it finally releases the lock:

With the lock, we are ensured that the critical section will always be executed serially (i.e. by 1 thread at a time) and atomically (a thread starting to execute the critical section will finish it before another thread enter it).
Pthreads Mutexes
A commonly used lock offered by the POSIX thread library is the mutex, which stands for mutual exclusion lock.
After it is initialised, its use is simple: just enclose the code corresponding to critical sections between a call to pthread_mutex_lock and pthread_mutex_unlock:
#include <pthread.h>
pthread_mutex_t mutex;
void my_thread_function() {
pthread_mutex_lock(&mutex);
/* critical section here */
pthread_mutex_unlock(&mutex);
}
pthread_mutex_lock is used to attempt to take the lock.
If the lock is free the function will return immediately and the thread will start to execute the critical section.
If the lock is not free, i.e. another thread is currently holding it, the calling thread will be put to sleep until the lock becomes free: the calling thread will then take the lock, pthread_mutex_lock will return, and the thread can start to run the critical section.
pthread_mutex_unlock is called by a thread holding a lock to release it.
The function returns immediately.
Lock Usage Example
To present an example of lock usage, we are going to define the following data structure named bounded buffer:

It's a fixed size buffer in which can be accessed concurrently by multiple threads. It's also a FIFO producer-consumer buffer: threads can deposit data in the buffer, and thread can also extract data in a first in first out fashion.
We are going to write a program that implements such a bounded buffer and executes 2 threads that access the buffer concurrently: one thread will continuously insert elements in the buffer, and the other will continuously extract elements from it.
The full code for our program is available here.
Bounded Buffer Declaration and Initialisation. This is the code defining the data structure representing the bounded buffer, as well as its initialisation/destruction functions.
typedef struct {
int *buffer; // the buffer
int max_elements; // size of the buffer
int in_index; // index of the next free slot
int out_index; // index of the next message to extract
int count; // number of used slots
pthread_mutex_t lock; // lock protecting the buffer
} bounded_buffer;
int init_bounded_buffer(bounded_buffer *b, int size) {
b->buffer = malloc(size * sizeof(int));
if(!b->buffer)
return -1;
b->max_elements = size;
b->in_index = 0;
b->out_index = 0;
b->count = 0;
pthread_mutex_init(&b->lock, NULL);
return 0;
}
void destroy_bounded_buffer(bounded_buffer *b) {
free(b->buffer);
}
The data structure has a pointer towards a buffer that represent the buffer's content, a maximum size max_elements, two indexes indicating where to insert the next element in the buffer (in_index) and where to extract the next element from the buffer (out_index).
Another member of the data structure count keep track of the number of slots used in the buffer.
Finally, we have a lock that will protect the accesses to the buffer.
Note the type, pthread_mutex_t.
The initialisation function allocates memory for the buffer and sets the different members of the data structure to their initial value.
The lock is initialised with pthread_mutex_init.
The destruction function simply free the memory allocated for the buffer.
Thread Data Structure. We will use the following data structure to represent each thread:
typedef struct {
int iterations;
bounded_buffer *bb;
} worker;
iterations represents the number of elements the thread will insert/extract from the buffer, and bb is a pointer to the buffer.
Similarly to our example with the barrier, an instance of this data structure will be passed as parameter to each thread's function.
Producer Thread. The producer thread will run the following code:
void deposit(bounded_buffer *b, int message) {
pthread_mutex_lock(&b->lock);
int full = (b->count == b->max_elements);
while(full) {
pthread_mutex_unlock(&b->lock);
usleep(100);
pthread_mutex_lock(&b->lock);
full = (b->count == b->max_elements);
}
b->buffer[b->in_index] = message;
b->in_index = (b->in_index + 1) % b->max_elements;
b->count++;
pthread_mutex_unlock(&b->lock);
}
void *deposit_thread_fn(void *data) {
worker *w = (worker *)data;
for(int i=0; i<w->iterations; i++) {
deposit(w->bb, i);
printf("[deposit thread] put %d\n", i);
}
pthread_exit(NULL);
}
The thread runs the deposit_thread_fn functions which calls deposit in a loop.
deposit is going to access the buffer, so it starts by taking the lock.
Before depositing anything in the buffer, we need to check if it is full.
If it is the case, we need to wait for the buffer to become non-full.
We can't hold the lock doing so, that would prevent the consumer thread from removing elements from the buffer.
So we release the lock, sleep a bit with usleep, take the lock again, and check again if the buffer is full or not.
All of that is done in a loop which we exit once we know the buffer is indeed non-full, with the lock being held.
After that the insertion is made and the lock is released.
Consumer Thread. The consumer thread runs the following code.
int extract(bounded_buffer *b) {
pthread_mutex_lock(&b->lock);
int empty = !(b->count);
while(empty) {
pthread_mutex_unlock(&b->lock);
usleep(100);
pthread_mutex_lock(&b->lock);
empty = !(b->count);
}
int message = b->buffer[b->out_index];
b->out_index = (b->out_index + 1) % b->max_elements;
b->count--;
pthread_mutex_unlock(&b->lock);
return message;
}
void *extract_thread_fn(void *data) {
worker *w = (worker *)data;
for(int i=0; i<w->iterations; i++) {
int x = extract(w->bb);
printf("[extract thread] got %d\n", x);
}
pthread_exit(NULL);
}
The consumer thread runs the extract_thread_fn function, which calls extract in a loop.
extract starts by taking the lock, and checking if the buffer is empty: if it is the case there is nothing to extract, and it must wait.
This is done in a loop in which the lock is released, and thread sleep with usleep to give the opportunity to the producer thread to insert one or more elements in the buffer.
Once it is certain that the buffer is not empty, we exit that loop with the lock held and perform the extraction, before releasing the lock.
What Happens if We Omit the Locks
Without the locks, the program may seem to behave normally on small examples, especially when the number of threads is low or when the frequency of access to shared data is low. This is quite bad because it's hiding race conditions. Indeed, without the locks in reality many instances of incorrect program behaviour can (and will, given enough time) occur:
If two threads call deposit at the same time, they may write to the same slot in the buffer, one value being lost:



When the threads depositing concurrently increment the index for the next insertion, it can either be incremented only by one assuming a similar scenario as for the buffer content: in that case we just lose one of the inserted values:

However, they can also increment the index twice and assuming we got the content overwrite problem we have a slot containing garbage value:

We can have similar issues in case of unprotected concurrent calls to deposit.
And of course, additional problems occur in case of unprotected concurrent calls to deposit and extract at the same time, for example as both threads update the number of used slots we may loose consistency for that value.
Races may manifest in a number of ways in the program behaviour. Sometimes the program can even seem to work fine. As a result concurrency issues can be extremely hard to reproduce and debug in large program, and it's important to get one's locking strategy right from the start.
Synchronisation in Parallel Programming - Condition Variables
You can access the slides for this lecture here. All the code samples given here can be found online, alongside instructions on how to bring up the proper environment to build and execute them here.
We have seen previously two synchronisation mechanisms that are barriers as well as locks. Here we will present third one, condition variables.
Event Signalling
Recall our bounded buffer example from the lecture on locks, in which producer/consumer threads may need to wait for the buffer to become non-full/non-empty. For example a thread attempting to extract from an empty buffer needs to wait for it to become non-empty, and same thing for a thread attempting to deposit in a buffer that is full There are two intuitive solutions to implement that wait. The one we saw previously involves sleeping in a loop until the condition we wait for becomes true, for example a producer thread waits until the buffer becomes non-full as follows:
while(full) {
pthread_mutex_unlock(&b->lock);
usleep(100);
pthread_mutex_lock(&b->lock);
full = (b->count == b->max_elements);
}
Another approach is busy waiting: we get rid of the sleep and the thread will keep trying non-stop until the condition becomes true:
while(full) {
pthread_mutex_unlock(&b->lock);
/* busy wait */
pthread_mutex_lock(&b->lock);
full = (b->count == b->max_elements);
}
Note that in that case we still need to unlock the buffer's lock to give a chance to other threads to access the queue and make the condition we wait for become true: without this other threads will starve.
Both solutions are suboptimal: sleeping for an arbitrary time may lead to long wakeup latencies, and busy waiting wastes a lot of CPU cycles because the threads keeps trying non-stop.
Let's see an example with a thread trying to deposit in a full buffer. With a sleep-based method things look as follows:

Thread 2 is trying to deposit in the buffer, but the buffer is full. So at regular intervals, here every 100 microseconds, thread 2 going to check if the buffer is still full and if so it will sleep for another 100 microseconds. The good thing here is that during all that time, something else can use that CPU core. Imaging now that in the meantime another thread, thread 1, extracts something from the queue. Once the execution of thread 1's critical section is done, thread 2 could actually perform its deposit operation right away because the buffer is not full anymore. However, thread 2 is in the middle of its 100 microseconds sleep, so it will have to wait until the end of that sleep operation to be able to start making progress. This is why sleeping may lead to long wakeup delays.
Let's now examine the same scenario, but with a busy-waiting approach:

