Home
Welcome to the website hosting the lecture materials and formative exercises for The University of Manchester’s COMP26020 Programming Languages and Paradigms part 1: C programming. You can use the menu on the left to navigate the materials: for each lecture you can access the lecture notes as well as the lecture slides. For most topics covered there is also a series of formative auto-corrected exercises.
Instructor: Pierre Olivier
Favicon by icon8.com.Logistics
Here we discuss how the C programming part of COMP26020 is organised. You can access the slides 🖼️ for this lecture.
A Typical Week
The unit follows a blended approach: we’ll have one live session per week, then there is also a set of asynchronous materials (videos and exercises) to study. This year the live session is on Monday, and then you have the rest of the week to work on the asynchronous materials:

C Part: Unit Content
The C part of the unit is made of:
- Lecture materials:
- There is a live lecture every Monday 12pm-1pm, located in Simon Building Lecture Theatre B.
- There will also be a set of (short) videos to watch every week after the lecture.
- Formative (i.e. not marked) assessments:
- One quiz to complete each week after having studied the lecture materials, to check that you understand the theory well.
- A set of autocorrected programming exercises to complete each week after having studied the lecture materials, to validate your knowledge from the practical point of view.
- Summative (i.e. marked) assessment:
- 1 lab exercise to be done at home and/or on the Department’s machines.
- Support sessions:
- These are optional and basically office hours; come if you have any questions about the lecture materials or assessments.
- Support sessions are scheduled every other week, starting from the week of 06/10, on Friday from 12pm to 2pm in Kilburn LF31.
Unit’s Pages on Canvas
The unit has a set of Canvas pages accessible here. The landing page for the C part is here, and everything regarding that part can be accessed from there:
- The unit’s schedule (what to do each week).
- Lecture videos, including recordings of live sessions.
- Lecture notes and lecture slides.
- The summative lab exercise brief.
- The formative autocorrected programming exercises.
- Formative quizzes.
- Discussion boards.
- Reading lists.
Required Software
All programming exercises (summative and formative) should be done in a Linux x86‑64 (i.e. Intel CPU) environment with the GCC compiler version 10–13. To access such a development environment you have several solutions:
- Use the Department’s machines.
- If your computer has an Intel x86‑64 CPU, run Linux in a virtual machine. A suitable VirtualBox VM image can be found here.
- If you know what you are doing, you can install Linux natively on your x86‑64 machine.
- For that Ubuntu 22.04 is recommended.
🚨🚨 Do not use native Windows/Mac or WSL environments 🚨🚨.
We will not provide support for these environments, and you may lose marks when we grade your summative exercise due to differences in build toolchains.
For those of you using MacBooks with ARM CPUs (Apple silicon) we’ll give some solutions next, but the general advice is to come on campus and use the lab machines.
Lecture Videos and Slides
Lecture videos, slides, as well as recordings of past live sessions are available on Canvas, by clicking on the lecture material topics from the landing page. In particular the slides contain clickable links and interactive code snippets. Here is an example (empty C program):

Take a look at the links at the bottom left of the code snippet; you have:
- A link (blue path) to download a fully functional programme containing the code illustrated in the snippet, if you want to build and run it on your local machine.
- A link to a GitHub repository
 containing the code in question, located in the same path as defined in the blue link. For example, with the above you can find the code in
containing the code in question, located in the same path as defined in the blue link. For example, with the above you can find the code in 00-logistics/sample-code.c. The GitHub repository also contains instructions on how to set up a proper development environment to build and run the code samples (including in your browser with GitHub CodeSpaces), and to do the formative/summative programming exercises for this part of the unit. This includes instructions for those of you that cannot get a native/VM-based Linux environment (e.g. Apple silicon CPUs).
Lab Assignment (Marked)
The brief is accessible here. The goal of the exercise is to implement a matrix processing library in C. It weights for 6.5% of the final COMP26020 mark. Keep in mind that this is a full‑year unit, and that the coursework/exam weighting for the C part of the unit is 50/50.
Autocorrected Programming Exercises (Not Marked)
There are a few formative programming exercises:
- Week 1: Dummy Exercise. A very simple exercise to check that you can handle the automated checking tool that will be used for the rest of the exercises.
- Week 2: C Basics. Exercises touching various basic concepts of the language such as variables, printing to the console, control flow, etc.
- Week 3: Memory Management and the Standard Library. Exercises covering pointers, dynamic memory allocation, and functions from the C standard library.
- Week 4: Building C Programs. Exercises covering the preprocessor, automation, and modular compilation.
- Week 5: Going Further. Ideas for follow‑up more ambitious projects, fully optional.
These exercises are corrected automatically with a tool called check50.
The instructions on how to install and use it are available on the page regarding the dummy exercise.
Quizzes
There is a small formative quiz to complete each week by clicking on the corresponding links on the landing page.
ChatGPT and other AI Tools
You should not use such tools to complete the summative lab exercise. We understand that they are becoming an important part of a programmer’s toolbox, and you will likely use them extensively throughout your career, but in our case they defeat the purpose of the unit which is to teach you how to program in C. All submissions will be passed through a plagiarism checking tool, and the ones with high code similarity (e.g. because the authors copied and pasted code from ChatGPT) will be subject to an academic malpractice procedure.
Similarly, it is not recommended to use AI tools to complete the formative exercises; they are generally quite simple and can be completed easily with such tools, but you are not learning much in the process.
Programming Paradigms
In this lecture we discuss the concept of programming paradigm and how it relates to programming languages. You can access the slides 🖼️ for this lecture. All the code samples given here can be found online, alongside instructions on how to bring up the proper environment to build and execute them here.
Programming Paradigms
To put it simply, a programming paradigm is a style of programming. This style defines how the programmer describes a program within its source code: the data that it uses, as well as the computations manipulating this data. Paradigms are high level categories used to classify programming languages.
Relation to Programming Languages
All programming languages fall within at least one paradigm. What this means is that they make it easy to program in the style defined by the paradigm in question. For example, a lot of operations look pretty similar in C++ and in C# because both languages fall within the object-oriented programming paradigm. Also, a lot of languages can be classified within several paradigms. For example, Objective Caml (OCaml) belongs to the object-oriented as well as functional programming paradigms:

This picture is adapted from this post.
Suitability of Paradigms/Language to Software Engineering Problems
Given a particular software engineering problem, let’s say one has to build a particular program, there are some programming paradigms that are much more efficient at solving that problem. For example, one cannot really write an operating system with a logical programming language.
JavaScript Example
Let’s illustrate the fact that a paradigm defines a programming style with an example. We simply want to multiply by 2 each element of an array. JavaScript allows writing code according to the imperative programming paradigm:
function mult_by_two_imperative (array) {
let results = []
for (let i = 0; i < array.length; i++) {
results.push(array[i] * 2)
}
return results
}
The imperative paradigm requires describing step by step all operations performed by the program. So we use a for loop to iterate over all the elements and multiply each by two. In some sense, this is very close to what happens on the CPU, which is executing instructions one step at a time.
JavaScript also allows writing code according to the declarative paradigm:
function mult_by_two_declarative (array) {
return array.map((item) => item * 2)
}
With the declarative paradigm we describe high level operations to be performed on each element of the array: each item is multiplied by two. This is more abstract and also more concise than imperative programming: it’s a one-liner.
A Programming Paradigm is a Programming Style
The paradigm characterises how the programmer defines the computations. It’s generally a sequence of statements performing various operations, in various order — for example sequentially or in parallel. These computations can be decomposed into units named functions. The computations can also be described in terms of how the result should look like. The paradigm also defines how to describe the data that is manipulated by the computations. It answers questions like what are the basic types, can we define custom data structures by composing these types, can the functions manipulate only a local set of variables or do they have access to a global state.
Picking a Programming Paradigm
Because some paradigms are more efficient than others to solve a given problem, when one needs to develop software, choosing a language (in other words choosing a paradigm) has huge consequences on the efficiency, size, complexity and clarity of the code.
The Main Programming Paradigms
Here we briefly discuss the main programming paradigms, examples of languages implementing them, and what kinds of software engineering problems they are good at solving. You can access the slides 🖼️ for this lecture. All the code samples given here can be found online, alongside instructions on how to bring up the proper environment to build and execute them here.
Main Programming Paradigms and Sub-Paradigms
Below are some of the main programming paradigms. They generally belong to one of the two high-level paradigms:
- Imperative:
- Structured (or procedural)
- Object-Oriented
- Concurrent
- Declarative:
- Functional
- Concurrent
These are the main ones; there are many more.
Imperative Programming Paradigm
As we saw in the JavaScript example from the previous slide deck, the imperative paradigm requires the programmer to describe the computation step by step, as a sequence of statements, a bit like a cooking recipe:

Here is an example of an imperative program written in x86-64 assembly language:
.global _start
.text
_start:
mov $1, %rax # system call 1 is write
mov $1, %rdi # file handle 1 is stdout
mov $message, %rsi # address of string to output
mov $14, %rdx # number of bytes
syscall # invoke operating system to perform the write
message:
.ascii "Hello, world!\n"
It’s a hello world program in assembly. No need to go into the details, but in this program instructions are executed one after the other to print a message on the console. Assembly is purely imperative and very low level, so it has some nice benefits such as very good performance and low memory footprint. It is also the only way to realise some low-level operations that are needed when one writes things like an OS or a virtual machine monitor.
The problem with assembly is that it’s not structured. In terms of control flow, there is no clear notion of functions, loops, and so on. We get what is called spaghetti code:

So even a medium-sized code becomes very hard to understand and reason about. Other examples of purely imperative languages are early versions of FORTRAN, COBOL, BASIC.
Imperative Structured Programming Paradigm
To be able to write bigger programs we need to use structured imperative programming. It includes control flow operations and the notion of procedures or functions. It makes it much easier to reason about large programs. Here is an example in C:
int is_prime_number(int number) { /* Check if a number is prime */
if(number < 2)
return 0;
for(int j=2; j<number; j++)
if(number % j == 0)
return 0;
return 1;
}
int main(void) { /* Check which of the first 10 natural integers are prime */
int total_iterations = 10;
for(int i=0; i<total_iterations; i++)
if(is_prime_number(i))
printf("%d is a prime number\n", i);
else
printf("%d is not a prime number\n", i);
return 0;
}
Once again, the instructions within a function are executed one after the other. But we can see some control flow operations: loops, conditionals, and function calls. This program prints the list of the first 10 integers and which ones are prime or not. Structured imperative programming originally appeared in languages such as ALGOL, Pascal, ADA, etc. Today most programming languages are structured for obvious reasons, compared to unstructured programming:
- Their modularity makes it easier to write code for medium/large programs.
- There is less complexity and the code is easier to understand.
- It also eases testing and debugging.
Modern low-level imperative structural languages without too many additional layers include C and FORTRAN. We will see that they are very efficient for HPC and systems software development. We will also see that they have memory safety issues.
Imperative Object-Oriented Programming Paradigm
With the object-oriented paradigm, the programmer links together the data and the code manipulating it into objects. While in non-object-oriented languages one calls a function out of nowhere, passing data as parameters, with object-oriented this function can be called upon a given data, for example here with the dot operator. Object-oriented also defines concepts such as inheritance and polymorphism that facilitate code reuse and organisation. Here is a C# program implementing these object types, that are actually named classes: shape, square and circle:
// Example in C#
abstract class Shape {
public abstract void printMe();
}
class Square : Shape {
override void printMe() {Console.WriteLine ("Square id: {0}, side: {1}", _id, _side);}
}
class Circle : Shape {
override void printMe() {Console.WriteLine ("Circle id: {0}, radius: {1}", _id, _radius);}
}
public class MainClass {
public static void Main(string[] args) {
Square mySquare = new Square(42, 10);
Circle myCircle = new Circle(242, 12);
mySquare.printMe();
myCircle.printMe();
}
}
We create two objects and call the printMe function on them.
A few examples of object-oriented languages are C++, C#, or Java.
Object-oriented languages are good at representing problems with a lot of state and operations, e.g., when we have to process a lot of data that can be described as attributes.
Examples of software where modeling data and the operations that can be applied on it with objects include simulators, video games, and so on.
This paradigm also helps in organising, understanding, and maintaining large code bases, but for small programs it can sometimes be overkill.
Imperative Concurrent Programming Paradigm
With the imperative concurrent paradigm, the programmer uses various features provided by the language to describe parallel and interleaving operations. Here we have an example with a C library named the POSIX threads:
static void *thread_function(void *argument) {
int id = *(int *)argument;
for(int i=0; i<10; i++)
printf("Thread %d running on core %d\n", id, sched_getcpu());
}
int main(void) {
pthread_t threads[NUMBER_OF_THREADS];
int thread_ids[NUMBER_OF_THREADS];
for(int i=0; i<NUMBER_OF_THREADS; i++) {
thread_ids[i] = i;
pthread_create(&threads[i], NULL, &thread_function, &thread_ids[i]);
}
/* ... */
}
The important part is within the for loop where we create a certain number of threads. These threads are parallel execution flows and each will execute the function named thread function. An example of execution of this program with 4 threads and 2 parallel processing units (CPU cores) could be:

A concurrent programming language describes in particular how the execution flows can communicate, can they share data structures, and if yes, what is the consistency of that sharing. There are many methods for concurrent programming in imperative languages. They include shared memory threads and processes, message passing and automatic parallelisation libraries, GPU programming languages, and so on. Important use cases for concurrent programming are of course high performance and distributed computing, graphic processing, etc.
Declarative Programming Paradigm
Contrary to imperative programming, where the programmer describes a sequence of instructions, in other words the way to obtain a certain result, with declarative programming the programmer describes how the result should look like. A good example of a pure declarative language is HTML. It is used to construct web pages, declaring elements such as headings and paragraphs with tags. Declarative programming is at a much higher level of abstraction compared to imperative programming, which is closer to the machine model. One can describe complex programs with few lines of code and the low-level implementation details are abstracted. A downside is that the code can easily become convoluted and hard to understand in large programs. Some examples of pure declarative languages include: HTML, SQL, XML, CSS, LaTeX. Note that these are not Turing complete. Pure declarative programming is useful for document rendering, structured data storage and manipulation.
Declarative Functional Programming Paradigm
A very important declarative subparadigm is functional programming. With this paradigm, the programmer calls and composes functions to describe the program. Here is an example in Haskell:
add_10 x = x + 10
twice f = f . f
main = do
print $ twice (add_10) 7
We define a function add_10 that takes one parameter and adds ten to it.
We also define another function that takes a function as parameter and applies it twice.
The last line will print 27 as it first adds 10 to 7 and passes the result as parameter to a second invocation of add_10.
Functional Programming Features
With functional programming, we have first-class/higher-order functions that can be bound to identifiers and passed as parameters or returned. Loops are implemented with recursion, which is well suited for some optimisations, as well as operations such as tree traversal problems, used for example when parsing. Pure functions have no side effects on global state. It is easier to understand and reason about what they do; it is also easier to prove, test and debug, because having less state means less chances for mistakes. Some examples of functional languages are Haskell, Scala, F#, etc.
Declarative Concurrent Programming Paradigm
Some declarative languages also provide ways to describe concurrent operations. For example, Erlang provides what is called the actor model. One of the advantages of this model is a reduction in synchronisation operations, for example there is no lock. Declarative concurrent languages are useful when designing distributed applications, web services, and so on.
Other Paradigms
There are many other programming paradigms: Logic, Dataflow, Metaprogramming/Reflexive, Constraint, Aspect-oriented, Quantum, etc. A lot more information can be found here: https://en.wikipedia.org/wiki/Programming_paradigm.
Multi-Paradigm Languages
A language X is said to support paradigm Y if the language offers the possibility to program in the style defined by the paradigm. Many languages are multi-paradigm. For example, Haskell is purely functional and does not allow OO style. OCaml is mainly functional but allows OO and imperative constructs. C, C++ and many others are imperative but allow some functional idioms. For example, this is a recursive factorial implementation using C:
int fact(int x) {
if(x == 0) return 1;
return x * fact(x-1);
}
It all Boils down to Machine Code
A last thing to remember is that independently of the programming language used to build a program, the only language that the CPU understands is machine code, which is a binary representation of assembly. So in the end all programming languages compile or translate to machine code:

Summary
We have two principal categories of programming paradigms, declarative and imperative:

On the declarative side, a major subparadigm is functional programming, defined by several features including first-class and higher-order functions. Regarding imperative paradigms, we have procedural or structured programming enabled by control flow structures such as loops and functions or procedures. Adding to this the notion of object, we get the object-oriented paradigm. And adding the notion of concurrent execution flows, we get the imperative concurrent paradigm.
This is how the different parts of COMP26020 map to these paradigms:

- We will start with imperative procedural programming in C.
- After that we will study compilation, the process of transforming the textual sources of programs written in various languages (e.g., C) into the machine code that is eventually executed on the CPU.
- Then we will cover object-oriented programming with C++.
- Next we will see functional programming, with Haskell.
- Finally, we will see concurrent programming with a language named Solidity.
Dummy Exercise
There is no exercise for the programming paradigm part of the unit. However, there is a dummy exercise that you should complete to make sure you can handle the automated checking tool that will be used for all the proper exercises you will need to complete in the upcoming weeks.
Installing check50
In a terminal:
pip3 install check50
echo "export PATH=$PATH:$HOME/.local/bin" >> ~/.bashrc
source ~/.bashrc
If the command fails with error: externally-managed-environment, try pip3 install --break-system-packages check50.
If the command fails with pip3: command not found, you can install pip3 on a computer for which you have admin access as follows:
sudo apt update
sudo apt install python3-pip git
You should now be able to avoid check50 from a terminal. Simply invoking it as follows should print a few guidelines about its usage:
check50
If you get a check50: command not found error, try adding pip3’s executable folder to your path. For the bash shell:
echo "export PATH=$PATH:$HOME/.local/bin" >> ~/.bashrc
source ~/.bashrc
For other models of shell (e.g. zsh) you’ll probably need to adapt this code.
Dummy Exercise
This is a dummy exercise asking you to create an empty C program. To succeed in this exercise, simply write the following program:
int main() {
return 0;
}
To check the correctness of your program, use a Linux distribution with check50 installed and write your solution in a file named sample-exercise.c.
In a terminal, with that file in the local directory, check with this command:
check50 -l --ansi-log olivierpierre/comp26020-problems/2025-2026/week1-intro/01-sample-exercise
Introduction to C
Here we do a quick introduction to the C programming language. We also learn how to write, compile and execute a few simple C programs. You can access the slides 🖼️ for this lecture. All the code samples given here can be found online, alongside instructions on how to bring up the proper environment to build and execute them here.
C: Origin
C is a relatively old programming language, it was developed in the 1970s by Dennis Ritchie, working at the time at Bell Labs. The language was originally used to develop applications running on top of the Unix operating system, developed by Ken Thompson, with Dennis Ritchie among others. C ended up also being used to reimplement Unix’s operating system kernel, which was originally written mostly in assembly, significantly increasing its portability across various architectures. Ritchie and Thompson received the Turing Award in 1983 for their contributions to operating systems, and in particular for the development of Unix. On the picture below you can see Thompson on the left and Ritchie on the right:

C: Popularity
C is still today one of the most favoured programming languages. It can be found in the top-10 of most programming languages popularity indexes (e.g. TIOBE, RedMonk, or PYPL).
The graph below is taken from the RedMonk page, and presents the popularity rank of languages on Stack Overflow on the Y axis, and the popularity rank on GitHub on the X axis: C is up there in the top right corner.
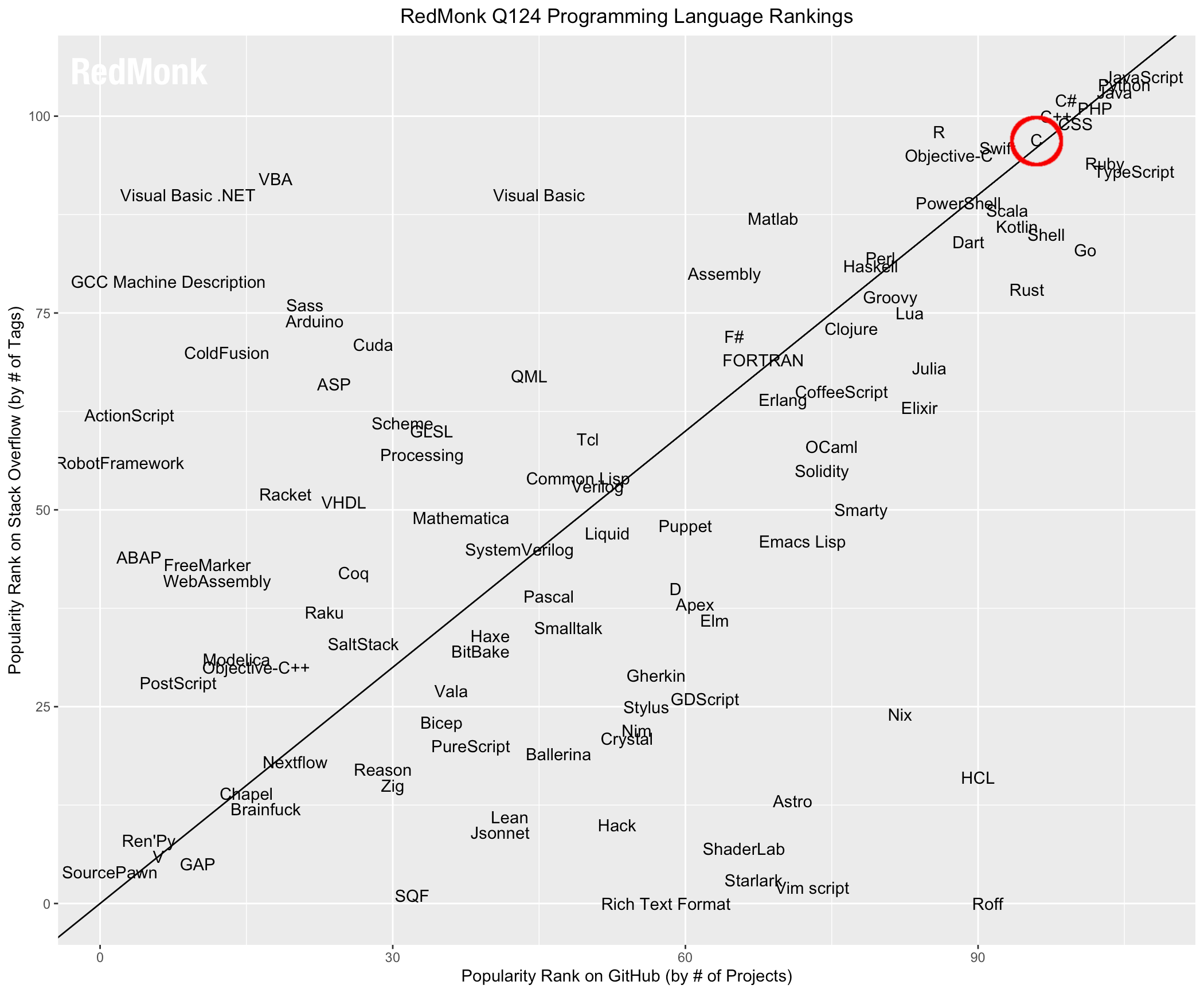
C: Characteristics
In terms of pros, C has a very simple and extremely popular syntax. Many newer languages such as Java or Go take much inspiration from the syntax of C. C is also a low-level language that efficiently maps to machine code and integrates well with assembly. It gives a high degree of control over the hardware, for example contrary to many languages C lets the programmer write at arbitrary virtual addresses in memory. Because of its simplicity C is also very fast, and also allows programs to have a low memory footprint. This all comes at a relatively high cost which is a very large area to make mistakes, resulting from the high degree of control over the hardware. The compiler will not catch every mistake. And some errors may lead to undefined behaviour that is sometimes hard to debug. Still, the benefits may make it the default programming language in many domains, including systems software such as operating systems or virtual machine monitors, but also high performance computing, embedded systems, among others.
Popular Software Written in C
A lot of extremely popular software is written in C:

Examples include:
- The Linux kernel, the most popular OS in HPC, cloud/servers, embedded systems
- The Xen hypervisor, one of the most popular virtual machine monitors.
- The GNU Libc standard library, used by most programs in many Linux distributions to interface with the OS.
- Apache, NGINX, and Redis, that are among the most popular web / key-value store servers.
- Git, which is by far the most popular version control system.
Programming Mistakes in C
Programming mistakes are quite common in C, and can lead to:
- Compilation failing: the C compiler used to transform sources into executables can detect many errors and will refuse to build any program that contains clear programming mistakes.
- Crashes: the fact that a C program builds does not mean it is correct. Crashes at runtime can be annoying but at least it is clear that something is wrong and that the program needs to be fixed.
- Program misbehaving: this is also generally a clear indication that something needs to be fixed.
- Hard to reproduce bugs: certain crashes or forms of program misbehaviour can be hard to reproduce because they require very specific execution conditions. So it is not uncommon for certain bugs to require running the program for a very long time or a very high number of times to trigger the bug. The problem with these bugs is that without proper testing the developers can simply miss it.
- Security vulnerabilities: certain bugs lead to more dire consequences than crashes/misbehaviour, and can be exploited by attackers to take over the program or the computer it executes upon, leak critical data, etc.
Why Learn C Today?
It is still very relevant to learn C today. As we have seen, it is still the default programming language in many different domains. C is also not going anywhere anytime soon: there is an enormous amount of existing/legacy C codebases, and it is likely that we will need programmers with knowledge of C for decades.
Also, because of certain characteristics of the language, learning C will have beneficial side effects on your knowledge:
- Because of its proximity to the hardware, learning C and how a C program executes helps to understand how a computer works.
- C has established an extremely popular syntax, and learning C will make it easier to learn the many other languages sharing that syntax (e.g. Java).
Hello World in C
This C program simply writes hello world to the console, also named the standard output:
#include <stdio.h>
int main() {
printf("hello, world!\n");
return 0;
}
Before studying it more in detail we can build and run it on the Linux command line as follows:
$ gcc listing1.c -o listing1
$ ./listing1
hello, world!
The first line with #include allows us to get access to functions from external libraries.
We need the printf function from stdio.h to be able to print to the standard output.
Next we have a function named main.
In C functions are implemented as follows.
We first have the return type, here int, followed by the function name, main.
Then between braces we have the function body, containing the function’s code.
In C main represents the program’s entry point, i.e. the first function to run when the program is launched.
main’s body is composed of two statements.
In C statements end with a semicolon.
The first statement is a function call: the printf function is called with a parameter between parentheses.
printf is used to print something on the standard output, and that something is passed as a parameter.
It is a character string, delimited by double quotes.
'\n' is a special character defining a carriage return.
Finally, the second statement uses the return keyword that returns from the current function to the calling context.
We return the integer value zero, a common return code indicating successful execution.
Because we return from main, this actually triggers the exit of the program with return code 0.
Compilation
The compilation is the process of creating an executable program from the source code:

For this we use a tool named the compiler. The C compiler we will use is named the GNU C compiler, GCC.
A compiler takes the source code as input, here it’s listing1.c.
It generates the machine code ready for execution on the CPU and puts it into an executable, here listing1.
.c is a common file name extension for C source code.
Executables generally don’t have a file name extension on Linux.
Concretely, we call the compiler as follows on the command line: gcc, followed by the name of the source file listing1.c, followed by -o to indicate the name of the output program, listing1:
$ gcc listing1.c -o listing1
Compilation: Warnings and Errors
The compiler will check and report some programming mistakes. There are two levels of issues reported by the compiler:
- An error is unrecoverable, and the compilation process will stop upon detecting it
- On the other hand, warnings may or may not be indicative of an issue and the compilation continues.
Compilers are very advanced today and warnings are almost always indicative of an issue: they should always be fixed. An important thing to note is that when multiple issues are listed, it is important to fix them in the order they are reported, because mistakes down the list may result from the ones up the list.
Comments
Comments are annotations in the source file that will not be processed by the compiler. It is important for a programmer to comment code a bit to explain what it does: for other people to understand his/her code, but also for himself/herself to dive back into complex pieces of code written a long time ago. There are two comment styles supported in C:
/* style 1 */
// style 2
Everything that is between the /* and */ delimiters is commented.
One can also use the // to comment the rest of the line.
Variables, Types, Printing to the Console
In this lecture we talk about variables, types, and printing to the console in C. You can access the slides 🖼️ for this lecture. All the code samples given here can be found online, alongside instructions on how to bring up the proper environment to build and execute them here.
Variables
Here is an example of C code with a main function using a local variable named a:
#include <stdio.h>
int main() {
int a; // declare a of type int (signed integer)
a = 12; // set the value of a to 12
printf("a's value: %d\n", a); // print the value of a
return 0;
}
The variable is set to 12 and then printed to the standard output.
Variables have a name, here it is a.
Variables also have a type, here it is int, corresponding to a signed integer.
Finally, variables have a value, which can generally evolve as the program executes.
Before being able to use a variable, it must first be declared.
A variable declaration is a statement defining the name and type of the variable.
Here we declare a in the first line of code of the main function.
In C, a variable name should start with a letter or underscore and contain a combination of letters, underscores, and numbers.
Try to be descriptive; for example, sum or final_balance2 are much more meaningful than just a.
Using Variables
Here are a few examples of variables usage:
int a; int b; int c;
int d = 12; // declare and set
int x, y = 10, z = 11;
a = 12; // set a to 12
b = 20; // set b to 20
c = 10 + 10; // set c to 20
a = b; // a = 20
d++; // d = d + 1
y *= 2 // y = y * 2;
We first declare 3 integers a, b and c.
A variable can be declared and set in one statement, this is what happens to d.
On the third line we declare x, y and z and we also set the value of y to be 10 and the value of z to be 11.
On the code on the right we have an example of arithmetic operation, setting the value of c to be 10+10.
We also set the value of a to be the value of b.
We also have some nice shortcuts for commonly‑used operations.
For example, by using d++ we effectively increment d by 1.
Also, y *=2 corresponds to multiplying y by 2 and storing the result in y.
There is a similar construct for addition, subtraction and division.
Types
Each variable must have a type. Types are used by the compiler to do two things. First, the compiler performs some checks on the operations realised on the variable. For example, in some cases it can warn about overflows when trying to store a number larger than the size of the target variable type. Second, allocates the memory space for the variable. Each type defines a given size in bytes for this.
Types Define Data Storage Size in Memory
At runtime one can see the program’s memory as a gigantic array of bytes.
As an example, the int type, on the x86-64 architecture that most of our laptop/desktop computers are using, is 4 bytes long.
So the compiler reserves 4 bytes in memory when declaring e.g. int a.
That memory will be used to store a’s value at runtime:

Primitive Types
Beyond int, other basic types (named primitive types) include characters (char) and floating point numbers (float for single‑and double for double‑precision).
We can describe a constant character in the code, here x, with single quotes.
When performing an arithmetic operation on an integer and a float, the compiler will promote the result to a float (same for double).
For example, float_res will include a decimal part:
int int1 = 2, int2 = 4;
float float1 = 2.8;
// when mixed with floats in arithmetics, integers are promoted to floats:
float float_res = int1 + float1;
float float_res2 = int1 * (float1 + int2);
// when stored in an integer variable, floats are _truncated_:
int int_res = int1 * (float1 + int2);
Note the use of the parentheses to set the order of evaluation in the second example, setting float_res2.
Even if the right‑hand side is promoted to a float in the assignment of int_res, because of its type (int), the result will be truncated.
More Types, Qualifiers
When declaring a variable, we use a combination of a type and optional qualifiers, that will define what the variable can hold and how much space is reserved. It is very important to be aware of the storage size of variables, as things like overflows can have very nasty consequences. Here are a few examples with the information that the C standard^[https://en.wikipedia.org/wiki/C_data_types] gives about the corresponding storage sizes:
short int a; // signed, at least 16 bits: [-32,767, +32,767]
int b; // signed, at least 16 bits: [-32,767, +32,767]
unsigned int c; // unsigned: [0, +65,535]
long int d; // at least 32 bits: [-2,147,483,647, +2,147,483,647]
unsigned long int e; // unsigned: [0, +4,294,967,295]
long long int f; // at least 64 bits: [-9x10^18, +9x10^18]
long long unsigned int g; // unsigned: [0, +18x10^18]
float h; // storage size unspecified, generally 32 bits
double i; // storage size unspecified, generally 64 bits
For example int is signed (i.e. it can hold positive as well as negative integers) and should be at least 2 bytes, so it can store numbers from -32,767 to 32,767.
unsigned int has the same size and is unsigned, so it can store more, but only positive, numbers.
Note that the storage size information coming from the standard is rather imprecise.
The actual sizes depend on the architecture of the CPU the program is compiled to execute upon.
sizeof
To get the exact storage size we can use the sizeof function, which takes a type as parameter and returns its storage size in bytes:
int so_short = sizeof(short int);
int so_int = sizeof(int);
int so_uint = sizeof(unsigned int);
int so_long = sizeof(long int);
int so_longlong = sizeof(long long int);
int so_float = sizeof(float);
int so_double = sizeof(double);
printf("size of short: %d bytes\n", so_short);
printf("size of int: %d bytes\n", so_int);
printf("size of unsigned int: %d bytes\n", so_uint);
printf("size of long int: %d bytes\n", so_long);
printf("size of long long int: %d bytes\n", so_longlong);
printf("size of float: %d bytes\n", so_float);
printf("size of double: %d bytes\n", so_double);
On the Intel x86-64 architecture:
- The size of
shortis 2 bytes. - The size of
int,unsigned intas well asfloatare 4 bytes. - The size of
long,long long int, anddoubleare 8 bytes.
In memory things look like that:

Printing to the Terminal
We have been using printf to print a lot of things to the console, let’s see how it works in more detail.
It takes one or more arguments:
printf(<format string>, <variable1>, <variable2>, etc.);
The first argument is the format string containing the text to print as well as optional markers that will be replaced with variables’ values. The next arguments are optional; it is the list of variables whose value needs to be printed, 1 variable per argument. The format string marker to use depends on the corresponding variable type. A few examples:
int int_var = -1;
unsigned int uint_var = 12;
long int lint_var = 10;
float float_var = 2.5;
double double_var = 2.5;
char char_var = 'a';
char string_var[] = "hello";
printf("Integer: %d\n", int_var);
printf("Unsigned integer: %u\n", uint_var);
printf("Long integer: %ld\n", lint_var);
printf("Float: %f\n", float_var);
printf("Double: %lf\n", double_var);
printf("Characters: %c\n", char_var);
printf("String: %s\n", string_var);
printf("Several variables: %d, %lf, %s\n", int_var, double_var, string_var);
Various markers are illustrated in that example:
%dis used for signed integers,%ufor unsigned ones.%lis used to indicate thelongqualifiers, for example we have%ldfor asigned long int.%fis used for floats and%lffor doubles.- Finally, notice the declaration of a string with the brackets for the variable name and the double quotes for the string itself.
We can print it with %s.
Arrays, Strings, Command Line Arguments
Here we consider arrays, strings and command line arguments in C. You can access the slides 🖼️ for this lecture. All the code samples given here can be found online, alongside instructions on how to bring up the proper environment to build and execute them here.
Arrays
Arrays are declared with a statement starting with the type, followed by the name of the array variable, then between brackets the size of the array, here 4 elements:
int array[4];
We can write something into an array slot using the assignment operator, the equals sign, and the index inside brackets. For example here we write 10 in the first slot and 20 in the second one:
array[0] = 10;
array[1] = 20;
In C the indexing starts at 0, i.e. the first slot is index 0. We read a slot by indicating its index inside brackets. For example, here we read the second slot:
int x = array[1];
Something important to note is that arrays are stored contiguously in memory.
Remember on x86‑64 the size of int is 4 bytes.
So in memory, for our array of 2 elements, we have 2 × 4 = 8 contiguous bytes holding the array’s data:

Multi-Dimensional Arrays
Arrays can be of multiple dimensions. To declare such an array we can use several pairs of square brackets. For example to declare a 3 by 2 array:
int my_2d_array[3][2];
We also refer to particular slots with pairs of square brackets:
my_2d_array[0][0] = 0;
my_2d_array[0][1] = 1;
my_2d_array[1][0] = 2;
my_2d_array[1][1] = 3;
my_2d_array[2][0] = 4;
my_2d_array[2][1] = 5;
This is for a 2 dimensional array, but there can be more e.g. int array[2][2][2].
Arrays are still laid out contiguously in memory with the last dimension first, so we have my_2d_array[0][0], followed by my_2d_array[0][1], followed by my_2d_array[1][0], and so on:

Arrays: Static Initialisation
Rather than initialising the array after its declaration, we can also initialise it with its declaration. This is called static initialisation. With it, it is possible to omit the size of the first dimension, as shown in this example:
int array[] = {1, 2, 3, 4, 5};
int array_2d[][2] = {{1, 2}, {3, 4}, {5, 6}};
Here we create and initialise a one‑dimensional array with 5 slots, and a two‑dimensional array of size 3 by 2.
Character Arrays: Strings
In C a string is simply a character array that is terminated with a special character, '\0', marking the end of the string.
This character is used by many functions to know where a given string ends.
For example when we call printf on a string, it prints on the console all the characters of the array until it encounters the termination character.
We can declare a string like an array.
It can be done statically, and we use the double quotes to indicate a string:
char string1[6] = "hello";
char string2[] = "hello";
The compiler will automatically include the termination character for these.
However, be careful to account for it when setting the size of the array; even if "hello" only has five characters, we need a sixth for the \0.
We can also fill an array after its declaration:
string3[0] = 'h';
string3[1] = 'e';
string3[2] = 'l';
string3[3] = 'l';
string3[4] = 'o';
string3[5] = '\0'; // Important here
When a string is created in such a way, the termination character needs to be added manually. In memory, the string is represented as follows:

Command Line Arguments
Command line arguments are strings passed on the command line when we invoke a program, separated with spaces.
For example here we execute the program gcc with three arguments: test.c, -o, and program:
$ gcc test.c -o program
Command Line Arguments: argc and argv
The main function can be declared with two parameters:
argc, an integer indicating the number of command line arguments.argv, a bi‑dimensional character array, in other words an array of strings, that contains the arguments.
Here is an example of a simple program simply printing the number of command line arguments and the first 3 of these arguments:
int main(int argc, char **argv) { // 'char ** argv' means 'char argv[][]'
printf("Number of command line arguments: %d\n", argc);
// This is a bit dangerous...
printf("argument 0: %s\n", argv[0]);
printf("argument 1: %s\n", argv[1]);
printf("argument 2: %s\n", argv[2]);
return 0;
}
Don’t be scared by the ** before argv; it is just another way to declare a two‑dimensional character array: char ** argv is the same as char argv[][].
This program is not ideal: what happens if this code is called with fewer than three arguments? We get a memory error. The program attempts to print command line arguments that do not exist, and leaks on the standard output strange values from its memory. That’s quite dangerous; there could be sensitive things like a password in there. We’ll remediate this in the next lecture regarding control flow.
String to Integer Conversion
Command line arguments are strings, so if numbers are passed they need to be converted.
This can be done with the atoi function.
To use it, stdlib.h needs to be included:
#include <stdio.h>
#include <stdlib.h> // needed for atoi
/* Sum the two integers passed as command line integers */
int main(int argc, char **argv) {
int a, b;
// Once again, dangerous!
a = atoi(argv[1]);
b = atoi(argv[2]);
printf("%d + %d = %d\n", a, b, a+b);
return 0;
}
To convert a string to a double there is atof.
Conditionals and Loops
In this lecture we discuss different control flow statements in C: conditionals, loops, and functions. You can access the slides 🖼️ for this lecture. All the code samples given here can be found online, alongside instructions on how to bring up the proper environment to build and execute them here.
Conditionals
To create a conditional we use the if statement.
If the condition within the parentheses is true, the code within the braces will be executed.
If the condition is false, the if body is not executed and execution resumes right after.
This will call printf only if x is equal to 50:
if (x == 50) {
printf("The value of x is 50\n");
}
We can use else to define a block of code that is executed only if the condition is false:
if (x == 50) {
printf("The value of x is 50\n");
} else {
printf("The value of x is not 50\n");
}
We can chain the if statements as follows:
if(x < 50) {
printf("The value of x is strictly less than 50\n");
} else if (x == 50) {
printf("The value of x is exactly 50\n");
} else {
printf("The value of x is strictly more than 50\n");
}
On this example, only one of the three printf statements will be executed depending on the value of x.
To write the condition one can use various operators.
Note the use of == for the equality.
Do not mix it with the assignment operator =, this can produce nasty bugs.
Inequality can be checked with !=.
Writing the Condition
There is no boolean type per se in C.
A condition is false if it evaluates to 0.
And it is true if it evaluates to anything but 0.
We have the following boolean operators: && (logical AND), || (logical OR), as well as the negation !.
Here are a few examples of usage:
int one = 1;
int zero = 0;
if (one) { /* will take this branch */}
if (zero) { /* won't be taken */}
if (!one) { /* won't take */}
if (one || zero) { /* will take */ }
if (one && zero) { /* won't take */ }
if (one && zero || one && zero) { /* won't take, && evaluated before || */ }
if (one && (one || zero)) { /* will take */}
The negation operator ! is placed before the expression one wants to negate.
The || and && operators are used between two expressions.
Be careful about operator precedence, which is the order of priority of evaluation.
The negation ! has the highest priority, then comes &&, then ||.
To modify the evaluation order we can use parentheses.
Switch Statement
When one has to write a long if … else chain checking a given integer value, the switch statement is useful.
We put the condition to evaluate, or a variable, after the switch between parentheses.
Then we write a series of case blocks where the execution will jump according to the condition value:
switch(x) {
case 1:
printf("x is 1\n");
break;
case 2:
printf("x is 2\n");
break;
case 3:
printf("x is 3\n");
break;
default:
printf("x is neither 1, nor 2, nor 3\n");
}
For example, here let us assume x is equal to 2.
The code will jump to case 2, execute the printf statement.
When encountering a break statement, the code will exit the switch.
It is important not to forget breaks, otherwise all the cases below the one taken will be executed.
There is a special case named default that is taken if none of the other match.
Note that the switch’s condition needs to evaluate to an integer.
While Loop
The while loop keeps executing its body as long as a given condition is true.
In this first example the code will keep printing and decrement x as long as x is superior to 0:
int x = 10;
while (x > 0) {
printf("x is %d\n", x);
x = x - 1;
}
There are two flavours of the while loop. The first, corresponding to the example above, in which the condition is checked before entering the loop:
while(/* condition */) {
/* body */
}
And the other with do …while, where the condition is checked after the loop body:
do {
/* body */
} while (/* condition */);
The following code is an infinite loop; the condition is always true:
while(1) {
printf("hello\n");
}
If a program gets stuck, one can type ctrl + c to kill it.
For Loop
Very often we use some kind of iterator within a loop.
The for loop is perfect for that.
In the header of the loop there are 3 things separated by semicolons:
- An initial statement executed once at the beginning of the loop.
- A condition checked before each iteration of the loop.
- If true, the loop continues; if false, it exits.
And a last statement executed after each iteration, generally used to update the iterator.
In this example we set i to 0 before starting the loop, which runs for as long as i is inferior to 10:
for(int i = 0; i<10; i = i + 1) {
printf("i is %d\n", i);
}
After each iteration, we increment i by one.
break and continue
The break statement within a for or while loop body directly exits the loop.
In this example the loop will iterate until i reaches 5:
for(int i = 0; i < 10; i = i + 1) {
printf("iteration %d\n", i);
if(i == 5) {
break;
}
}
The continue statement within a for or while loop body jumps directly to the next iteration.
In this example we print all numbers from 0 to 9, except 5:
int i = 0;
while(i < 10) {
i = i + 1;
if(i == 5) {
continue;
}
printf("iteration %d\n", i);
}
Loops and Arrays
Loops are useful for manipulating arrays. Here we fill and print an array within a loop, using the iterator as index:
int my_array[4];
for(int i=0; i<4; i = i +1) {
my_array[i] = 100 + i;
printf("index %d contains: %d\n", i, my_array[i]);
}
To iterate over a multidimensional array we can use nested loops:
int my_2d_array[3][2];
for(int i=0; i<3; i++) {
for(int j=0; j<2; j++) {
my_2d_array[i][j] = i*j;
printf("Index [%d][%d] = %d\n", i, j, my_2d_array[i][j]);
}
}
On this 3 by 2 array we use a first loop doing 3 iterations and inside a second loop doing 2 iterations.
Back on Command Line Arguments
With proper control flow instructions, we can now fix our code sample printing command line arguments from the previous lecture. Remember that with a hard‑coded number of arguments printed, we were at risk of memory errors. With a conditional we can ensure the program is called with the proper number of arguments, like in this example:
int print_help_and_exit(char **argv) {
printf("Usage: %s <number 1> <number 2>\n", argv[0]);
exit(-1);
}
/* Sum the two integers passed as command line integers */
int main(int argc, char **argv) {
int a, b;
if(argc != 3)
print_help_and_exit(argv);
a = atoi(argv[1]);
b = atoi(argv[2]);
printf("%d + %d = %d\n", a, b, a+b);
return 0;
}
Braces in Conditionals and Loops
When a conditional/loop body consists of a single statement, we can omit the braces:
if (x)
printf("x is non-null\n");
else
printf("x is 0\n");
for (int i = 0; i<10; i = i +1)
printf("i is %d\n", i);
If later more statements need to be added, one needs to put the braces back. Forgetting to do so can lead to nasty bugs:
if(one)
if(two)
foo();
else // whose else is this?
bar();
Functions
In this lecture we discuss functions. You can access the slides 🖼️ for this lecture. All the code samples given here can be found online, alongside instructions on how to bring up the proper environment to build and execute them here.
Functions
Functions have a name, zero or more parameters, each with a type and a name, and a return type.
In this example, we have a function named add_two_integers:
int add_two_integers(int a, int b) {
int result = a + b;
return result;
}
int main() {
int x = 1, y = 2;
int sum = add_two_integers(x, y);
printf("result: %d", sum);
if(add_two_integers(x, y))
printf(" (non zero)\n");
else
printf(" (zero)\n");
return 0;
}
It takes two integers as parameters named a and b.
It returns an integer which is the sum of the two parameters.
Like variables, functions must be declared before being called.
We declare the function by first writing the return value type, then the function name, followed by the parameters list between parentheses, each with its type.
We can call a function as presented in the example, passing the parameter values between parentheses.
The call evaluates to the function return value, so we can affect a variable with it or use it as a condition.
If a function does not need to return anything, void should be set for the return type.
Call by Copy
An important thing to note is that in C, function parameters are passed by copy and not by reference as it is the case in other languages such as Python.
What this means is that each function call gets its own local copy of the parameters’ values and updates the function makes to these parameters will not modify the calling context.
In the example we have x set to 10, then passed as a parameter of a function that sets this parameter to 12:
void my_function(int parameter) {
parameter = 12; // does not update x in main
}
int main() {
int x = 10;
my_function(x);
printf("x is %d\n", x); // prints 10
return 0;
}
If we print the value of x after the function call, it is still 10 because the function, when called, gets its own copy of the value of x.
We will see in a later lecture how to have a function update a variable from the calling context: this is achieved through a mechanism named pointers.
Forward Declarations
The function signature or prototype suffices for the declaration. As shown in the example, it contains the function return type, name, parameters, and simply ends with a semicolon:
/* Forward declaration, also called function _prototype_ */
int add(int a, int b);
int main(int argc, char **argv) {
int a = 1;
int b = 2;
/* Here we need the function to be at least declared -- not necessarily defined */
printf("%d + %d = %d\n", a, b, add(a, b));
return 0;
}
/* The actual function definition */
int add(int a, int b) {
return a + b;
}
The body can be declared further in the file. It can be located below statements in which the function is called. This is called a forward declaration. It gives the programmer more freedom for organising their code.
Global vs. Local Variables
Until now we only saw local variables visible only from within the context they are declared in.
On the contrary global variables are declared outside functions.
They can be read or written from everywhere in the source.
For example here global_var is set to 100 and printed in main, and it is also incremented in the add_to_global_var function:
int global_var;
void add_to_global_var(int value) {
global_var = global_var + value;
}
int main() {
global_var = 100;
add_to_global_var(50);
printf("global_var is %d\n", global_var);
return 0;
}
There are many issues with global variables. An important one is that because they can be read or written from anywhere, they make it harder to understand and reason about the program. They should be used only when needed.
Variables Scope and Lifetime
Contrary to globals, local variables are visible only within the enclosing block of code, delimited with braces. Consider this example:
int x = 12;
if(x) {
int y = 14;
printf("inner block, x: %d\n", x);
printf("inner block, y: %d\n", y);
}
printf("outer block, x: %d\n", x); // working: x is in scope
printf("outer block, y: %d\n", y); // error: y only visible in the if body
for(int i=0; i<10; i++) {
printf("In loop body, i is %d\n", i); // working, i is in scope
}
printf("Out of loop body, i is %d\n", i); // error, i only visible in loop body
int j;
for(j=0; j<10; j++) {
printf("In loop body, j is %d\n", j); // working
}
printf("Out of loop body, j is %d\n", j); // working, j in scope
While x is visible from anywhere in main, y cannot be printed there because it’s visible only within the if body.
The i iterator here is visible only in the for loop body.
For j, because it is declared in the scope of main, it is still visible after the loop finishes.
Generally, it is a good practice to try to declare local variable at the beginning of the block.
Custom Types and Data Structures
Here we cover how to create and use custom data types and structures in C. You can access the slides 🖼️ for this lecture. All the code samples given here can be found online, alongside instructions on how to bring up the proper environment to build and execute them here.
Custom Types: typedef
To create a custom alias for a type, use the typedef keyword as follows:
typedef long long unsigned int my_int; // 'my_int' is now equivalent to 'long long unsigned int'
int main(int argc, char **argv) {
my_int x = 12;
printf("x is: %llu\n", x);
return 0;
}
typedef, followed by the type to alias, here long long unsigned int, followed by the name of the alias, here my_int.
Following that, one can use my_int to refer to long long unsigned int: it is much shorter.
Custom Data Structures: struct
Custom data structures are extremely useful in C.
They aggregate several fields of various types.
They are created and manipulated with the struct keyword.
On this example we define a struct person:
#include <stdio.h>
#include <string.h> // needed for strcpy
// Definition of the struct:
struct person {
char name[10];
float size_in_meters;
int weight_in_grams;
};
void print_person(struct person p) {
/* Access fields with '.' */
printf("%s has a size of %f meters and weights %d grams\n", p.name,
p.size_in_meters, p.weight_in_grams);
}
int main(int argc, char **argv) {
// declare a variable of the struct type:
struct person p1;
// sets the variable field
p1.size_in_meters = 1.6;
p1.weight_in_grams = 60000;
strcpy(p1.name, "Julie");
struct person p2 = {"George", 1.8, 70000};
print_person(p1);
print_person(p2);
return 0;
}
It has a name, which is a character array of length 10.
A size_in_meters field which is a float.
And a weight in grams which is an int.
In the main function we declare a struct person variable p1.
We can set values in the fields with the . operator.
We do not detail strcpy here, just know that it sets Julie in the name field of p1.
We can also do static initialisation with braces followed by the fields’ values in order.
We have a print_person function that takes a struct person as parameter and prints its field values.
In memory, the fields of a struct are placed contiguously:

For our example, on x86-64 a char is one byte, so the array is 10 bytes in total.
Followed by a float which is 4 bytes.
Followed by an int which is also 4 bytes.
So one instance of our struct should be 18 bytes.
Note that the compiler may insert some padding for performance reasons.
Custom Data Structures and typedef
To avoid using the struct keyword each time we refer to a structure, typedef can be used:
struct s_person {
/* fields declaration ... */
};
typedef struct s_person person;
void print_person(person p) { /* ... */}
int main(int argc, char **argv) {
person p1;
person p2 = {"George", 1.8, 70000};
/* ... */
}
After the struct declaration, use typedef followed by the name of the struct, here s_person, followed by the name of the alias, here person.
And now one can just use person.
A faster method to do so is to typedef during the struct declaration:
typedef struct {
/* fields declaration ... */
} person;
Enumerations
Enumerations are textual names that are mapped by the compiler to integer constants under the hood.
They are useful in situations where integers are required, for example a switch, but when textual names are more meaningful.
Here is an example: we define a colour enum with three values: RED, BLUE, and GREEN:
enum colour {
RED,
BLUE,
GREEN
};
int main(int argc, char **argv) {
enum colour c1 = BLUE;
switch(c1) {
case RED:
printf("c1 is red\n"); break;
case BLUE:
printf("c1 is blue\n"); break;
case GREEN:
printf("c1 is green\n"); break;
default:
printf("Unknown colour\n");
}
return 0;
}
We declare an enum colour variable c1 and it is set to BLUE.
Then we can use it as the condition of a switch.
Note that by convention constants are often in capital letters in C.
Same as for structs, enums can be used with typedef to avoid using the enum keyword.
So for example we simply use colour to declare c2:
enum e_colour {
BLUE,
/* ... */
};
enum e_colour c1 = BLUE; // without typedef
typedef enum e_colour colour;
colour c2 = RED;
Or, in a shorter way:
typedef enum {
BLUE,
/* ... */
} colour;
C Basics: Exercises
See here how to set up a development environment to do these exercises.
- You should complete the essential exercises if you want to claim you know how to program in C.
- If you want to go further and make sure you understand everything, you can also complete the additional exercises.
Essential Exercises
- Printing to the console
- Compilation errors
- Using variables
- Data type sizes
- Data types
- Printing a string
- Manipulating command line arguments
- Determining leap years
- Working with arrays
- Aliasing types with
typedef - Custom data structures with
struct - Enumerations with
enum
Printing to the Console
Write a C program displaying a large 11x9 characters ‘C’ using dashes. The expected output is:
######
## ##
#
#
#
#
#
## ##
######
To check the correctness of your program, use a use a Linux distribution with check50 installed and write your solution in a file named printf.c. In a terminal, with that file in the local directory, check with this command:
check50 -l --ansi-log olivierpierre/comp26020-problems/2025-2026/week2-c-basics/01-printf
Compilation Errors
The following program is supposed to print a line on the standard output, but compilation fails due to several errors:
#include <tdio.h>
void man() {
printf("This should work!\n");
retur 0;
}
Correct the program to have it display the following output:
This should work!
Hint: trying to build the program will have the compiler highlight the errors.
To check the correctness of your program, use a use a Linux distribution with check50 installed and write your solution in a file named compilation-errors.c.
In a terminal, with that file in the local directory, check with this command:
check50 -l --ansi-log olivierpierre/comp26020-problems/2025-2026/week2-c-basics/02-compilation-errors
Using Variables
Write a simple program declaring two variables: int_var with type int and double_var with type double. Assign a value to each of them and print their values.
The expected output is as follows:
int_var: 42
double_var: 24.000000
To check the correctness of your program, use a use a Linux distribution with check50 installed and write your solution in a file named variables.c.
In a terminal, with that file in the local directory, check with this command:
check50 -l --ansi-log olivierpierre/comp26020-problems/2025-2026/week2-c-basics/03-variables
Data Type Sizes
Write a simple program printing the size of int variables, followed on the next line by the size of double variables, followed on a third line by the size of unsigned long long int variables.
On a last line, print the value of the multiplication of these 3 sizes. The expected output (on a modern 64 bits machine) is:
4
8
8
256
To check the correctness of your program, use a use a Linux distribution with check50 installed and write your solution in a file named sizes.c.
In a terminal, with that file in the local directory, check with this command:
check50 -l --ansi-log olivierpierre/comp26020-problems/2025-2026/week2-c-basics/04-sizes
Data Types
The following code fails to compile due to a missing variable declaration:
#include <stdio.h>
int main() {
variable = 10;
printf("variable is %u\n", variable);
return 0;
}
Edit the code to have it compile and run successfully. The expected output is:
variable is 10
To check the correctness of your program, use a use a Linux distribution with check50 installed and write your solution in a file named types.c.
In a terminal, with that file in the local directory, check with this command:
check50 -l --ansi-log olivierpierre/comp26020-problems/2025-2026/week2-c-basics/05-types
Printing a String
The following program is supposed to print hi there on the standard output and exit:
#include <stdio.h>
int main(int argc, char **argv) {
char string[8];
string[0] = 'h';
string[1] = 'i';
string[2] = ' ';
string[3] = 't';
string[4] = 'h';
string[5] = 'e';
string[6] = 'r';
string[7] = 'e';
string[8] = '\n';
printf("%s\n", string);
return 0;
}
However, when compiled and executed it prints additional garbage values:
gcc string.c -o string
./string
hi there
�Fy+V
Modify the program so that it produces the expected output:
hi there
The string should still be created in the code in a character by character basis, i.e. solutions using char string[] = "hi there" will not be accepted.
To check the correctness of your program, use a use a Linux distribution with check50 installed and write your solution in a file named string.c.
In a terminal, with that file in the local directory, check with this command:
check50 -l --ansi-log olivierpierre/comp26020-problems/2025-2026/week2-c-basics/06-string
Manipulating Command Line Arguments
Write a C program that takes 3 floating point numbers as command line parameters and displays on the standard output the value of the multiplication of these 3 numbers. Examples of execution:
./cmdline 1.0 2.0 3.0
6.000000
./cmdline 1.45 2.78 3.25
13.100750
Warning. Use the type
doublerather thanfloatto hold these values in order to pass the checks.
To check the correctness of your program, use a use a Linux distribution with check50 installed and write your solution in a file named cmdline.c.
In a terminal, with that file in the local directory, check with this command:
check50 -l --ansi-log olivierpierre/comp26020-problems/2025-2026/week2-c-basics/07-cmdline
Determining Leap Years
Write a C program taking a year as command line parameter and printing out on the standard output if this year is leap or not.
To determine if a year is leap, you can use the following algorithm (taken from Wikipedia):
if (year is not divisible by 4) then (it is a common year)
else if (year is not divisible by 100) then (it is a leap year)
else if (year is not divisible by 400) then (it is a common year)
else (it is a leap year)
The output format should be as described in these examples:
./leap 2000
2000 is a leap year
./leap 2100
2100 is not a leap year
To check the correctness of your program, use a use a Linux distribution with check50 installed and write your solution in a file named leap.c.
In a terminal, with that file in the local directory, check with this command:
check50 -l --ansi-log olivierpierre/comp26020-problems/2025-2026/week2-c-basics/08-leap
Working with Arrays
Write a program that takes up to 10 integers as command line parameters.
These parameters are converted to integer types into an array of int named array.
Then, the program sorts the array by increasing value and prints the result as follows:
./array 5 4 6 2 1 3
1 2 3 4 5 6
./array 5 5 120
5 5 120
To check the correctness of your program, use a use a Linux distribution with check50 installed and write your solution in a file named array.c.
In a terminal, with that file in the local directory, check with this command:
check50 -l --ansi-log olivierpierre/comp26020-problems/2025-2026/week2-c-basics/09-array
Aliasing Types with typedef
The program below prints the dimensions of a rectangle passed from the command line arguments:
#include <stdio.h>
#include <stdlib.h>
struct s_rectangle {
unsigned long long int width;
unsigned long long int length;
};
void print_rectangle(struct s_rectangle r) {
printf("Rectangle is %llu x %llu\n", r.width, r.length);
}
int main(int argc, char **argv) {
struct s_rectangle r;
unsigned long long int width;
unsigned long long int length;
if(argc == 3) {
width = atoll(argv[1]);
length = atoll(argv[2]);
r.width = width;
r.length = length;
print_rectangle(r);
}
return 0;
}
Modify this program to use typedef to alias:
struct s_rectangleintorectangleunsigned long long intintoull
To check the correctness of your program, use a use a Linux distribution with check50 installed and write your solution in a file named typedef.c.
In a terminal, with that file in the local directory, check with this command:
check50 -l --ansi-log olivierpierre/comp26020-problems/2025-2026/week2-c-basics/10-typedef
Custom Data Structures with struct
Consider the following structure:
struct timestamp {
unsigned int hour;
unsigned int minute;
unsigned int second;
}
Using this structure, write a C program adding two timestamps and displaying the result on the standard output.
The program takes 6 command line parameters corresponding to the two timestamps.
The addition is realised in a function named add_timestamps that takes 2 timestamp parameters and return the sum as a timestamp.
Here are some output examples:
# 5h11m44s + 12h30m3s = 17h41m47s
./timestamp 5 11 44 12 30 3
17 41 47
# 10h30m50s + 1h5m15s = 11h36m5s
./timestamp 10 30 50 1 5 15
11 36 5
# 14h12m5s + 22h5m0s = 36h17m5s
./timestamp 14 12 5 22 5 0
36 17 5
To check the correctness of your program, use a use a Linux distribution with check50 installed and write your solution in a file named struct.c.
In a terminal, with that file in the local directory, check with this command:
check50 -l --ansi-log olivierpierre/comp26020-problems/2025-2026/week2-c-basics/11-struct
Enumerations with enum
The program below uses integer to represent days of the week, 0 corresponding to Monday, 1 to Tuesday, etc.
#include <stdio.h>
int main(int argc, char **argv) {
int d = 2;
printf("Today is: ");
switch(d) {
case 0:
printf("Monday\n");
break;
case 1:
printf("Tuesday\n");
break;
case 2:
printf("Wednesday\n");
break;
case 3:
printf("Thursday\n");
break;
case 4:
printf("Friday\n");
break;
case 5:
printf("Saturday\n");
break;
case 6:
printf("Sunday\n");
break;
default:
printf("Unknown day...\n");
}
return 0;
}
Replace the use of integers with that of an enumeration named enum day, defining constants for days: MONDAY, TUESDAY, etc.
The expected output is:
./enum
Today is: Wednesday
To check the correctness of your program, use a use a Linux distribution with check50 installed and write your solution in a file named enum.c.
In a terminal, with that file in the local directory, check with this command:
check50 -l --ansi-log olivierpierre/comp26020-problems/2025-2026/week2-c-basics/12-enum
Additional Exercises
- More on arrays
- Computing factorials
- Printing a right-angled triangle
- Printing an isosceles triangle
- More on
enum
More on Arrays
Write a program that takes up to 10 integers as command line parameters.
These parameters are converted to integer types into an array of int named array.
Then, the program iterates over the array and outputs if each number is even or odd as follows:
./array2 1 2 3 4 5 6
1 is odd
2 is even
3 is odd
4 is even
5 is odd
6 is even
./array2 5 5 120
5 is odd
5 is odd
120 is even
Modulo in C. The modulo operator in C is
%, for example:42 % 2evaluates to0and41 % 2evaluates to1.
To check the correctness of your program, use a use a Linux distribution with check50 installed and write your solution in a file named array2.c.
In a terminal, with that file in the local directory, check with this command:
check50 -l --ansi-log olivierpierre/comp26020-problems/2025-2026/week2-c-basics/13-array2
Computing Factorials
Write a C program taking an integer as command line parameter and displaying the factorial of that integer on the standard output as follows:
./factorial 10
10! = 3628800
./factorial 15
15! = 1307674368000
./factorial 1
1! = 1
We assume that the parameter value can be up to 20, the maximum number which factorial can be stored in a 64 bits unsigned integer.
To check the correctness of your program, use a use a Linux distribution with check50 installed and write your solution in a file named factorial.c.
In a terminal, with that file in the local directory, check with this command:
check50 -l --ansi-log olivierpierre/comp26020-problems/2025-2026/week2-c-basics/14-factorial
Printing a Right-Angled Triangle
Write a C program taking an integer as parameter and printing a right-angled triangle on the command line which legs size is defined by the integer parameter. Here are some examples of execution:
./triangle 2
*
**
./triangle 5
*
**
***
****
*****
./triangle 15
*
**
***
****
*****
******
*******
********
*********
**********
***********
************
*************
**************
***************
To check the correctness of your program, use a use a Linux distribution with check50 installed and write your solution in a file named triangle.c.
In a terminal, with that file in the local directory, check with this command:
check50 -l --ansi-log olivierpierre/comp26020-problems/2025-2026/week2-c-basics/15-triangle
Printing an Isosceles Triangle
Write a C program taking an odd integer n as parameter and printing an isosceles triangle on the standard output, with the triangle’s base length being defined by n.
Example of execution are:
./triangle 3
*
**
*
./triangle 5
*
**
***
**
*
./triangle 15
*
**
***
****
*****
******
*******
********
*******
******
*****
****
***
**
*
When the integer parameter n is even, the program corrects it to the next odd number by simply incrementing it.
To check the correctness of your program, use a use a Linux distribution with check50 installed and write your solution in a file named triangle2.c.
In a terminal, with that file in the local directory, check with this command:
check50 -l --ansi-log olivierpierre/comp26020-problems/2025-2026/week2-c-basics/16-triangle2
More on enum
Enumerations can be used in C in combination with bitwise operations to define flags, i.e. set of properties attached to objects, each object being able to have 0 or several properties enabled.
Consider the following program:
#include <stdio.h>
typedef enum {
/* define FLAG1, FLAG2, FLAG3, FLAG4 */
} flags;
void print_flags(flags f) {
if(f & FLAG1)
printf("FLAG1 enabled\n");
if(f & FLAG2)
printf("FLAG2 enabled\n");
if(f & FLAG3)
printf("FLAG3 enabled\n");
if(f & FLAG4)
printf("FLAG4 enabled\n");
}
int main(int argc, char **argv) {
flags f1 = FLAG1 | FLAG2;
flags f2 = FLAG1 | FLAG2 | FLAG3;
printf("f1:\n");
print_flags(f1);
printf("f2:\n");
print_flags(f2);
return 0;
}
The goal of the exercise is to write the definition of flags so that the program behaves correctly, i.e. it should produce the following output:
./enum2
f1:
FLAG1 enabled
FLAG2 enabled
f2:
FLAG1 enabled
FLAG2 enabled
FLAG3 enabled
Custom typedef values. Within a
typedefdefinition, use=to set a particular integer value for an identifier, for exampleFLAG1 = 42,
Bitwise operations in C. C offers operators working on the bitwise representation of variables:
- bitwise AND:
&and OR|- bitwise shift, left
<<and right>>- etc. For more information see the Bitwise logic and shifts operators sections here
To check the correctness of your program, use a use a Linux distribution with check50 installed and write your solution in a file named enum2.c.
In a terminal, with that file in the local directory, check with this command:
check50 -l --ansi-log olivierpierre/comp26020-problems/2025-2026/week2-c-basics/17-enum2
Introduction to Pointers
Here we introduce a fundamental concept in C, pointers. You can access the slides 🖼️ for this lecture. All the code samples given here can be found online, alongside instructions on how to bring up the proper environment to build and execute them here.
Program Memory Layout
Before explaining what a pointer is, it’s important to understand how the memory that is accessible to a program looks like. All the data manipulated by a program, as well as all the code it executes, is present somewhere in memory. The area of memory that is accessible for the program to read, write and execute is called the address space.
One can see the address space as a very large array of contiguous bytes:

Each byte has an index into this array, named an address. Addresses range from 0 to the maximum addressable byte. On x86-64 the kernel configures virtual memory from address 0 to 128 TB to be accessible by each program. Note that this is virtual memory, so each program has its own copy of that array. Its size is also completely independent of the actual physical memory in the machine.
The address space is generally very sparse and only the bytes that are read/written are mapped to physical memory.
Finally, note that we generally use hexadecimal numbers, prefixed with 0x, to indicate addresses as they can be pretty big.
Addresses
Recall that all code executed and data manipulated by the program reside in memory.
Each variable has an address which is the first byte of location in memory.
We can get the address of a variable in C with the & operator.
int glob = 12;
char string[] = "abcd";
typedef struct {
int member1;
float member2;
} mystruct;
int main(int argc, char **argv) {
mystruct ms = {1, 2.0};
// With modern processors an address is a 64 bits value, so we need the
// right format specifier: `%lu` or `%lx` if we want to print in hexadecimal
printf("ms address is: 0x%lx, glob address is 0x%lx\n", &ms, &glob);
return 0;
}
Note the use of the marker %lx: an address is 64 bits on modern processors, so it’s a long, and we use x to specify printing in hexadecimal.
If this program outputs that ms address is: 0x123, glob address is 0x330, and if we assume that string is located somewhere else, say at 0x2f0, we can represent the in‑memory layout for these variables as follows:

Pointers
A pointer is simply a variable that holds an address, possibly the address of another variable.
We can declare a pointer by indicating the type of the pointed variable, followed by *, and then the name of the pointer.
For example here we create a pointer named ptr that holds the address of v:
int v = 42;
int *ptr = &v; // ptr holds the address of v, i.e. v's location in memory
A pointer is itself a variable, and because it holds an address its size is equal to that of the address bus: with modern 64‑bit architectures, the size of pointers is 64 bits.

Dereferencing a Pointer
An important feature of pointers is that one can access the pointed value through the pointer, with an operation called dereferencing the pointer.
We can read or write this value with the * operator:
int v = 42;
int *ptr = &v;
printf("pointer value: 0x%lx\n", ptr);
printf("pointed value: %d\n", *ptr);
Through ptr one can read or write the value of v.
In the example, in the second printf we read v’s value with *ptr, which evaluates to the value of v.
It is an int so we use %d to print it.
Here is a further example where we have 3 pointers to int, double, and a data structure variable:
int glob = 12;
double glob2 = 4.4;
typedef struct { int member1; double member2; } mystruct;
int main(int argc, char **argv) {
mystruct ms = {55, 2.23};
int *ptr1 = &glob;
double *ptr2 = &glob2;
mystruct *ptr3 = &ms;
/* Print each pointer's value (i.e pointed address), and pointed value */
printf("ptr1 = %p, *ptr1 = %d\n", ptr1, *ptr1);
printf("ptr2 = %p, *ptr2 = %f\n", ptr2, *ptr2);
printf("ptr3 = %p, *(ptr3).member1 = %d, *(ptr3).member2 = %d\n",
ptr3, *(ptr3).member1, *(ptr3).member2);
}
We print the values of each pointer, i.e. the addresses of the pointed elements, and we also print the value of the pointed elements by dereferencing the pointers.
Note that it also works for data structures: *(ptr3).member1* evaluates to 55, the value of the first member of ms.
Note the use of the parentheses here: without them the . operator takes precedence on the *.
Try to reason about what would happen if one forgot the parentheses (hint: nothing is mapped at address 55 and accessing it results in a crash).