Because it keeps checking when the buffer becomes non-full, thread 2 has a much shorter wakeup delay compared to the sleeping solution. However, during the entire busy waiting period, thread 2 monopolises the CPU and nothing else can use that core: busy waiting wastes CPU cycles.
Condition Variables
A condition variable is a synchronisation primitive that can address this problem. It is used for event signalling between threads: it allows to signal threads that sleep waiting for a conjunction of two events:
- a lock becoming free, and
- an arbitrary condition becoming true, for example the buffer becoming non-full or non-empty.
One may wonder why is there the condition regarding the lock in addition to the arbitrary event. The reason is first that the implementation requires it, the condition variable needs to be itself protected from concurrent accesses with the lock. Second, such a primitive is generally used to synchronise access to shared data structures which is something that itself requires a lock.
With condition variables you get the best of both worlds: not only a waiting thread wakes up with a very low latency, but it also waits by sleeping so it does not hang the CPU:

Applying Condition Variables to Our Example
How can we use a condition variable with our bounded buffer example? Assume a thread wants to deposit in a buffer that is full:

We are going to use a condition variable to indicate when the buffer becomes non-full. With the buffer's lock held, the thread will call a function to sleep on that condition variable:

Later say another thread extracts an element from the buffer. If the extracting thread realises it made the buffer non-full, it calls a function to signal that the condition relative to the condition variable has happened:

When the extracting thread releases the lock, that will trigger the awakening of the thread waiting, which will grab the lock and finally perform its deposit:

We similarly use a condition variable to represent the buffer becoming non-empty. When a thread attempts to deposit an element into an empty buffers it waits on that condition variable. Another thread depositing something and realising it makes the buffer non-empty will then signal that variable, waking up the deposit thread, so it can perform its operation.

Condition Variables with the POSIX Thread Library
The multiple steps we just presented actually translate to something quite simple in the code because the condition variable's implementation takes care of a lot of things under the hood. Let's see how we the code looks like for our bounded buffer example, this time using a condition variable to signal the events corresponding to 1) the buffer becoming non-full and 2) the buffer becoming non-empty. We will only present here the subset of the program that is relevant to the use of condition variables, but you can access the entire program here.
Bounded Buffer Representation and Initialisation.
The data structure representing the bounded buffer is updated to include 2 condition variable: one to notify threads waiting on full buffer (condfull), and the other to notify threads waiting on empty buffer (condempty):
typedef struct {
int *buffer; // the buffer
int max_elements; // size of the buffer
int in_index; // index of the next free slot
int out_index; // index of the next message to extract
int count; // number of used slots
pthread_mutex_t lock; // lock protecting the buffer
pthread_cond_t condfull; // condvar to notify threads waiting on full buffer
pthread_cond_t condempty; // condvar to notify threads waiting on empty buffer
} bounded_buffer;
The bounded buffer initialisation code is updated with the initialisation of both condition variables:
int init_bounded_buffer(bounded_buffer *b, int size) {
b->buffer = malloc(size * sizeof(int));
if(!b->buffer)
return -1;
b->max_elements = size;
b->in_index = 0;
b->out_index = 0;
b->count = 0;
/* Initialize mutex and both condition variables */
if(pthread_mutex_init(&b->lock, NULL) || pthread_cond_init(&b->condfull, NULL) ||
pthread_cond_init(&b->condempty, NULL))
return -1;
return 0;
}
Condition variable initialisation is done with pthread_cond_init.
Note the type of the condition variable, pthread_cond_t.
The function deposit is updated as follows:
void deposit(bounded_buffer *b, int message) {
pthread_mutex_lock(&b->lock);
int full = (b->count == b->max_elements);
while(full) {
/* Buffer is full, use the condition variable to wait until it becomes
* non-full. */
if(pthread_cond_wait(&b->condfull, &b->lock)) {
perror("pthread_cond_wait");
pthread_exit(NULL);
}
/* pthread_cond_wait returns (with the lock held) when the buffer
* becomes non-full, but the buffer may have been accessed by another
* thread in the meantime so we need to re-check and cotninue waiting
* if needed. */
full = (b->count == b->max_elements);
}
b->buffer[b->in_index] = message;
b->in_index = (b->in_index + 1) % b->max_elements;
/* If the buffer was empty, signal a waiting thread. This works only if
* max 2 threads access the buffer concurrently. For more, broadcast should
* be used instead of signal. More about that in the next lecture (the one
* entitled "More about Locks"). */
if(b->count++ == 0)
if(pthread_cond_signal(&b->condempty)) {
perror("pthread_cond_signal");
pthread_exit(NULL);
}
pthread_mutex_unlock(&b->lock);
}
When deposit detects that the buffer is full, it waits on the condition variable until it becomes non-full.
That wait is achieved by calling pthread_cond_wait, which takes a pointer to the condition variable to wait upon, as well as a pointer to the corresponding lock.
It should be called with the lock held.
The implementation of pthread_cond_wait operation will take care of releasing the lock and putting the thread to sleep,
On the other side, an extracting thread realising that the buffer becomes non-full will signal that condition variable, and the waiting thread will wake up, the implementation of pthread_cond_wait will take care of taking the lock again before returning.
Once it returns, although the thread hold the lock, it is still needed to check the condition, before another thread could have been able to deposit an element in the meantime,
If the buffer is still non-full, the thread can proceed with the deposit.
Otherwise, it starts the wait operation again.
deposit also takes care of signalling potential threads waiting on the other condition variable (condempty) that the buffer has become non-empty.
After its insertion is done, it checks that the amount of elements of the buffer is equals to 0 and if so, it signals the condition variable with pthread_cond_signal.
The extract function looks similar:
int extract(bounded_buffer *b) {
pthread_mutex_lock(&b->lock);
int empty = !(b->count);
while(empty) {
/* Buffer is empty, wait until it is not the case using the condition
* variable. */
if(pthread_cond_wait(&b->condempty, &b->lock)) {
perror("pthread_cond_wait");
pthread_exit(NULL);
}
empty = !(b->count);
}
int message = b->buffer[b->out_index];
b->out_index = (b->out_index + 1) % b->max_elements;
/* If the buffer becomes non-full, signal a potential deposit thread waiting
* for that. */
if(b->count-- == b->max_elements) {
if(pthread_cond_signal(&b->condfull)) {
perror("pthread_cond_signal");
pthread_exit(NULL);
}
}
pthread_mutex_unlock(&b->lock);
return message;
}
A thread attempting to extract from an empty buffer will wait on it using the corresponding condition variable and pthread_cond_wait.
Upon extracting an element, a thread will also signal the other condition variable that the buffer has become non-full, which will wake up any deposit thread waiting.
More about Locks
You can access the slides for this lecture here. All the code samples given here can be found online, alongside instructions on how to bring up the proper environment to build and execute them here.
We have seen previously that locks are practical, and in many situations indispensable, to protect critical sections. However, their use is not without dangers. This is what we will cover here, along with a bit of additional information about locks.
Dangers with Locks
One of the common issues with lock is the deadlock. It happens when, due to improper use of locks, the program is stuck waiting indefinitely, trying to take a lock it will never acquire. We can illustrate it with this picture:

Looking at the center part, we can observe that:
- The white truck is stuck because the white car in front of it cannot move;
- The white car in question cannot move because the gray car in front of it is stuck;
- And the gray car is stuck because the white truck cannot move.
The entire situation is blocked!
As soon as a program uses more than one lock, it opens the possibility for deadlocks if the lock/unlock operations are not made in the proper way. Let's take an example:
typedef struct {
double balance;
pthread_mutex_t lock;
} account;
void initialise_account(account *a, double balance) {
a->balance = balance;
pthread_mutex_init(&a->lock, NULL); // return value checks omitted for brevity
}
void transfer(account *from, account *to, double amount) {
if(from == to)
return; // can't take a standard lock twice, avoid account transfer to self
pthread_mutex_lock(&from->lock);
pthread_mutex_lock(&to->lock);
if(from->balance >= amount) {
from->balance -= amount;
to->balance += amount;
}
pthread_mutex_unlock(&to->lock);
pthread_mutex_unlock(&from->lock);
}
We have a data structure account representing a bank account, with a balance, and an associated lock protecting the balance from concurrent access.
initialise_account sets a starting balance in the account and initialises the lock.
We also have a function, transfer, that moves a given amount of money from one account to another.
This function is supposed to be called from multithreaded code, so it will access the locks relative to each account.
transfer first checks that from and to do not point to the same account, because a standard pthread mutex cannot be taken twice (that would result in undefined behaviour).
Next we first take the lock for the from account, then the lock for the to account.
We perform the transaction if there is enough money, then release the locks in order.
In order to try out how this code behaves at runtime, one can find the full program is available here. At runtime, there is a non-negligible chance that this program hangs indefinitely, because it contains a deadlock. Note that the deadlock may take multiple runs to occur, because like most concurrency bugs, it happens in specific scheduling conditions.
Dangers with Locks
How does this deadlock happen? Here's a scenario that leads to it:

We have two threads calling the transfer method approximately at the same time.
Thread 1 calls transfer from account a to account b and the other thread calls transfer from account b to account a.
Thread 1 gets a's lock first, then it tries to get b's lock.
But in the meantime thread 2 took b's lock and is now trying to lock a.
No thread can continue, and the system is stuck, it's a deadlock.
One possible solution to that issue is to give each account a unique identifier that can be used to establish an ordering relationship between accounts. We use this to sort the objects to lock so that, when given 2 accounts, all threads will always lock them in the same order, avoiding the deadlock:
typedef struct {
int id; // unique integer id, used to sort accounts
double balance;
pthread_mutex_t lock;
} account;
void transfer(account *from, account *to, double amount) {
if(from == to) return;
pthread_mutex_t *lock1 = &from->lock, *lock2 = &to->lock;
if(from->id < to->id) { // always lock the accounts in the same order
lock1 = &to->lock;
lock2 = &from->lock;
}
pthread_mutex_lock(lock1);
pthread_mutex_lock(lock2);
if(from->balance >= amount) {
from->balance -= amount;
to->balance += amount;
}
pthread_mutex_unlock(lock2);
pthread_mutex_unlock(lock1);
}
You can access the full version of this program here.
In this example we use a simple unique integer id for each account.
In the transfer function we use the id to sort the accounts.
Establishing such an ordering allows us to always take the locks in the same order, so when a thread calls transfer from a to b while another calls transfer from b to a, both will lock the accounts in the same order and only one can obtain both locks at once.
The Lost Wake-up Issue
Another issue with badly handled synchronisation is the lost wake-up. It happens when the programmer mistakenly uses conditions variables. Let's take an example with the bounded buffer code from last lecture.
Something that can happen is the following scenario. Assume we have an empty bounded buffer and 4 threads, A/B/C/D. Thread A tries to extract something from the empty queue and waits. Thread B tries the same, and waits:

Next thread C deposits something in the empty queue, so it signals a waiting thread. Let's assume it is thread A:

At the same time thread D also deposits in the queue, which is non-empty, so there is no need to signal a waiter:

Thread A wakes up, and extracts an element from the queue. And in the end, B is never awoken, even though the queue is not empty:

- In this scenario, the fix would be to use the
pthread_cond_broadcast()function to signal all waiters when someone deposits in an empty queue, thanpthread_cond_signal(), that signals only a single thread.
Locking Granularity
The granularity of locking defines how large are the chucks of code protected with a single lock. It is an important design choice when developing a parallel program. Large blocks of code protected by locks generally access a mix of shared and non-shared data. In that case we talk about coarse-grained locking:
lock();
/* access a mix of shared and unshared data */
unlock();
Because locking serialises the entirety of the protected code, coarse-grained locking limits parallelism. On the other hand one can have many lock operations, each protecting small quantities of code, this is fine-grained locking:
lock();
/* access shared data */
unlock();
/* access non-shared data */
lock();
/* access shared data */
unlock();
Fine-grained locking increases parallelism. However, it may lead to a high overhead from obtaining and releasing many locks. The program is also harder to write. So it really is a trade-off: for example when updating certain elements in an array, we can either lock the entire array (coarse-grained locking), or we could lock only the individual element(s) being changed (fine-grained locking).
Reentrant Lock
By default, a thread locking a lock it already holds results in undefined behaviour.
Let's go back to our example and assume that transfer does not check if from and to don't point to the same account:
void transfer(account *from, account *to, double amount) {
/* no check if from == to */
// BUGGY when from == to if lock is not reentrant
pthread_mutex_lock(from->lock);
pthread_mutex_lock(to->lock);
if(from->balance >= amount) {
from->balance -= amount;
to->balance += amount;
}
/* ... */
}
Assuming the thread calls this version of transfer with the same account by pointed by the from and to parameters, it will then take the account's lock once, then attempt to take it a second time while already holding it.
On a standard lock this results in undefined behaviour, it's a bug.
This is because by default pthread mutexes are not reentrant.
A reentrant lock is a lock that can be taken by a thread that already holds it.
We can update our example program to use reentrant lock:
void initialize_account(account *a, int id, double balance) {
a->id = id;
a->balance = balance;
pthread_mutexattr_t attr;
if(pthread_mutexattr_init(&attr))
errx(-1, "pthread_mutexattr_init");
if(pthread_mutexattr_settype(&attr, PTHREAD_MUTEX_RECURSIVE))
errx(-1, "pthread_mutexattr_settype");
if(pthread_mutex_init(&a->lock, &attr))
errx(-1, "pthread_mutex_init");
}
The full program's code is available here.
We can specify that a mutex is reentrant by using the second parameter of the pthread_mutex_init function.
It takes a pointer to a data structure of type pthread_mutexattr_t, that allows to set various attributes to a created mutex.
It is initialised with pthread_mutexattr_init, and we indicate the fact that we want to set the reentrant (PTHREAD_MUTEX_RECURSIVE) attribute with pthread_mutexattr_settype.
Other Lock Types
In addition to the mutex, pthread gives you access to other lock types. While the mutex can only be held by a single thread, even if it is reentrant, a semaphore is a lock that can be held by several threads at once. It is useful for example to arbitrate access to a set of resources that are in limited number.
Further we have the spinlock. Contrary to a mutex that, when it cannot take a lock, has the operating system put the calling thread to sleep, the spinlock uses busy waiting. In other words it spins, meaning it monopolises the CPU in a loop until it can take the lock. This wastes CPU cycles but gives a better wakeup latency compared to the mutex.
And finally we have read-write locks, they allow concurrent reads, but serialise write operations. We will develop a bit on these in the future lecture regarding operating systems.
For more information about how to use these locks, see the Oracle Multithreaded Programming Guide (chapter 4).
Hardware Support for Synchronisation
You can access the slides for this lecture here.
We have seen how synchronisation is crucial to parallel programming. Here we are going to see what are the hardware mechanisms on modern CPUs that are used to implement synchronisation mechanisms such as locks.
Implementing Synchronisation
When programming a multithreaded application that relies on shared memory for communication between threads, synchronisation mechanisms are required to protect critical section and ensure they execute without races. There are multiple mechanisms (locks, barriers, etc.), but they are all closely related and most can be built on top of a common basic set of operations.
We have also seen that source code statement such as i++ can be translated by the compiler into several instructions: they are not executed atomically, so they are unfit to help us implement synchronisation mechanisms.
If we implement a synchronisation primitive, for example a lock, we need to make sure that its access primitives (here lock and unlock operations) are executed atomically, otherwise the lock itself, which by nature is a form of shared data, will be subject to race conditions.
Intuitively this seems difficult.
Indeed, if we consider say the lock operation, it involves 2 memory accesses: 1) checking if the lock is available (reading a memory slot) and if so taking the lock (writing in the memory slot).
How can these 2 memory operation be realised atomically?
To achieve that we need hardware support.
We will illustrate how synchronisation primitives can be built on top of the relevant hardware mechanisms by presenting the implementation of the simplest lock possible: a binary semaphore, in a processor with a snoopy cache. This lock can be held by at most 1 thread, and waiting threads use busy-waiting.
Example: Binary Semaphore
Our binary semaphore is a single shared boolean variable S in memory, and the status of the lock (free/held) depends on its value:
- When
S == 0the protected resource is free, i.e. the lock is ready to be taken. - When
S == 1the resource is busy and the lock is taken.
As mentioned earlier, operations on the semaphore should be atomic. These operations are:
wait(S): wait untilS != 1then setS = 1(i.e. take the lock)signal(S): setS = 0(i.e. release the lock)
We have the lock and unlock operation.
Lock can also be called wait.
It consists in waiting for the lock to be free, i.e. for the variable to be different from 1, then setting it to 1 to indicate that we take the lock.
Once again this should be atomic, if two threads see that the lock is free and sets the variable at the same time, things won't work.
Then we have the unlock operation, called signal: we simply release the lock by setting the variable to 0.
This operation should also be atomic, a priori that is not an issue because it can be translated to a simple store, but even in that case we need to be careful: for example if the variable is on 64 bits and we are on a 32-bit CPU, the compiler may translate S=0 into two load operations, making it non-atomic.
Semaphore Usage to Protect Critical Sections
Recall that critical sections are the code sections where shared resources are manipulated, and that we want them to be executed in a serial fashion, i.e by 1 thread at a time, and atomically, i.e. when 1 thread starts to execute the critical section, it should finish before another thread can enter that critical section: this is what we want to achieve with the lock.
The lock is operated as follows.
We initialise the lock to 0, i.e. ready to be taken.
A thread calls wait (i.e. tries to take the lock) before the critical section.
When several threads call wait at the same time, only one thread will atomically succeed and set it to 1, the others will (busy) wait on the lock for it to go back to 0.
When the thread holding the lock is done with its critical section, it releases it by calling signal, which sets the value of the lock back to 0, and if there are waiting threads one of them will then be able to take the lock.
This ensures that the code protected by our semaphore is executed serially and atomically:

Atomicity Needed
How to implement wait?
A naive implementation in C would be something like that:
// naive implementation in C:
while(S == 1);
S = 1;
While the semaphore value is 1 we spin waiting, and once it reaches 0 we set it to 1 to indicate that we got the lock. The problem is that if we look at the machine code generated by the compiler from this source code, we see something like that (in pseudo-assembly):
// address of `S` in `%r2`
loop: ldr %r1, %r2 // load the semaphore value
cmp %r1, $1 // check if it is equal to 1
beq loop // if so lock is already taken, branch to try again i.e. spin
str $1, %r2 // lock is free, take it
Our naive attempt at implementing wait compiles into the following operations.
We assume that the address of the lock variable S is in %r2.
We read the value of S it in a register %r1 with a load operation.
Then we compare it to 1 and if it is equal to 1 it means the lock is taken, so we need to wait: the code branches back to try again.
Otherwise, the lock is free, and we use a store to set the value of S to 1 to indicate we have taken the lock.
As one can observe wait is not atomic at the machine code level and requires several instructions, including two memory accesses (reading/storing the value of S) to be executed.
As atomicity is not guaranteed, with e.g. 2 threads accessing the semaphore, the following scenario can occur:

First thread 1 does the load and thread 2 does the same right after.
Both do the comparison, see that it's not 1 so they don't branch, and then they both do the store.
Both threads have taken the lock, which of course is not correct behaviour.
Atomic Instructions
So it is clear that wait must be atomic, i.e. the entire lock taking operation must be done by a single thread at once. This requires special instructions supported by the hardware, called atomic instructions. These will realise at once all the operations required for the lock taking operation, without the possibility to be interrupted in the middle, and with the guarantee that no other core in the system will access memory at the same time.
Implementing synchronisation primitives like wait() with these atomic instructions involves a compromise between complexity and performance.
There are also various way for the hardware to implement these atomic instructions, with different performance/complexity tradeoffs.
Also note that variable S may be cached, and the desired atomic behaviour might require coherence operations in the cache.
Atomic Test-And-Set Instruction
An example of atomic instruction is test-and-set. It is present in many CPUs (e.g. Motorola 68K). It takes a register containing an address at parameter and performs, atomically, the following things:
- It checks that the memory slot addressed by the register contains
0, and if it is the case, it sets the content of that memory slot to1as well as the CPU zero flag. - If the memory slot was not 0, the zero flag is cleared.
Here is an example of usage in pseudo assembly, we just execute test and set (tas) on a memory slot which address is present in the register %r2:
tas %r2
If memory location addressed by %r2 contains 0, tas switches its content to 1 and set the CPU zero flag, otherwise it clears the zero flag and does not update memory.
The behaviour of this instruction is atomic: it cannot be interrupted, and no other core can modify what is pointed by %r2 in memory while the tas runs.
Let's illustrate an example.
Say we want to do a test and set on address 0x42.
We place that address in a register, say %r2.
And we execute tas %r2.
Now assume address 0x42 contains 0.
Test and set will then switch it to 1, and will also set the zero flag of the core to 1:

If instead before the test and set address 0x42 contains something else than 0, for example 1, test and set won't touch it and will clear the zero flag on the core:

Our Semaphore with tas
We can implement our semaphore with the test and set atomic instruction as follows.
We have our lock S in memory at a given address,
This is the wait operation, i.e. trying to take the lock:
// Address of S in %r2
// Loops (i.e. wait) while [%r2] != 0
loop: tas %r2
bnz loop // branch if zero flag not set
We have the address of our lock in %r2.
We try a test and set, and if the lock's value is 1, we consider that the lock is not free
In that case the test and set will not modify the lock's value and will clear the zero flag.
So the bnz (branch if not zero) will go back to the loop label, and we try again, i.e. we spin, until the lock is free.
When the lock is free its value will be 0 so test and set will set it to 1, we won't branch, and we'll continue with the lock held.
This is the implementation of the lock release operation, i.e. signal:
// We assume that basic store operations
// are atomic
// Address of S in %r2
str $0, %r2
Here we assume here that the store assembly instruction is atomic.
Releasing the lock simply consist in setting the value of the lock to 0 to indicate that it is free to take.
What About the Cache?
If we assume a system with no cache the semaphore operations with test and set are pretty straightforward: S is a single shared variable in memory, and it is locked with test and set and released with a simple store.
One thing to note is that atomic operations such as test and set are classified as read-modify-write (RMW).
These are the three operations they do atomically, for example test and set reads a memory slot into a register and may modify that value in the register and write it back to memory.
For this to be done atomically the CPU needs to prevent access to memory from the other cores during the execution of the RMW operation by a core.
However, processors do have caches, and by definition S is shared: this is the fundamental purpose of a semaphore.
Multiple cores are therefore likely to end up with a copy of S in their cache.
Test-and-Set and the Cache
So for all the operations realised by a RMW instruction to be atomic, the core needs to lock the snoopy bus for the duration of the atomic instruction.
This basically prevents all the other cores to do a write in case they would try to write on the shared variable.
Of course this affects performance.
Further, a particular observation is that test and set is a read only operation when the test fails (when the instruction reads something else than 0), and in that case this locking of the bus, slowing down cache coherence traffic from other cores, was somehow wasted.
We can avoid this issue with a trick, a particular way to use test and set, called test and test and set.
Test-and-test-and-set
Before looking at assembly, let's see in pseudocode how using test-and-test-and-set for our semaphore taking operation wait looks like that:
do {
while(test(S) == 1); // traditional load
} while (test-and-set(S)); // test-and-set
We have our loop, and in the loop body we spin as long as the lock seems to be taken. For this we use a normal test, which is cheap because it does not lock the snoopy bus. And only when the lock seem to be available, i.e. when the test sees that the variable is 0, we do a costly test and set. This test and set has good chances to succeed. And if it does not, we go back to spinning with a simple test.
In assembly, wait using test-and-test-and-set looks like that:
// address of S in %r2
loop: ldr %r1, %r2 // standard, non atomic (i.e. cheap) load
cmp %r1, $1
beq loop // lock taken
tas %r2 // lock seems free, try to take it with a costly tas
bnz loop // failed to take the lock, try again
]
We load the address of the semaphore variable in %r1.
We do the simple test, if S is 1 the lock is not available, and we branch back to spin.
If S is not 1, the locks appears to be free, we can try to take it with an atomic test and set.
If the test and set does not succeed, another core beat us to it, and we branch back to spin.
The waiting loop is only executing a normal load operation ldr most of the time, which is internal to the core and its cache, so no bus cycles are wasted.
Other Synchronisation Primitives
There are other types of atomic instructions implemented in modern CPUs.
Fetch-and-add returns the value of a memory location and increments it atomically:
// in pseudocode
fetch_and_add(addr, incr) {
old_val = *addr;
*addr += incr;
return old_val;
}
Compare-and-swap compares the value of a memory location with a value (in a register) and swaps in another value (in a register) if they are equal:
// in pseudocode
compare_and_swap(addr, comp, new_val) {
if(*addr != comp)
return false;
*addr = new_val;
return true;
}
All these instructions are read-modify-write (RMW), with the need to lock the snoopy bus during their execution. However, RMW instructions are not really desirable with all CPU designs: their nature does not fit well with simple RISC pipelines, where RMW in effect a CISC instruction requiring a read, a test and a write. In the next lecture we will see another form of hardware mechanism used to implement synchronisation primitives, more suitable to RISC architectures: load-linked and store-conditional.
Lock-Free Data Structures
Beyond locks, atomic instructions can be used to implement so called lock-free data structures. These are data structures such as stacks or queues that can be accessed concurrently without the need for locks, but using accessors relying directly on atomic instructions. Such data structures are generally quite difficult to implement for several reasons. First, updating their state requires generally more than the single memory store operation done by RMW instructions: for example to insert a new element n in a queue, one generally need to update the pointer from the previous element in the queue to point to n, and to update the head pointer of the queue to point to n too. Second, in languages without automated memory management (C/C++), with lock-free data structures implementation it is hard to know when a member of the data structure can be freed (a thread may still hold a reference to it). These problems can be circumvented, although it leads to implementations that are complex and hard to reason with. The benefit is that accesses to lock-free data structures can be faster than with lock-based data structures.
You can check out a couple of implementation examples of a lock-free queue:
- In Java, the implementation is not to complex because Java has a GC (still things are not entirely trivial).
- In C, things are more complicated for the reasons listed above.
For more information see this web page as well as The Art of Multiprocessor Programming chapters 10 and 11.
Load-Linked and Store-Conditional
You can access the slides for this lecture here.
We have seen that read-modify-write atomic instructions could implement synchronisation, but that their complexity made them inefficient in certain situations. Here we are going to see a couple of simple hardware instructions working together to implement a synchronisation mechanism: load-linked and store-conditional (LL/SC).
LL/SC is a synchronisation mechanism used in modern RISC processors such as ARM, PowerPC, RISC-V, and so on. It relies on 2 separate instructions that slightly differ from traditional loads and stores: load-linked and store-conditional. They have additional effects on processor state, which allows them to act atomically as a pair while avoiding holding the cache coherence bus until completion.
Load-Linked
Let's first see load linked. It takes two registers as parameters:
ldl %r1, %r2
Similar to a traditional load instruction, load linked loads register %r1 with the value from memory at the address in register %r2.
It also sets a special load linked flag on the core which executes it.
And it records the address placed in %r2 inside a register on the core, named locked address register.
The core holds some state related to this load link instruction.
Store-Conditional
Store conditional also takes two parameters:
stc %r1, %r2
The instruction tries to store the value in %r1 into memory, at the address in register %r2.
Different from a traditional store, it only succeeds if the load linked flag is set.
After the store conditional is executed, the value of the load linked flag is returned in %r1.
This value represents whether or not the store was successful.
After the operation the load-linked flag is cleared.
The Load-Linked Flag
The reason to be for the load linked flag is to indicate if the memory slot accessed has been modified by another core between the load-linked and the store-conditional: on that slot: after a load-linked, the load linked flag is cleared if another core writes to the locked address. This is detected by comparison with the "locked address register". The processor snoops the memory address bus to detect this.
Let's take an example, we have the memory, and two cores each with the LL/SC flag:

Core 1 does a load link from address 12 and its flag is set:

But before core 1 does his store conditional, core 2 writes to address 12. This automatically clears the flag on core 1:

The subsequent store-conditional from core 1 will fail:

Other events clearing the flag include context switches and interruptions. These change the control flow intended by the programmer. Overall the load linked flag allows to be sure that a LL/SC pair is executed atomically or not with respect to the locked address.
Our Semaphore with LL/SC
Let's have a look at how we can implement a semaphore with LL/SC in assembly:
/* Address of the lock in %r2 */
loop: ldl %r1, %r2
comp $0, %r1 /* S == 0 (semaphore already taken)? */
beq loop /* if so, try again */
mov $0, %r1 /* looks like it's free, prepare to take the semaphore */
stc %r1, %r2 /* Try to take it */
cmp $1, %r1 /* Did the write succeed? */
bne loop /* If not, someone beat us to it... try again */
/* critical section here... */
st $1, %r2 /* release the semaphore with a simple store */
The lock is a simple byte in memory, when it is 1 the semaphore is free, when it is 0 the semaphore is taken.
We assume the address of the lock is stored in %r2.
We start by doing a load link ldl from this address into %r1.
If the value is 0 the semaphore is taken, so we branch back to the beginning of the loop.
If it's 1 the semaphore seems to be free, so the code must now try to take it.
We put the constant 0 into %r1 and then try to store this value into the byte representing the lock, with a store conditional in the address that is in %r2.
Now remember that store conditional may fail if someone else wrote to the lock byte between the moment we checked its value with the load-linked.
So we check if our store conditional succeeded by checking if %r1 contains 1.
If not, someone beat us to the lock, and we have to try again, we branch back.
If we got the lock, we execute the critical section, and release the lock with a simple store.
The code highlighted below with the * prefix executes atomically with respect to the memory location pointed by %r2, between the moment the thread thinks that the lock is free, and the moment it actually takes the lock:
/* Address of the lock in %r2 */
loop: ldl %r1, %r2
* comp $0, %r1 /* S == 0 (semaphore already taken)? */
* beq loop /* if so, try again */
* mov $0, %r1 /* looks like it's free, prepare to take the semaphore */
stc %r1, %r2 /* Try to take it */
cmp $1, %r1 /* Did the write succeed? */
bne loop /* If not, someone beat us to it... try again */
/* critical section here... */
st $1, %r2 /* release the semaphore with a simple store */
If another entity manages to take the lock (in other words to write to the address in %r2) during the highlighted section (or the thread is descheduled), or if something breaks the execution flow like an interrupt or a context switch, the stc executed as part of the lock taking operation will fail and the loop will repeat.
Otherwise, everything between ldl and stc must have executed as if "atomically" so the core has the lock.
Any write to that location/interrupt/context switch during the atomic part will lead to stc failing.
The Power of LL/SC
With instructions like test-and-set, the load and the store can be guaranteed to be atomic by RMW behaviour.
Although the code between LL and SC is not atomic in absolute, we know that anything between the ldl and the stc has executed atomically with respect to the synchronisation variable.
This can be more powerful than tas for certain forms of usage, for example LL/SC are an easy and efficient way to implement the behaviour of fetch-and-add and other atomic instructions.
They also reduce the number of special instructions that need to be supported by the architecture, and are well suited to RISC processors.
Spinlocks
All the versions of the wait operation we developed for our semaphore use a busy loop to implement the act of waiting.
Threads never go to sleep and keep trying to get the lock over and over again.
This is called busy waiting or spinning, and locks using that method for waiting are named spinlocks.
They monopolise the processor and can hurt performance when the lock is contented.
Putting waiting threads to sleep, in other words scheduling them out of the CPU, would be much more efficient from the resource usage point of view: when a thread sleeps waiting for a lock to be free, it relinquishes the core and another task/thread can be scheduled on that core. There are various more sophisticated forms of locking to address this. They are implemented at the OS level and the basic hardware support is the same. We'll say a few words about OS support in the next lecture.
OS Support for Multithreading
You can access the slides for this lecture here. All the code samples given here can be found online, alongside instructions on how to bring up the proper environment to build and execute them here.
In this unit we have covered, among other things, software and hardware support for multithreaded programming. Here we will focus on the software layer that sits in between the application and the hardware: the operating system.

We will have a look at Linux (sometimes also simply referred to as the kernel in this document) and will cover mainly two topics:
- What is the role of the operating system in the management and synchronisation of multithreaded programs?
- Linux is itself a highly concurrent program, so how is concurrency managed in the Linux kernel?
This lecture is medley of interesting information regarding OS support for multithreading and concurrency in the kernel, and by no means an exhaustive coverage of these topics.
Thread Management
As previously covered, a thread is a unique schedulable entity in the system, and each process has 1 or more threads:

Processes are identified in Linux with unique integers named PIDs (process identifiers). You can get a list of all running processes and see their PIDs with the following command:
ps -A
Each row represent a process, and the first column contains its PID.
Each thread is uniquely identified by another integer, the thread identifier, TID.
Threads sharing the same address space will report the same PID.
Many system calls requiring a PID (e.g. sched_setscheduler) actually work on a TID.
To list all threads running in a Linux system, use the following command:
ps -AT
The TIDs are indicated in the SPID column.
From within a C program, the PID and TID of a calling process/thread can be obtained with the getppid and gettid functions, respectively.
Here is an example program making use of these functions:
#define _GNU_SOURCE // Required for gettid() on Linux
/* includes here */
void *thread_function(void *arg) {
printf("child thread, pid: %d, tid: %d\n", getpid(), gettid());
pthread_exit(NULL);
}
int main() {
pthread_t thread1, thread2;
printf("parent thread, pid: %d, tid: %d\n", getpid(), gettid());
pthread_create(&thread1, NULL, threadFunction, NULL);
pthread_create(&thread2, NULL, threadFunction, NULL);
pthread_join(thread1, NULL);
pthread_join(thread2, NULL);
}
You can find the code for the full program here.
The parent thread starts by printing its PID and TID, then creates 2 children threads, and both print their PIDs and TIDs. Here is an example of output:
parent thread, pid: 12674, tid: 12674
child thread, pid: 12674, tid: 12675
child thread, pid: 12674, tid: 12676
As one can observe, threads belonging to the same process all report the PID of that process.
The first thread created in a process (the one executing the main function) reports a TID equals to the PID of the process.
Other children threads report different TIDs.
Thread Creation
The clone System Call.
Processes and threads are both created with the clone system call.
Here is its prototype:
long clone(unsigned long flags, void *stack, int *parent_tid, int *child_tid,
unsigned long tls);
When creating a new process through clone most of these parameters do not matter and are set to 0/NULL.
In such case the behaviour of clone is similar to that of the fork UNIX primitive: the parent's resources are duplicated, and a copy is made for the child.
Among other resources, the child gets a copy of the parent's address space.
When creating a new thread with which we want to share the parent's address space, a few parameters are important:
flagsspecifies thread creation options;stackshould point to the memory space that will be used as stack for the newly created thread;tlspoints to a memory space that will be used as thread local storage for the newly created thread.parent_tidandchild_tidindicate locations in memory where the system call will write the child TID.
Each thread needs a stack to store local variables, function arguments, etc.
Each thread also needs a thread local storage (TLS) area to hold a particular type of global variable that hold a per-thread value.
TLS works by prefix the declaration of global variables for which we want to have per-thread values with the __thread keyword.
It is used to implement e.g. errno, which is a global variable but requires a per-thread value to avoid being accessed concurrently when different threads in the same process call functions from the C standard library concurrently.
pthread_create Under the Hood.
Let's now study what happens when a program calls pthread_create.
The POSIX thread library is implemented as part of the C standard library, which on most Linux distribution is the GNU C standard library, Glibc.
Its code is very convoluted, and we'll rather study the implementation of pthread_create in the Musl C standard library.
Its code is much simpler, but it is production-ready: Musl libc is used for example in the Alpine minimalist Linux distribution.
Musl libc's pthread_create is implemented in src/thread/pthread_create.c.
It does the following (simplified):
- Prepare
clone's flags withCLONE_VM | CLONE_THREADand more. These two flags indicate that we want to create a thread rather than a new process, and that as such there should be no copy of the parent's address space, it will rather be shared with the child. - Allocate space for a stack (pointed by
stack) withmmap.mmapis a system call used to ask for memory from the kernel (functions likemallocornewin C++ actually usemmapunder the hood). Also, create a TLS area pointed bynewwith__copy_tls. - Place on that stack a data structure that contains the created thread entry point, as well as the argument to pass to the function the created thread will start to execute.
- Call
clone's wrapper__clone:
ret = __clone(start, stack, flags, args, &new->tid, TP_ADJ(new), &__thread_list_lock);
This wrapper will take care of performing the system call to clone.
Because that system call is quite architecture specific, it is implemented in assembly.
For x86-64 the implementation is in src/thread/x96_64/clone.s.
It looks like this:
__clone:
xor %eax,%eax // clear eax
mov $56,%al // clone's syscall id in eax
mov %rdi,%r11 // entry point in r11
mov %rdx,%rdi // flags in rdi
mov %r8,%rdx // parent_tid in rdx
mov %r9,%r8 // TLS in r8
mov 8(%rsp),%r10
mov %r11,%r9 // entry point in r9
and $-16,%rsi
sub $8,%rsi // stack in rsi
mov %rcx,(%rsi) // push thread args
syscall // actual call to clone
test %eax,%eax // check parent/child
jnz 1f // parent jump
xor %ebp,%ebp // child clears base pointer
pop %rdi // thread args in rdi
call *%r9 // jump to entry point
mov %eax,%edi // ain't supposed to return
xor %eax,%eax // here, something's wrong
mov $60,%al
syscall // exit (60 is exit's id)
hlt
1: ret // parent returns
We have called __clone from C code, and we see here that it's actually just an assembly label.
Before starting to study this code, we need to understand the x86-64 calling convention.
A calling convention defines how the compiler translates function calls in the source code into machine code.
Indeed, the CPU only understands machine code and there is no notion of functions in assembly, so we need a convention to indicate, upon a function call:
- Which arguments are passed in which registers
- Which register will contain the return value when the function returns.
The calling convention implemented by Linux is called the System V application binary interface, and it specifies that arguments should be passed in order in the following registers:
| Argument number | x86-64 register |
|---|---|
| 1 | %rdi |
| 2 | %rsi |
| 3 | %rdx |
| 4 | %rcx |
| 5 | %r8 |
| 6 | %r9 |
For function calls with more than 6 arguments, they are passed on the stack.
The return value after a function call is held in %rax.
So when __clone is called from C code as presented above, we have the parameter start in %rdi, stackin %rsi, args in %rdx, etc.
Knowing this we can start to explore the assembly code that makes up the implementation of our wrapper __clone.
From a high level point of view, this code prepares the parameters for the clone system call, and executes it.
Both the parent and the child will return concurrently from this system call: if clonereturns 0, we are in the child, and if it returns a positive integer we are in the parent.
So there is a check on that return value.
The parent will directly return to the C code that called __clone, and the child will jump to its entry point.
More in details, the assembly code does the following:
- It clears
%eaxand writes56in there (%alis the lower part of that register).56is the [system call indentifier]https://filippo.io/linux-syscall-table/ forclone. When it is invoked, the OS kernel will check that register to know what system call is actually called. - The child entry point is placed in
%r11, and will be moved a few lines later to%r9. - The pointer for the child's stack
stackis placed in%rsi, and the argument for the function the child will jump to when it starts to run is placed on the top of that stack - The kernel is invoked with the
syscallinstruction. We will study what happens inside the kernel shortly. - When the kernel returns to user space, both the parent and the child are running.
The system call return value is tested, and if it's different than
0we are in the parent. The parent jumps to the1:label and returns to the C code that called__clone. - The child's stack and CPU context need to be prepared for return to C code.
The child clears the base pointer, and pop the argument for the function it will jump to from the stack into
%rdi. - Finally, the child jumps to its entry point.
- The code below that jump is never supposed to be reached, if that happens it's an error so it just calls the
exitsystem call to abort.
cloneImplementation Inside the Kernel.
Inside the kernel clone is implemented in kernel/fork.c.
When the user space program invokes the syscallinstruction, there is a transition to the kernel.
In the kernel the system call handler looks at %rax, sees that the user space wants to run the clone system call, so the kernel calls sys_clone, which itself calls kernel_clone, which calls copy_process.
copy_process implements the parent's duplication.
It calls various functions checking clone's flags to know what needs to be copied and what needs to be shared between parent/child.
For example, for the address space (simplified):
static int copy_mm(unsigned long clone_flags, struct task_struct *tsk) {
/* ... */
if (clone_flags & CLONE_VM) {
mmget(oldmm);
mm = oldmm;
} else
mm = dup_mm(tsk, current->mm);
/* ... */
}
Here, mm is a data structure representing its address space.
It is duplicated if clonewas called without the CLONE_VM flag, i.e. if we are trying to create a new process.
In the case of a thread, it inherits the same mm structure as the parent: they will share the address space.
Jumping to the Child Thread's Function.
When we go back to user space in the child's context, the jump from the assembly code we have seen above leads to executing the start entry point defined by Musl in src/thread/pthread_create.c:
static int start(void *p) {
struct start_args *args = p;
/* ... */
__pthread_exit(args->start_func(args->start_arg));
}
The actual function the thread needs to run is in args->start_func, so it is called with the desired parameters, before existing the thread with pthread_exit.
In-Kernel Locks
Let's now study how the kernel implements the locks.
Indeed, under the hood pthread_mutex_lock and other sleep-based lock access primitives rely on the kernel.
There is a good reason to implement such locks in the kernel rather than user space: the kernel is the entity that can put threads to sleep and wake them up.

Historically each lock operation, including lock take/release, required a system call, as implemented with e.g. System V semaphores. However, the user/kernel world switches are expensive and the resulting overhead is non-negligible. It can seriously impact performance, especially in scenarios where a lock is not contended:

Futex
One may observe that we only need kernel intervention when there is contention, i.e. when a thread needs to sleep. The futex is a low-level synchronisation primitive which name stands for Fast User space mutEX. It can be used to build locks accessed in part in user space with atomic operations when there is no contention. There is another part in kernel space, used when there is contention and threads need to be put to sleep/awaken.
A futex relies on a 32 bit variable living in user space, accessed concurrently by threads trying to take/release the lock with atomic operations. When it is equal to zero, the lock is free:

In that state, a thread wishing to take the lock tries to do so with an atomic compare-and-swap on the variable: if the compare-and-swap succeeds, the thread successfully got the lock without any involvement from the kernel. The thread can proceed with its critical section:

Another thread trying to take the lock while it is not free will try a compare-and-swap, that will fail.
In that case the thread needs to be put to sleep, and for that the OS kernel is needed, and a system call is made.
That system call is named futex.

Before putting the thread to sleep, the kernel makes a last check to see if the lock is still taken with a compare-and-swap, and if so, puts the thread to sleep in a data structure called wait queue:

Other threads trying to take the lock that is still non-free follow the same path:

A thread wanting to release the lock use a compare-and-swap to reset the user space variable to zero, indicating that the lock is free.
It also makes a futex system call to ask the OS to wake one of the threads waiting:

The other thread will try to take the lock with a compare-and-swap, and succeed:

Note that with the simple example implementation of lock using futex we present here, when a thread releases the lock, the user space does not know if there are waiters or not, so a system call is made even if there are no waiters:

An optimised implementation would e.g. encode the number of waiters in the 32 bit user land variable.
Basic Futex Lock Implementation
Below is a simple example of lock implementation on top of futex.
It behaves similarly to what is described in the schemas above.
/* check full implementation for includes */
atomic_int my_mutex = ATOMIC_VAR_INIT(0);
int my_mutex_lock() {
int is_free = 0, taken = 1;
// cas(value_to_test, expected_value, new_value_to_set)
while(!atomic_compare_exchange_strong(&my_mutex, &is_free, taken)) {
// put the thread to sleep waiting for FUTEX_WAKE if my_mutex
// is still equal to 1
syscall(SYS_futex, &my_mutex, FUTEX_WAIT, 1, NULL, NULL, 0);
}
return 0;
}
int my_mutex_unlock() {
atomic_store(&my_mutex, 0);
// wake up 1 thread if needed
syscall(SYS_futex, &my_mutex, FUTEX_WAKE, 1, NULL, NULL, 0);
return 0;
}
You can download the source code of a full program using that implementation here.
We have our user space variable my_mutex.
It is initialised to 0 and manipulated using the C atomic operations API.
Recall that it is not a good idea to assume that standard loads and store are atomic (e.g. a standard load of a 64 bits variable could be represented as two loads on a 32 bit architecture).
The lock taking function, my_mutex_lock, performs a compare-and-swap with atomic_compare_exchange_strong checking if the variable representing the lock is 0 (is_free), i.e. if the lock is free.
If it is the case, compare-and-swap function returns 1 and my_mutex_lockreturns: the lock has been taken.
If not, a system call is needed to put the thread to sleep: futex is called, taking various parameters, the important one here being the address of the user space variable representing the lock, and the FUTEX_WAIT flag indicating that the thread should be put to sleep.
When the thread is later awaken, it will return from futex and try another iteration of the loop.
The mutex_unlock operations starts by resetting the user space variable to 0 to indicate that the lock is free.
It then calls futex, this time with the FUTEX_WAKE flag, to indicate the kernel to wake up 1 waiter in the wait queue if needed.
Investigating Lock Performance
We can write a small benchmark measuring latency introduced by the locking/unlocking operations, by creating a bunch of threads running that function and measuring their execution time:
#define CS_NUM 100000
void *thread_function(void *arg) {
for(int i=0; i < CS_NUM; i++) {
lock();
// instantaneous critical section to maximise the impact of the
// latency introduced by the lock/unlock operations
unlock();
}
return;
}
We can compare the performance of 3 types of locks:
- The simple futex-based lock we just presented;
- Traditional
pthread_mutex_lockoperations, that under the hood used a heavily optimised version of the futex lock; - System V semaphores, which require a system call for every lock/unlock operation.
You can find the sources of the benchmark here.
Here is an example of execution on an i7-8700 with 6 cores:
System V semaphores:
./lock-bench-sysv-semaphores
5 threads ran a total of 500000 crit. sections in 1.262348 seconds, throughput: 0.396087 cs/usec
Pthread_mutex (futex):
./lock-bench-futex
5 threads ran a total of 500000 crit. sections in 0.020067 seconds, throughput: 24 cs/usec
custom futex lock:
./lock-bench-custom-futex
5 threads ran a total of 500000 crit. sections in 0.069710 seconds, throughput: 7 cs/usec
As you can see, both versions of the futex-based lock are orders of magnitude faster than using System V semaphores.
The optimised version (i.e. pthread_mutex operations implemented by the Glibc) of the futex-based lock is 3x faster than the naive implementation we presented above.
Pthread Mutex Implementation
The previous custom futex lock implementation is suboptimal (and, technically, not 100% correct, see here).
Let's briefly have a look at Musl (futex-based) implementation of pthread_mutex_lock in src/thread/pthread_mutex_lock.c.
int __pthread_mutex_lock(pthread_mutex_t *m) {
if ((m->_m_type&15) == PTHREAD_MUTEX_NORMAL
&& !a_cas(&m->_m_lock, 0, EBUSY)) // CAS, futex fast path
return 0;
return __pthread_mutex_timedlock(m, 0); // Didn't get the lock
}
We can see the compare-and-swap on the user space variable: if the lock was free we take the fast path and return directly.
If not, __pthread_mutex_timedlock is called.
pthread_mutex_timedlock (in src/thread/pthread_mutex_timedlock.c) calls a bunch of functions that end up in FUTEX_WAIT being called in __timedwait_cp (in src/thread/__timedwait.c):
int __timedwait_cp(volatile int *addr, int val,
clockid_t clk, const struct timespec *at, int priv)
{
/* ... */
r = -__futex4_cp(addr, FUTEX_WAIT|priv, val, top);
/* ... */
}
Here, __futex4_cpis a wrapper around a futex system call.
We can also have a brief look Musl's implementation of pthread_mutex_unlock in src/thread/pthread_mutex_unlock.c:
int __pthread_mutex_unlock(pthread_mutex_t *m) {
int waiters = m->_m_waiters;
int new = 0;
/* ... */
cont = a_swap(&m->_m_lock, new);
if (waiters || cont<0)
__wake(&m->_m_lock, 1, priv);
}
The user space variable is first reset to 0with a compare-and-swap to indicate that the lock is free.
Musl's implementation also keeps track of contention, and calls __wake if waiters need to be awaken.
__wake's implementation in src/internal/pthread_impl.h will lead to a futex FUTEX_WAKE system call.
Concurrency in the Kernel
Historically there used to be a big kernel lock serialising all execution of kernel code. It was slowly removed over time, and this removal was finalised in v2.6.39 (2011). Today the kernel is a highly concurrent, shared memory program:

Concurrent flows of execution include system calls issued by applications running on different cores, exceptions and hardware interrupts that may interrupt the kernel execution flow, kernel threads & other execution flow entities, kernel preemption, etc. In that context, various locking mechanism are available to protect critical section in kernel code. We will study a few of these next.
Locking in the Kernel
Linux offers various types of locks:
- Linux's in-kernel mutexes implement sleep-based wait and have a usage count (number of entities that can hold the mutex) of 1.
- The in-kernel semaphores also implement wait by sleeping, but their usage count can be more than 1
- Similarly to user space, Linux offers in-kernel spinlocks, that implement wait with busy waiting (and their usage count is 1). Spinlocks run with preemption and possibly interrupts disabled: contrary to sleep-based locks they are usable when kernel execution cannot sleep. A typical example here are interrupt handlers. These cannot sleep because they are not schedulable entities like processes or threads, so we can only use busy-waiting in that case.
- Completion variables are the in-kernel equivalent of the condition variables we saw in user space.
- Reader-writer spinlocks and Sequential locks are two specific types of locks that differentiate readers from writers. We will cover them a bit more in details next.
Spinlocks in the Kernel
As mentioned spinlocks are used to protect critical sections in contexts where the kernel cannot sleep.
This is an excerpt from the i8042 mouse/keyboard driver in drivers/input/serio/i8042.c (simplified):
static irqreturn_t i8042_interrupt(int irq, void *dev_id) {
unsigned long flags;
/* ... */
spin_lock_irqsave(&i8042_lock, flags);
/* critical section, read data from device */
spin_unlock_irqrestore(&i8042_lock, flags);
}
This code is executed following the reception of an interrupt from the device, i.e. it runs in interrupt context.
In that context the kernel cannot sleep so it needs to use locks that busy wait, such as the spinlock.
Here, spin_lock_irqsave takes the lock, saves the interrupt state (i.e. the fact that interrupts are disabled or not) into the flags variable, and disables interrupt if they were not already off.
spin_unlock_irqrestore releases the lock, restores interrupt state from flags, i.e. enable interrupts if they were enabled prior to taking the lock, or leave them disabled if they were not.
Reader-Writer Spinlocks
In many scenarios, certain critical sections accessing a given shared data are read only. If there is no writer in a given time window, letting several concurrent entities run these critical sections during that time window is fine. Reader-writer locks are a special type of spinlocks that differentiate readers from writers (they don't use the same lock/unlock primitives). Such locks serialise write accesses with other (read/write accesses), but allows concurrent readers:

In the example above, we can see that the 3 readers can run their (read-only) critical sections at the same time. A writer wishing to take the lock must wait until there is no reader to be able to take the lock. If a writer tries to take the lock and must wait because there are readers holding it, subsequent readers trying to take the lock will succeed and delay the execution of the writer (e.g. here reader 2 and 3). Hence, reader-writer locks favour readers.
Sequential Locks
The seqlock (sequential lock) is another form of spinlock that has a sequence number associated, which is incremented each time a writer acquires the lock, and incremented each time a writer releases the lock. Concurrent readers are allowed, they check the number at the beginning and end of their critical section. If a reader realise at the end of its critical section that the number has changed, it means that a writer started/finished since the beginning of the reader's critical section.
Here is an example of scenario for a seqlock (bottom), compared to what happens with a reader-writer lock (top):

As one can observe, reader 1 realises at the end of its critical section that writer 1 started its own since it got the lock, so it restarts. Writer 1 was able to start its critical section directly. Readers can still run in parallel: seqlocks scale to many readers like the reader-writer lock, but favours writers.
Read-Copy-Update
RCU is a method to protect a critical section that allows concurrent lockless readers. It is suited in situations where it OK for concurrent readers not to see the same state for a given piece of data, as long as all see a consistent state.
Let's take an example by demonstrating how concurrent accesses to a linked list can be made safe with RCU.
RCU Example: Linked List Update
We consider a singly linked list with a head pointer. Readers traverse the list to extract data from certain nodes: because they do not modify anything, they do not take any lock. Writers traverse the list to update the data contained in certain nodes. Writers also add/delete elements. Each node is a data structure with a few members and a next pointer.
Such a list is illustrated below:

Let's study what a writer would do with RCU when it wants to update the content of a node.
- First a new node is allocated, and the data from the node we want to update is copied there:

- The desired update is performed in the copy:

- The new node is made to point to the node after the one we wish to update:

- With an atomic operation, the next pointer of the node preceding the one we wish to update is swapped to point to the new node:

- At that stage, there may be outstanding readers still reading the old version of the data structure and we need to wait until no reader is accessing that old node: this is called the grace period:

- When we are certain there is no reader accessing the old node, it can be freed:

Consider the state of the list a reader would see if it runs during any of the steps we previously described: races are not possible because at any time the readers will either see a consistent state of the queue, i.e. the state before or after the update. We have made the update atomic with respect to the readers. Note that due to the grace period, it is possible for some reader to see the old state of the queue after the writer has effectively realised the update. In many situations this is OK, in others it is not: this is to be considered carefully before choosing to use RCU. Finally, note that the writers do need to take a lock because they still need to be serialised.
RCU Example in Linux
Linux provides an API to protect critical sections with RCU. Below is and example of its usage to protect a data structure. It is taken from Linux's official documentation.
struct foo { int a; int b; int c; };
DEFINE_SPINLOCK(foo_mutex); // a spinlock to serialise writers
// the reference we want to protect (assume it is initialised somewhere else):
struct foo __rcu *gbl_foo;
void foo_read(void) {
struct foo *fp;
int a, b, c;
rcu_read_lock();
fp = rcu_dereference(gbl_foo);
a = fp->a;
b = fp->b;
c = fp->c;
rcu_read_unlock();
/* do something with what was read ... */
}
void foo_write(int new_ab) {
struct foo *new_fp, *old_fp;
new_fp = kmalloc(sizeof(*new_fp), GFP_KERNEL); // allocate new data
spin_lock(&foo_mutex); // serialise writers
// get a ref to the data:
old_fp = rcu_dereference_protected(gbl_foo, lockdep_is_held(&foo_mutex));
*new_fp = *old_fp; // copy data
new_fp->a = new_ab; // update data
new_fp->b = new_ab; // update data
// atomic ref update:
rcu_assign_pointer(gbl_foo, new_fp);
spin_unlock(&foo_mutex);
synchronize_rcu(); // wait for grace period
kfree(old_fp); // free old data
}
You can find the source code of a Linux kernel module testing this code, alongside with instructions on how to build and run it here. Note that this is kernel code, so you won't be able to run it on unprivileged containers (e.g. GitHub codespaces).
We have our data structure declaration, the type is struct foo and it contains 3 members.
The reference to the data structure we want to protect with RCU is gbl_foo.
We assume that the data structure it points to is initialised somewhere else (in the full program the module's initialisation function takes care of that).
We define a spinlock foo_mutex to serialise the writers.
The two functions foo_write and foo_read represent the code that the concurrent readers/writers will run.
Readers Function.
foo_read is relatively simple: it uses rcu_read_lock and rcu_read_unlock to indicates its critical section.
Note that these functions do not actually take/release a lock, but rather help keep track of readers to know when the grace period has ended.
Within the critical section the reference is grabbed with rcu_dereference.
Writers Function.
foo_write starts by allocating a new data structure with kmalloc (the kernel equivalent of malloc), and grabs the spinlock serialising writers.
It then grabs a reference to the protected data structure with rcu_dereference_protected, an optimised version of rcu_dereference that can be used on the writers' side.
It then performs the copy, and updates the copy.
The atomic reference update is performed with rcu_assign_pointer.
Next the spinlock can be released.
Finally, synchronize_rcu is used to wait until the end of the grace period, i.e. to wait until there is no reader holding a reference to the old data structure, which can finally be deallocated with kfree.
Message Passing Interface
You can access the slides for this lecture here. All the code samples given here can be found online, alongside instructions on how to bring up the proper environment to build and execute them here.
Here we will talk briefly about MPI. It's a standard defining a set of operation allowing to write distributed application that can be massively parrallel.
MPI
MPI is a standard that describes a set of basic functions that can be used to create parallel applications, possibly spanning multiple computers. These functions are available in libraries for C/C++ and Fortran. Such applications are portable between various parallel systems that support the standard. MPI is used to program many types of systems, not only shared memory machines as we have seen until now, but also custom massively parallel machines also called manycores or supercomputers. MPI can be used to run a single application over an entire set of machine, a cluster of computers. An important thing to note is that MPI relies on message passing and not shared memory for communications. This allows an MPI application to exploit parallelism beyond the boundary of a single machine. For these reasons MPI is the most widely used API for parallel programming. Still programming in MPI has a cost: the application must be designed from scratch with message passing in mind, so porting existing applications is costly.
Messages, Processes, Communicators

In MPI each parallel unit of execution is running as a process. Each process is identified by its rank, which is an integer. Processes exchange messages, characterised by the rank of the sending and receiving processes, as well as an integer tag that allows to define message types.
Processes are grouped, they are initially within a single group which can be split later. Messages can be sent over what is called a communicator linked to a process group in order to restrict the communication to a subset of the processes.
MPI Hello World
Here is a minimal MPI application in C:
#include <mpi.h>
#include <stdio.h>
int main(int argc, char** argv) {
// Initialize the MPI environment
MPI_Init(NULL, NULL);
// Get the number of processes and the rank of the process
int world_size, world_rank;
MPI_Comm_size(MPI_COMM_WORLD, &world_size);
MPI_Comm_rank(MPI_COMM_WORLD, &world_rank);
// Get the name of the processor (machine)
char processor_name[MPI_MAX_PROCESSOR_NAME];
int name_len;
MPI_Get_processor_name(processor_name, &name_len);
// Print off a hello world message
printf("Hello world from processor %s, rank %d out of %d processes\n",
processor_name, world_rank, world_size);
// Finalize the MPI environment.
MPI_Finalize();
}
This code will be executed by each process of our application.
We start by initialising the MPI library with MPI_Init.
Then we get the total number of processes running for this application with MPI_Comm_size.
We get the identifier of the current process, i.e. its rank, with MPI_Comm_rank.
Then we get the name of the processor (the machine executing the process) into a character array, and finally we print all this information before exiting.
To build and run this example you need the MPI Library. To install the MPICH implementation on Ubuntu/Debian use the following command:
sudo apt install mpich
To compile the aforementioned example, use the provided gcc wrapper:
mpicc mpi-hello.c -o mpi-hello
To run the program use mpirun.
The number of processes created by default depends on the version of the library.
Some versions create a single process, others create a number of process equals to the number of cores of the machine:
mpirun mpi-hello
mpirun -n 8 mpi-hello # Manually specify the number of processes to run
Blocking send and recv
To send and receive messages we have the MPI_Send and MPI_Recv functions.
They take the following parameters:
datais a pointer to a buffer containing the data to send/receive. As you can see its type isvoid *so it can point to anything. In other words the messages sent and received can embed any type of data structure.cntis the number of items to send or receive, in the case an array is transmitted.tis the type of the data exchanged. For this the MPI library offers macros for integers, floating point numbers, and so on.dstis the rank of the receiving process for send.srcis the rank of the sending process for receive. Note that there are some macros to specify sending and receiving from any process.comis the communicator describing the subset of processes that can participate in this communication.stwill be set with status information that can be checked after receive completes.
MPI_Send(void* data, int cnt, MPI_Datatype t, int dst, int tag, MPI_Comm com);
MPI_Recv(void* data, int cnt, MPI_Datatype t, int src, int tag, MPI_Comm com,
MPI_Status* st);
Let's study a simple example of MPI program using the send and receive primitives. Our example is an application that creates N processes. At the beginning the first process of rank 0 creates a counter and initialises it to 0. Then it sends this value to another random process, let's say 2. 2 receives the value, increments it by one, and sends the result to another random process. And rinse and repeat. This process is illustrated below:

The code for the application is below:
#include <stdio.h>
#include <stdlib.h>
#include <mpi.h>
#define BOUNCE_LIMIT 20
int main(int argc, char** argv) {
MPI_Init(NULL, NULL);
int my_rank, world_size;
MPI_Comm_rank(MPI_COMM_WORLD, &my_rank);
MPI_Comm_size(MPI_COMM_WORLD, &world_size);
if (world_size < 2) {
fprintf(stderr, "World need to be >= 2 processes\n");
MPI_Abort(MPI_COMM_WORLD, 1);
}
/* The first process is in charge of sending the first message */
if(my_rank == 0) {
int payload = 0;
int target_rank = 0;
/* We don't want the process to send a message to itself */
while(target_rank == my_rank)
target_rank = rand()%world_size;
printf("[%d] sent int payload %d to %d\n", my_rank, payload,
target_rank);
/* Send the message */
MPI_Send(&payload, 1, MPI_INT, target_rank, 0, MPI_COMM_WORLD);
}
while(1) {
int payload;
/* Wait for reception of a message */
MPI_Recv(&payload, 1, MPI_INT, MPI_ANY_SOURCE, 0, MPI_COMM_WORLD,
MPI_STATUS_IGNORE);
/* Receiving -1 means we need to exit */
if(payload == -1) {
printf("[%d] received stop signal, exiting\n", my_rank);
break;
}
if(payload == BOUNCE_LIMIT) {
/* We have bounced enough times, send the stop signal, i.e. a
* message with -1 as payload, to all other processes */
int stop_payload = -1;
printf("[%d] broadcasting stop signal\n", my_rank, payload);
for(int i=0; i<world_size; i++)
if(i != my_rank)
MPI_Send(&stop_payload, 1, MPI_INT, i, 0, MPI_COMM_WORLD);
break;
}
/* increment payload */
payload++;
int target_rank = my_rank;
/* Choose the next process to send a message to */
while(target_rank == my_rank)
target_rank = rand()%world_size;
printf("[%d] received payload %d, sending %d to %d\n", my_rank,
payload-1, payload, target_rank);
MPI_Send(&payload, 1, MPI_INT, target_rank, 0, MPI_COMM_WORLD);
}
MPI_Finalize();
}
You can download this code here.
Recall that this code is executed by each process in our application.
We start by getting the total number of processes and our rank with MPI_Comm_size and MPI_Comm_rank.
Then the process of rank 0 will initialise the application, and sends with MPI_Send the initial message to a random process.
The rest of the code is an infinite loop in which each process starts by waiting for the reception of a message with MPI_Recv.
Once a message is received, the counter's value is increased and sent to a random process with MPI_Send.
When a process detects that the counter has reached its maximum value, it sends a special message (-1) to all processes indicating that they need to exit.
Collective Operations
In addition to send and receive there are also various collective operations
They allow to easily create barriers (MPI_Barrier), and to broadcast a message to multiple processes (MPI_Bcast).
While broadcast sends the same piece of data to multiple processes, scatter (MPI_Scatter) breaks a data into parts and sends each part to a different process.
Gather (MPI_Gather) is the inverse of scatter and allows aggregating elements sent from multiple process into a single piece of data.
There is also reduce (MPI_Reduce), that allows to combine values sent by different processes with a reduction operation, for example an addition
With such operations, many programs make little use of the more basic primitives MPI_Send/MPI_Recv.
MPI also has other features, including non-blocking communications with MPI_Isend and MPI_Ireceive.
These functions do not wait for the request completion, and they return directly, so in general they are used in combination with MPI_Test to check the completion of a request, and MPI_Wait to wait for a completion.
There is also a feature called persistent communications that is useful to define messages that are sent repeatedly with the same arguments.
Furthermore, there are 3 communication modes:
- With the standard one, a call to send returns when the message has been sent but not necessarily yet received.
- With the synchronous one, a call to send returns when the message has been received.
- And with the buffered one, the send operation returns even before the message is sent, something that will be done later.
- Finally MPI also allows a process to directly write in the memory of another process using
MPI_PutandMPI_Get.
This is just a very brief introduction to MPI. To learn more, one can for example check out this course, as well as the official MPI standard.