Pointers: Applications
In the previous lecture we have presented pointers, and in this one we will describe in what scenarios they can be useful. You can access the slides 🖼️ for this lecture. All the code samples given here can be found online, alongside instructions on how to bring up the proper environment to build and execute them here.
Allow a Function to Access the Calling Context
Recall that arguments are passed by copy in C. So, with arguments of regular types, a function cannot change its calling context.
void add_one(int param) {
param++;
}
int main(int argc, char **argv) {
int x = 20;
printf("before call, x is %d\n", x); // prints 20
add_one(x);
printf("after call, x is %d\n", x); // prints 20
return 0;
}
Before and after the call, x’s value is the same.
A copy of x was made upon the call to add_one.
That copy gets incremented by that function and then discarded when it returns.
Let’s illustrate what happens in memory.
Each function stores its local variables as well as arguments somewhere in memory.
We have an area for main and an area for add_one.
In main’s area we have x, and a copy of x is made upon call to add_one, in the area related to this function, in the form of the param parameter:

If we rather want add_one to increment the value of x as seen by main, i.e. we want add_one to modify the memory related to its calling context (main), we can use pointers:
void add_one(int *param) {
(*param)++;
}
int main(int argc, char **argv) {
int x = 20;
printf("before call, x is %d\n", x); // print 20
add_one(&x);
printf("after call, x is %d\n", x); // print 21
return 0;
}
We now call add_one by passing as parameter the address of x.
Let’s illustrate what happens in memory:

In main’s area we have x, let’s say it’s located at address 0x128 (we’ll use fictitious addresses for all the examples of this lecture).
In add_one’s area, when that function is called, some space is reserved for param and filled with x’s address, 0x128.
Through param, add_one now has access to x’s location in memory.
In effect, add_one can increment x by dereferencing param:

Let a Function “Return” More Than a Single Value
Pointers can be used to access the calling context when we want a function to “return” more than a single value. Here is an example in which we have a function that return both the product and the quotient of two numbers:
// we want this function to return 3 things: the product and quotient of n1 by n2,
// as well as an error code in case division is impossible
int multiply_and_divide(int n1, int n2, int *product, int *quotient) {
if(n2 == 0) return -1; // Can't divide if n2 is 0
*product = n1 * n2;
*quotient = n1 / n2;
return 0;
}
int main(int argc, char **argv) {
int p, q, a = 5, b = 10;
if(multiply_and_divide(a, b, &p, &q) == 0) {
printf("10*5 = %d\n", p); printf("10/5 = %d\n", q);
}
}
We also want it to return an error code if the divider is 0. So we have 3 things to return. The error or success code is returned normally, while the quotient and product are returned through pointers.
It works as follows: main reserves space for the quotient and product by creating two variables p and q.
Then it passes their addresses to multiply_and_divide, which performs the operations and writes the results in p and q through the pointers product and quotient.
In memory things look like that:

In practice, this is another example of a function (multiply_and_divide) modifying the memory of its calling context (main).
To generalise, with pointers a function can read or write anywhere in memory.
Inefficient Function Calls with Large Data Structures Copies
Let’s see another use case for pointers.
typedef struct {
// lots of large (8 bytes) fields:
double a; double b; double c; double d; double e; double f;
} large_struct;
large_struct f(large_struct s) { // very inefficient in terms of
s.a += 42.0; // performance and memory usage!
return s;
}
int main(int argc, char **argv) {
large_struct x = {1.0, 2.0, 3.0, 4.0, 5.0, 6.0};
large_struct y = f(x);
printf("y.a: %f\n", y.a);
}
The function takes the large_struct as a parameter, updates it, and returns it.
The data structure is large, with six fields of 8 bytes each, totalling 48 bytes on x86‑64.
We know C passes parameters by copy, so when f is called there is a first copy corresponding to f’s parameter s.
Next, f updates the struct member.
And finally there is a second copy when we return the struct into y.
In memory it looks like that:

This is very inefficient both in terms of performance and memory usage.
The two copy operations take time because the struct is large.
And in memory there are 3 instances of the struct (x, y, and s), which takes up a lot of space.
Efficient Function Calls with Pointers
We can fix that issue with a pointer.
The goal is to maintain a unique copy of the variable and update it in f though a pointer, similar to what we saw in the previous examples.
We change the parameter type to a pointer and call the function with the address of x.
In the function we dereference the pointer before accessing the field:
void f(large_struct *s) { // now takes a pointer parameter
(*s).a += 42.0; // dereference to access x
return;
}
int main(int argc, char **argv) {
large_struct x = {1, 2, 3, 4, 5, 6};
f(&x); // pass x's address
printf("x.a: %f\n", x.a);
return 0;
}
When the function is called we now have the pointer, which is a small parameter of 64 bits, i.e. 8 bytes.
Only the pointer is copied when f is called.
In f we can directly update the struct through the pointer; nothing needs to be copied or returned back to main.
It’s much more efficient; we don’t have to hold multiple copies of the large struct and there is no expensive copy operations:

C Arrays are Pointers
Under the hood, arrays are implemented as pointers in C. Arrays can be quite large, and it would be very inefficient to pass them by copy. Here is a function that takes an int pointer as parameter:
void negate_int_array(int *ptr, int size) { // function taking pointer as parameter
for(int i=0; i<size; i++) // also need the size to iterate properly
ptr[i] = -ptr[i]; // use square brackets like a standard array
}
int main(int argc, char **argv) {
int array[] = {1, 2, 3, 4, 5, 6, 7};
negate_int_array(array, 7); // to get the pointer just use the array's name
for(int i=0; i<7; i++)
printf("array[%d] = %d\n", i, array[i]);
return 0;
}
Notice at how we call it: we just put the name of an array variable. Also notice how we can use the square brackets on a pointer variable to address it like an array.
This function negates all the elements of an int array.
Indexing Arrays with Pointers, Pointer Arithmetics
Consider the following examples:
int int_array[2] = {1, 2};
double double_array[2] = {4.2, 2.4};
char char_array[] = "ab";
printf("int_array[0] = %d\n", int_array[0]);
printf("int_array[1] = %d\n", int_array[1]);
printf("*(int_array+0) = %d\n", *(int_array+0)); // pointer arithmetic!
printf("*(int_array+1) = %d\n", *(int_array+1)); // +1 means + sizeof(array type)
printf("double_array[0] = %f\n", double_array[0]);
printf("double_array[1] = %f\n", double_array[1]);
printf("*(double_array+0) = %f\n", *(double_array+0));
printf("*(double_array+1) = %f\n", *(double_array+1));
printf("char_array[0] = %c\n", char_array[0]);
printf("char_array[1] = %c\n", char_array[1]);
printf("*(char_array+0) = %c\n", *(char_array+0));
printf("*(char_array+1) = %c\n", *(char_array+1));
In memory we have the following:

The array int_array has 2 elements, each 4 bytes.
The array double_array has 2 elements, each 8 bytes.
The array char_array has 3 elements, counting the termination character, each 1 byte.
Remember that array elements are stored contiguously in memory. We can refer to each element of each array with either the square brackets or the dereference operator.
When we use the dereference operator, things work as follows: the name of an array corresponds to a pointer to its first element, so dereferencing it gives that first element.
To access the second element we increase the pointer by one element, hence the +1 before dereferencing.
Operations on pointers are called pointer arithmetic.
One must be careful with them.
The expression int_array + 1 is interpreted by the compiler as the base address of int_array plus the size of one element, and not plus one byte.
In other words, the actual number of bytes that will be added to the base address of int_array depends on the type of the elements contained in the array.
For example, each element of int_array is 4 bytes.
Each element of double_array is 8 bytes.
Each element of char_array is 1 byte.
Pointers and Data Structures
Data structures are often passed as pointers. Furthermore, structs themselves can have pointer fields.
typedef struct {
int int_member1;
int int_member2;
int *ptr_member;
} my_struct;
We can create a pointer to a previously declared struct variable:
my_struct *p = &ms;
To access one of the int members, we have two choices.
The classic * operator is used for dereferencing, followed by a dot (.) for field access.
Don’t forget the parentheses as the . takes precedence over the *.
There is also a shortcut: the arrow ->.
It can be used on a struct pointer to access a field.
The arrow first dereferences the pointer and then accesses the field:
p->int_member2 = 2; // s->x is a shortcut for (*s).x
Further, one can get the address of an individual struct member with the & operator.
Here we set the pointer field equal to the address of one of the integer fields:
p->ptr_member = &(p->int_member2);
In memory this example looks like that:

Then we can print all the members’ values and dereference the member pointer:
printf("p->int_member1 = %d\n", p->int_member1);
printf("p->int_member2 = %d\n", p->int_member2);
printf("p->ptr_member = %p\n", p->ptr_member);
printf("*(p->ptr_member) = %d\n", *(p->ptr_member));
Pointer Chains
A pointer is a variable, so it can be itself pointed to: we can create a pointer to a pointer and by doing so construct pointer chains. Consider this example:
int value = 42; // integer
int *ptr1 = &value; // pointer of integer
int **ptr2 = &ptr1; // pointer of pointer of integer
int ***ptr3 = &ptr2; // pointer of pointer of pointer of integer
printf("ptr1: %p, *ptr1: %d\n", ptr1, *ptr1);
printf("ptr2: %p, *ptr2: %p, **ptr2: %d\n", ptr2, *ptr2, **ptr2);
printf("ptr3: %p, *ptr3: %p, **ptr3: %p, ***ptr3: %d\n", ptr3, *ptr3,
**ptr3, ***ptr3);
In memory, we have a layout as follows:

Here we have a value, and we create a first pointer to it.
Then we have a second pointer pointing to the first one.
The type of this pointer of pointer is int **, which means pointer of pointer of int.
We also create a pointer of pointer of pointer to int, int ***.
Note in the code the use of several star operators for dereferencing pointers of pointers.
For example, **ptr2 means accessing the value that is pointed to by what is pointed to by ptr2.
In other words, a first * gives us access to ptr1, and a second gives us access to val.
Pointers of pointers are useful to create dynamically allocated arrays, as we will see next.
Dynamic Memory Allocation
Here we cover dynamic memory allocation, i.e. allocating memory space at runtime. You can access the slides 🖼️ for this lecture. All the code samples given here can be found online, alongside instructions on how to bring up the proper environment to build and execute them here.
Dynamic Memory Allocation: Motivation
Until now we have only worked with data that is allocated statically. This means that the amount of memory space reserved for all the variables we use is determined at compile time. But there are some scenarios in which the amount of space needed is only known at runtime. Here is an example with a program taking an integer as command line argument and allocating an array whose size is based on that number:
int main(int argc, char **argv) {
if(argc != 2) {
printf("Usage: %s <array size>\n", argv[0]);
return -1;
}
int size = atoi(argv[1]);
int array[size]; // variable-sized array
for(int i=0; i<size; i++) {
array[i] = i;
printf("array[%d] = %d\n", i, array[i]);
}
return 0;
}
size is only known at runtime and thus this is a variable‑sized array.
Variable‑sized arrays are rarely used in C because they have many downsides.
They are not supported in some versions of C.
Most importantly, they are stored on a location in memory called the stack, that has very limited space.
For example, if you run the code above with a large number for size, a memory error will occur because the stack will overflow.
We need another solution.
Program Memory Layout
Before explaining dynamic memory allocation, let’s talk a bit about how the program memory is organised. We take this example program manipulating 2 arrays:
int large_array[10000000];
int process_array(int *array, int size) { /* do some stuff with array */ }
int main(int argc, char **argv) {
int size;
/* check argc ... */
size = atoi(argv[1]);
if(size < 500) { /* Make sure small_array does not overflow the stack */
int small_array[size];
process_array(small_array, size);
}
process_array(large_array, 10000000);
return 0;
}
We have a static array (static meaning that its size is known at compile time), large_array, with a relatively large size, declared as a global variable.
And we have a variable‑sized array for which we make sure that the size is not too big.
In memory, there is an area named the static memory that contains many things and in particular the global variables.
Its size can be very large.
The contents of this area are determined at compile time.
For example here the size of large_array is 10 million ints, and it won’t change.
It goes into static memory.
Another area is the stack, which stores local variables and function parameters. Its size is very small, by default a few megabytes on Linux. Most allocation sizes on the stack are fixed at compile time, although this is where variable‑sized arrays live too.
Finally, we have a third area called the heap. It has a large size and all allocations there are realised dynamically at runtime, i.e. the size of what we allocate there does not need to be known at compile time:
Allocating on the Heap with malloc
There is a function used to perform dynamic memory allocation on the heap.
It is called malloc.
Here is an example of its usage:
#include <stdio.h>
#include <stdlib.h> // needed for malloc
int large_array[10000000];
int process_array(int *array, int size) { /* do something with array */ }
int main(int argc, char **argv) {
int small_array[128];
int *heap_array;
/* ... */
int size = atoi(argv[1]);
/* Allocate size * sizeof(int) bytes on the heap: */
heap_array = malloc(size * sizeof(int));
if(heap_array == NULL)
return -1;
process_array(heap_array, size);
free(heap_array); /* free the area previously allocated */
return 0;
}
We declare an int pointer that will point to the allocated space.
Then we call malloc.
malloc takes one parameter, the size in bytes of the space we want to allocate.
Here it is the size of the array we wish to allocate.
It is equal to the number of elements we wish the array to contain, size, multiplied by the size of one element, that is sizeof(int).
malloc allocates a contiguous memory space in memory on the heap and returns a pointer to it.
A very important thing with malloc is to check its return value.
It can be NULL (an alias for 0) if the system runs out of memory.
Without checking, execution will continue with the pointer set to NULL, which will lead to bugs that can be hard to fix.
One last thing to know about dynamic memory allocation is that the programmer is responsible for releasing the allocated memory.
This is done with the free function, taking as parameter a pointer that points to a space previously allocated with malloc.
It is important to free up memory as soon as the program is finished with it.
Otherwise, the program holds memory for nothing; this is called a memory leak.
The type of the pointer returned by malloc is void *.
It’s a generic type so malloc can be used to allocate data that will be pointed to by pointers of all types.
For this example, small_array is a local array and it is allocated on the stack, e.g. it cannot be too large.
large_array is much larger, which is fine because it is a global variable, allocated in static memory.
Both small_array and large_array have their sizes fixed and known at compile time.
Finally, heap_array can be of any size (including large ones) and its size is not known at compile time; hence it must be allocated on the heap.
In memory, things look like that:

Heap memory can only be accessed with pointers. Consider this example:
double *ptr1;
int main(int argc, char **argv) {
int *ptr2;
ptr1 = malloc(10 * sizeof(double));
ptr2 = malloc(30 * sizeof(int));
if(ptr1 == NULL || ptr2 == NULL) { /* ... */ }
/* ... */
free(ptr1); free(ptr2);
return 0;
}
We have a global variable pointer ptr1, and a local variable pointer ptr2.
ptr1 itself resides in static memory, and ptr2 on the stack.
We make two calls to malloc to reserve two areas of memory on the heap.
Of course, we check that the allocations succeed.
Let us assume that the first call to malloc returns a chunk of allocated heap memory starting at address 0x40, and the second call returns a chunk at address 0x230.
Then we have ptr1 pointing to the heap at 0x40, and ptr2 also pointing to the heap at 0x230.
In memory, things look as follows:

Multidimensional Arrays and malloc
Below is an example of a multidimensional array of size 3 (rows) by 2 (columns) elements allocated with malloc:
int a = 3; int b = 2;
int **array;
array = malloc(a * sizeof(int *));
if(array == NULL) return -1;
for(int i=0; i<a; i++) {
array[i] = malloc(b * sizeof(int));
if(array[i] == NULL) return -1;
}
array[2][0] = 12;
/* ... */
for(int i=0; i<a; i++)
free(array[i]);
free(array);
The key idea is to store each row in its own contiguous area of memory allocated with malloc.
And to have another area storing columns, i.e. a set of pointers, each pointing to the area representing a row.
We declare array, that will be the base pointer of our bi‑dimensional array.
array will hold the pointers to the rows: it is an int ** variable, i.e. a pointer of pointer of int.
With malloc we allocate a first area of memory and have array point to it.
Its size equals the first dimension of the array we wish to create, i.e. the number of rows, 3, multiplied by the size of one element, a pointer of int: sizeof(int *).
array now points to an area with enough space to store 3 pointers of int.
Next we allocate in a loop the area for each row with malloc: 3 areas.
Each has a size equal to the second dimension of the array, i.e. the number of columns, 2, multiplied by the size of the final elements held in the array: sizeof int.
After each call to malloc we check its success and abort (return -1) if it fails.
After the rows and columns have been successfully allocated, we can use the original pointer array and the square brackets to index the array in the exact same way we would do with a static array.
Before exiting the program, we deallocate the memory with free in reverse order: first the row pointers in a loop, then what is pointed by array itself.
In memory, the array is laid out as follows:

We have our base pointer array, pointing to an area which size is equal to the number of rows of the array.
Each element of that area points to another area representing a row, with a size equal to the number of columns of the array.
Memory Leaks
When the programmer forgets to free memory it is called a memory leak. Such wasted memory is inefficient and can lead to crashes when the system runs out of memory, for example with long-running programs such as servers. Valgrind is a very useful tool to detect leaks, among other features. Take this example program containing a leak:
/* leak.c */
void print_ten_integers() {
int *array = malloc(10 * sizeof(int));
if(!array) {
printf("cannot allocate memory ...\n");
return;
}
for(int i=0; i<10; i++) {
array[i] = rand()%100;
printf("%d ", array[i]);
}
printf("\n");
/* array is never freed, leaking 10*sizeof(int) of memory each iteration */
}
int main(int argc, char **argv) {
int iterations = atoi(argv[1]);
for(int i=0; i<iterations; i++)
print_ten_integers();
return 0;
}
For Valgrind to work correctly, the program needs to be compiled with additional debug metadata so use the -g flag when calling gcc:
$ gcc -g leak.c -o leak
Valgrind reports the amount of bytes leaked, as well as the line in the sources of the corresponding calls to malloc:
$ valgrind --leak-check=full ./leak 10
...
==11613==
==11613== HEAP SUMMARY:
==11613== in use at exit: 400 bytes in 10 blocks
==11613== total heap usage: 11 allocs, 1 frees, 1,424 bytes allocated
==11613==
==11613== 400 bytes in 10 blocks are definitely lost in loss record 1 of 1
==11613== at 0x483577F: malloc (vg_replace_malloc.c:299)
==11613== by 0x109196: print_ten_integers (leak.c:5)
==11613== by 0x109294: main (leak.c:32)
==11613==
==11613== LEAK SUMMARY:
==11613== definitely lost: 400 bytes in 10 blocks
==11613== indirectly lost: 0 bytes in 0 blocks
==11613== possibly lost: 0 bytes in 0 blocks
==11613== still reachable: 0 bytes in 0 blocks
==11613== suppressed: 0 bytes in 0 blocks
Another useful tool to detect memory leaks, among other bad memory accesses, is Address Sanitizer (ASan).
To enable it you should simply add the -fsanitize=address compiler flag:
gcc -g -fsanitize=address leak.c -o leak
Then simply launch the application normally, once it exits ASan will report the leak:
./leak 10
...
=================================================================
==44945==ERROR: LeakSanitizer: detected memory leaks
Direct leak of 400 byte(s) in 10 object(s) allocated from:
#0 0x7f42c92b89cf in __interceptor_malloc ../../../../src/libsanitizer/asan/asan_malloc_linux.cpp:69
#1 0x561e71e3720a in print_ten_integers /tmp/leak.c:5
#2 0x561e71e3737f in main /tmp/leak.c:23
#3 0x7f42c9046249 in __libc_start_call_main ../sysdeps/nptl/libc_start_call_main.h:58
SUMMARY: AddressSanitizer: 400 byte(s) leaked in 10 allocation(s).
The C Standard Library Part 1
In this lecture we start discussing the C standard library, a set of functions you can use in your C programs to realise various low-level tasks. We cover functions regarding string and memory manipulation, console input, math and time. You can access the slides 🖼️ for this lecture. All the code samples given here can be found online, alongside instructions on how to bring up the proper environment to build and execute them here.
Manual Pages
We already came across a few functions of the standard library, such as printf or malloc.
For every function of the standard library, man <function name> in a Linux terminal will give you everything you need to know to use that function: function description, prototype, required headers, return value.
Manual pages are also available online, e.g. for printf: https://man7.org/linux/man-pages/man3/printf.3.html.
String Copy
The = operator should not be used to copy a string in C.
Remember that strings are arrays, and arrays are pointer.
So effectively with = one just creates a copy of the pointer that points to the same array’s content.
A proper string copy is realised with strcpy:
char *strcpy(char *dest, const char *src);
It takes the destination string as first parameter, and the source string as parameter.
The const keyword is simply there to indicate that strcpy will not modify the src parameter.
Care should be taken with respect to the sizes of the strings: if the destination buffer is smaller than the source string, it will overflow and a memory error will occur.
strncpy is somehow safer than strcpy as it accepts a 3rd argument, n, and copies only up to n bytes:
char *strncpy(char *dest, const char *src, size_t n);
n can for example be set to the size of the destination space to avoid overflows.
Note that both strcpy and strncpy do copy the termination character.
Below is an example of usage of both functions:
#include <string.h> // needed for strcpy/strncpy
/* ... */
char *string1 = "hello";
char *string2 = string1; // this is not a string copy!
char string3[10]; // allocated space of 10 bytes, it's called a buffer
/* not super safe, what if the length of string1 is larger than the 10 bytes of string3? */
strcpy(string3, string1);
/* better */
strncpy(string3, string1, 10);
In this example, string3 corresponds to a region of contiguous memory, writable, used to hold data: it is called a buffer.
After strcpy/strncpy is called, things look like this in memory:

String Concatenation
To concatenate two strings, use strcat or strncat:
char *strcat(char *dest, const char *src);
char *strncat(char *dest, const char *src, size_t n);
strcat takes two parameters, a destination and source strings.
In effect, it concatenates the source at the end of the destination.
Once again the programmer needs to consider the buffer sizes.
Same as strncpy, strncat can be used to concatenate up to a given number of characters.
Here is an example of usage of both functions:
#include <string.h>
/* ... */
char world[6] = "world";
char s1[32] = "hello ";
char s2[32] = "hello ";
strcat(s1, world); // possibly unsafe
strncat(s2, world, 32); // better
Format-based String Creation
sprintf is a useful function to create a string that is filled with values from variables of various type.
This is done with printf-like specifiers:
int sprintf(char *str, const char *format, ...);
It takes as parameter the destination string.
Then, a constant string filled with text as well as specifiers, same as with printf.
Then, a list of variables or expression corresponding to the specifiers, like with printf.
The destination string should be large enough to avoid memory errors.
Here is an example of usage:
#include <string.h>
int main(int argc, char **argv) {
int a = 12;
float b = 4.5;
char *s = "hello";
char string[64];
sprintf(string, "a is %d, b is %f, s is %s\n", a, b, s);
printf("%s", string); // a is 12, b is 4.500000, s is hello
return 0;
}
String Length and Comparison
To get the size of a string, in characters, use strlen:
size_t strlen(const char *s);
Note that this function does not count the termination character.
To compare two strings, use strcmp:
int strcmp(const char *s1, const char *s2);
It returns 0 if the string matches, a negative number if s1 is before s2 in the lexicographical order, and a positive one if s1 is after s2.
Here is an example of usage of both functions:
#include <string.h>
/* ... */
char *s1 = "hello"; char *s2 = "hello";
char *s3 = "not hello";
printf("strcmp(s1, s2) returns: %d\n", strcmp(s1, s2)); // 0
printf("strcmp(s1, s3) returns: %d\n", strcmp(s1, s3)); // -6
printf("length of s3: %d\n", strlen(s3)); // 9
For more information about string manipulation functions type man string in a terminal.
Further resources are also available online^[https://en.wikibooks.org/wiki/C_Programming/String_manipulation.]
Console Input
fgets receives a string from the console:
char *fgets(char *s, int size, FILE *stream);
It takes the destination buffer as first parameter, the size of that buffer, and the special keyword stdin that indicate the standard input.
The program will then read what is typed on the keyboard until the user presses enter.
To input numbers one should rather use scanf.=:
int scanf(const char *format, ...);
It takes a printf-like format string, with specifiers for the variable we wish to update the value based on the user input.
Then we have the addresses of the variables in question.
Below is an example of usage of both functions:
int main(int argc, char **argv) {
int int1, int2;
double double1;
float float1;
char s[128];
printf("Please input a string:\n");
fgets(s, 128, stdin);
printf("Please input an integer:\n");
scanf("%d", &int1);
printf("Please input a float:\n");
scanf("%lf", &double1); /* make sure to us %lf for double and %f for float */
printf("Please enter an integer and a float separated by a space\n");
scanf("%d %f", &int2, &float1);
printf("You have entered: %d, %d, %lf, %f, and %s\n", int1, int2, double1,
float1, s);
return 0;
}
Writing Bytes to Memory, Copying Memory
memset repeatedly writes the byte c, n times starting from address s:
void *memset(void *s, int c, size_t n);
It can be useful for example when you want to zero out a buffer.
memcpy copies a buffer into another one:
void *memcpy(void *dest, void *src, size_t n);
An example of usage of both functions is presented below:
#include <stdio.h>
#include <string.h> // needed for memcpy and memset
#include <stdlib.h>
int main(int argc, char **argv) {
int buffer_size = 10;
char *ptr1 = malloc(buffer_size);
char *ptr2 = malloc(buffer_size);
if(ptr1 && ptr2) {
memset(ptr1, 0x40, buffer_size); // 0x40 is ascii code for @
memcpy(ptr2, ptr1, buffer_size);
for(int i=0; i<buffer_size; i++) {
printf("ptr1[%d] = %c\n", i, ptr1[i]);
printf("ptr2[%d] = %c\n", i, ptr2[i]);
}
free(ptr1); free(ptr2);
}
return 0;
}
Math Functions
There are a few: square root, power, cosinus, amongst many others.
Most have a float and double version, for example ceil and ceilf.
Here is an example with a few calls to some math functions:
// When compiling a program using math.h, // use -lm on the command line:
// gcc program.c -o program -lm
#include <stdio.h>
#include <math.h> // needed for math functions
int main(int argc, char **argv) {
printf("ceil 2.5: %f\n", ceil(2.5));
printf("floor 2.5: %f\n", floor(2.5));
printf("2^5: %f\n", pow(2, 5));
printf("sqrt(4): %f\n", sqrt(4));
return 0;
}
The full list of available functions can be found online^[https://cplusplus.com/reference/cmath/].
Note that when building a program using math functions, you need to use a specific -lmflag when you call the compiler:
gcc src.c -o program -lm
Sleeping
To have the program wait for a given time one can use sleep for sleeping in seconds, and usleep for sleeping in microseconds:
unsigned int sleep(unsigned int seconds);
int usleep(useconds_t usec);
It is useful in certain applications that generally have an infinite main loop, but don’t want to hang 100% of the CPU, such as servers. Here is a code example:
#include <stdio.h>
#include <unistd.h> // needed for sleep and usleep
int main(int argc, char **argv) {
printf("hello!\n");
printf("Sleeping for 2 seconds ...\n");
sleep(2);
printf("Now sleeping for .5 seconds ...\n");
usleep(500000);
return 0;
}
Current Time
To get the current time thetime function can be used:
time_t time(time_t *tloc); // time_t is generally a long long unsigned int
A simple way to call it is with NULL as a parameter.
It returns the number of seconds elapsed since the 1st of January 1970, which is a standard timestamp for UNIX computers.
Measuring Execution Time
To get a more precise measurement of the current time we can use gettimeofday:
int gettimeofday(struct timeval *tv, struct timezone *tz);
// struct timeval {
// time_t tv_sec; /* seconds (type: generally long unsigned) */
// suseconds_t tv_usec; /* microseconds (type: generally long unsigned) */
// };
It takes a pointer to a struct timeval as parameter.
This struct has two fields, one for seconds, tv_sec and the other for microseconds, tv_usec.
The second parameter should always be NULL.
Like time it also returns the time elapsed since the 1st of January 1970.
gettimeofday is very useful to measure execution time, as shown in this example:
#include <stdio.h>
#include <sys/time.h> // needed for gettimeofday
int main(int argc, char **argv) {
struct timeval tv, start, stop, elapsed;
gettimeofday(&tv, NULL);
printf("Seconds since the epoch: %lu.%06lu\n", tv.tv_sec, tv.tv_usec);
gettimeofday(&start, NULL);
for(int i=0; i<1000000000; i++);
gettimeofday(&stop, NULL);
timersub(&stop, &start, &elapsed);
printf("Busy loop took %lu.%06lu seconds\n", elapsed.tv_sec,
elapsed.tv_usec);
return 0;
}
3 struct timeval variables are declared.
A first call to gettimeofday is done before the code for which we want to measure the execution time.
Here it is just a busy loop.
A second call to gettimeofday is done right after that.
Then timersub is called to compute the difference between the two timestamps.
Notice how a struct timeval is printed, with "%lu.%06lu": this forces the inclusion of up to six leading zeroes if the microsecond value is inferior to one million.
The C Standard Library Part 2
Here we continue to discuss the standard library. We cover reading and writing to files, as well as error management. You can access the slides 🖼️ for this lecture. All the code samples given here can be found online, alongside instructions on how to bring up the proper environment to build and execute them here.
File I/O: Basic Access Functions
open
Before reading or writing from a file, we first need to obtain a handle to that file with open:
int open(const char *pathname, int flags, mode_t mode);
This handle is named a file descriptor. Open takes several parameters:
pathnameis the path of the file, for example/home/pierre/test.flagsspecifies how the file will be used. For that parameter several flags can be specified by piping particular keywords. The access mode indicates if we will only read the file (O_RDONLY), only write the file (O_WRONLY) or both (O_RDWR). We can indicate to create the file if it does not exist withO_CREAT. We can truncate the file size to 0 if it exists withO_TRUNC. There are more possible values forflags, described inopen’s manual page^[https://linux.die.net/man/2/open].- The final argument
modeindicates file permissions if it is created, see in the man page the accepted values.
Open returns the file descriptor in the form of an int.
read
Once we have the file descriptor we can access the file. Use the read function to read from the file:
ssize_t read(int fd, void *buf, size_t count);
read takes 3 parameters:
- The first parameter is the file descriptor to read from.
- The second is the address of a buffer that will receive the data that is read.
- The third is the amount of bytes to read.
The read function returns the amount of bytes that were actually read.
That value can be used to check for errors.
Note that it is not an error if the number of bytes read is smaller than what is requested, for example the end of the file could have been reached.
An actual error is indicated by a return value equal to -1.
write
The write function is used to write in the file, it works similarly to read:
ssize_t write(int fd, const void *buf, size_t count);
Its parameters are:
- The file descriptor to write to.
- The address of a buffer containing the data we wish to write.
- The amount of bytes to write.
write returns the amount of bytes that were actually written.
Same as with read, it is not an error if the number of bytes written is smaller than what is requested, for example the disk could be full.
However, it’s an error when it returns -1.
close
Once the operations on a file are finished, the programmer must free the file descriptor using close:
int close(int fd);
Example: Writing to a File
Consider the following example:
#include <stdio.h>
#include <sys/types.h> // needed for open
#include <sys/stat.h> // needed for open
#include <fcntl.h> // needed for open
#include <unistd.h> // needed for read and write
#include <string.h>
int main(int argc, char **argv) {
int fd1;
char *buffer = "hello, world!";
fd1 = open("./test", O_WRONLY | O_TRUNC | O_CREAT, S_IRUSR | S_IWUSR);
if(fd1 == -1) {
printf("error with open\n");
return -1;
}
/* write 'hello, world!' in the file */
if(write(fd1, buffer, strlen(buffer)) != strlen(buffer)) {
printf("issue writing\n");
close(fd1); return -1;
}
/* write it again */
if(write(fd1, buffer, strlen(buffer)) != strlen(buffer)) {
printf("issue writing\n");
close(fd1); return -1;
}
close(fd1);
return 0;
}
Here we first open a file.
With the flags O_WRONLY | O_TRUNC | O_CREAT we specify that we will perform on write operations, that if the file exist we want its size to be reduced to 0 upon open (this effectively destroys all the content of the file if there was any), and also that we want to create the file if it does not exist.
If the file needs to be created, its permission will be read and write permissions for the current user (S_IRUSR | S_IWUSR).
For this example, we can illustrate the content of the (empty) file on disk and of the relevant part of the program’s memory after the call to open as follows:
Next, we perform a write operation in the file.
We have the file descriptor, and we write from buffer that contains "hello world".
We set the amount of bytes to write to be the size of that buffer.
For simplicity, we exit if we cannot fully write the buffer.
And then we perform again the same write operation.
Next we close the file and exit.
This is the content of the file test after execution of that program:
hello, world!hello, world!
When the file is opened, associated with the file descriptor there is an internal offset value that is set at the beginning of the file on disk, that is the address 0 in the file:

When we perform the first write the buffer is written in the file starting from the offset, then the offset is placed right after what was written:

Then we write a second time the buffer in the file starting at the offset, and we shift the offset at the end of what was written:

Example: Reading from a File
Things work very similarly for read operations. Consider the following example:
// Here ee Assume the local file "test" was previously created
// with previous (write) example program
char buffer2[10];
int fd2 = open("./test", O_RDONLY, 0x0);
int bytes_read;
if(fd2 == -1) { printf("error open\n"); return -1; }
/* read 9 bytes */
if(read(fd2, buffer2, 9) != 9) {
printf("error reading\n"); close(fd2); return -1;
}
/* fix the string and print it */
buffer2[9] = '\0';
printf("read: '%s'\n", buffer2);
/* read 9 bytes again */
bytes_read = read(fd2, buffer2, 9);
if(bytes_read != 9) {
printf("error reading\n"); close(fd2); return -1;
}
/* fix the string and print it */
buffer2[9] = '\0';
printf("read: '%s'\n", buffer2);
close(fd2);
We open the file we previously created in read-only mode.
We read 9 bytes from it inside buffer2 and we display the content of buffer2.
We do this operation twice.
Note how we manually write the string termination character in the last byte of buffer2, right after what was read.
This program outputs the following:
read: 'hello, wo'
read: 'rldhello,'
When the file descriptor is created, the file offset is initialised to 0:

The first read operation of 9 bytes reads the first 9 bytes of the file into the first 9 bytes of buffer2 and shifts the offset right after that:

A second read operation reads the next 9 bytes from the file and shifts the buffer again:

Random Number Generation
The rand function returns a random integer ranging from 0 to a large constant named RAND_MAX:
int rand(void);
If we want to constrain the number to fall within a particular interval we can use the modulo operator. In this example we’ll get only numbers ranging between 0 and 99:
for(int i=0; i<10; i++)
printf("%d ", rand()%100);
Running this program one may notice that the sequence is always the same among several runs. This is not a very random behaviour. It is due to the way the numbers are generated, it is done in sequence based on a value called the seed. A given seed will always yield the same sequence. So to get variable sequences among multiple execution, we can initialise the seed based on the current time:
srand(time(NULL)); // init random seed
for(int i=0; i<10; i++)
printf("%d ", rand()%100);
Note that in some cases it is good to have a fixed seed to ensure reproducible results.
Error Management
When a function from the C standard library fails, a variable maintained by the C library is set with an error code.
This variable is errno.
Consider this code:
#include <errno.h> // needed for errno and perror
int main(int argc, char **argv) {
int fd = open("a/file/that/does/not/exist", O_RDONLY, 0x0);
/* Open always returns -1 on failure, but it can be due to many different reasons */
if(fd == -1) {
printf("open failed! errno is: %d\n", errno);
/* errno is an integer code corresponding to a given reason. To format
* it in a textual way use perror: */
perror("open");
}
return 0;
}
Here we try to open a file that does not exist and open fails, it returns -1.
We can print the value of errno, it’s an integer, so it’s not very helpful by itself.
We can get a better description of the error with the function perror.
It internally looks at errno and prints a textual description of the error on the terminal.
The C Standard Library Part 3
In this third and last lecture on the C standard library, we discuss the strtol function, used to convert strings into numbers, as well as stream-based file operations, a series of functions to perform file I/O.
You can access the slides 🖼️ for this lecture.
All the code samples given here can be found online, alongside instructions on how to bring up the proper environment to build and execute them here.
Limitations of atoi
Until now we have been converting strings to integers using the function atoi.
The advantage of atoi is that it is easy to use, you simply pass the string as parameter, and it returns the converted integer.
However, when the string is malformed or corresponds to a number that is too large or too small to be stored as an integer, atoi will not warn you that something has gone wrong.
Things failing silently and the program continuing to execute in an inconsistent state can be very hard to debug.
Converting Strings to Integers with strtol
The solution to that problem is to use strtol:
long strtol(const char *nptr, char **endptr, int base);
Its usage is slightly more complicated than atoi, but it is also much more robust.
strtol will convert the string pointed by nptr into a long that is returned.
One can specify a base such as 10, 16 for hexadecimal numbers, etc.
endptr is used to check the validity of the string: after the call, what is pointed by endptr will point either to the first invalid character of the string, and to '\0' if the string is fully valid.
In case of under or overflow, errno is set to ERANGE and strtol returns either LONG_MIN if it is an underflow, or LONG_MAX if it is an overflow.
Consider this example:
/* ... */
#include <errno.h>
#include <limits.h>
int main(int argc, char **argv) {
if(argc != 2) { /* ... */ }
char *endptr;
long n = strtol(argv[1], &endptr, 10);
if(*endptr != '\0') {
printf("invalid string!\n");
return -1;
}
if(errno == ERANGE) {
if(n == LONG_MIN) printf("underflow!\n");
if(n == LONG_MAX) printf("overflow!\n");
return -1;
}
printf("n is: %ld\n", n);
return 0;
}
We use strtol to detect malformed strings and under/overflows.
When we call the function in question, we pass as parameter the string, a pointer of pointer of character for endptr, and 10 to indicate a decimal base.
Note that because strtol wants to return a pointer through the endptr parameter, we need to pass a pointer of pointer, a char **.
It is a pointer to a char * that we declared above.
We check if the string was valid by observing the value of what is pointed by endptr.
If it is the NULL character the string is valid, otherwise we abort.
We also check that there was no overflow or underflow by looking at errnoand at the return value of strtol.
Stream-based File I/O: Main Functions
fopen and fclose
We create a stream object, also called FILE *, with the fopen function:
FILE *fopen(const char *pathname, const char *mode);
It takes the file path as parameter, and returns the stream object or NULL if something went wrong.
It also takes another parameter, mode, that precises how the file will be accessed, as well as what to do if the file does not exist or if it already exists when fopen is called:
"r": read-only."r+": read-write."w": write-only, truncate file if it exists, create it if it does not."w+": read-write, truncate file if it exists, create it if it does not.- There are more options possible for
mode, listed in the relevant manual page.
Once all operations on a stream are done, it needs to be released with fclose():
int fclose(FILE *stream);
fread and fwrite
To read and write in streams representing files, the functions fread and fwrite are used:
size_t fread(void *ptr, size_t size, size_t nmemb, FILE *stream);
size_t fwrite(const void *ptr, size_t size, size_t nmemb, FILE *stream);
fread reads nmemb contiguous items, each item being of file size, from the file represented by stream, into memory at address ptr.
fwrite writes nmemb items, each of file size, into the file represented by stream, from memory at address ptr.
These functions return the number of items read or written, which is only equal to the total number of bytes written when size is 1.
Note that similarly to what happens with file descriptors, streams have an internal offset that gets incremented each time we access the file.
For example, this call to fread aims to read 3 items, each of size 4 bytes:
items_read = fread(buffer, 4, 3, file_ptr);
In memory and on disk, assuming a file with the same content as our previous example regarding read/write, after fread returns, things look like that:

Stream-based File I/O: Example
Consider that example program:
#include <stdio.h>
char *alphabet = "abcdefghijklmnopqrstuvwxyz";
int main(int argc, char **argv) {
FILE *f1, *f2;
char buffer[27];
f1 = fopen("test-file.txt", "w");
if(f1 == NULL) {
perror("fopen");
return -1;
}
if(fwrite(alphabet, 2, 13, f1) != 13) {
perror("fwrite");
fclose(f1);
return -1;
}
fclose(f1);
f2 = fopen("test-file.txt", "r");
if(f2 == NULL) {
perror("fopen");
return -1;
}
if(fread(buffer, 1, 26, f2) != 26) {
perror("fread");
fclose(f2);
return -1;
}
buffer[26] = '\0';
printf("read: %s\n", buffer);
fclose(f2);
return 0;
}
We start by opening a first stream f1 in write-only mode.
This mode will create the file if it does not exist, and if it does, it will truncate its size to 0.
Next we want to write the entirety of the string alphabet in the file.
Using fwrite, we can do it for example as 13 chunks of size 2 bytes each.
Once done we close the stream f1 with fclose.
Next we open a new stream f2, in read-only mode this time.
Note that because this is a new stream independent of the previous one, its offset will be set to 0 in the file.
We aim to read what we previously wrote in the file.
With fread we can do it for example as 26 chunks of 1 byte each.
Similarly to read, the programmer needs to fix up the buffer storing the result with the termination character to make it a proper C string.
Memory Management and the Standard Library: Exercises
See here how to set up a development environment to do these exercises.
- You should complete the essential exercises if you want to claim you know how to program in C.
- If you want to go further and make sure you understand everything, you can also complete the additional exercises.
Essential Exercises
- Working with pointers
- Working with pointers (2)
- Dynamic memory allocation with
malloc - Dynamic memory allocation with
malloc(2) - Dynamic memory allocation with
malloc(3) - Standard input and string comparison
- Sleeping and measuring execution time
- File I/O
Working with Pointers
Consider the following program:
#include <stdio.h>
#include <stdlib.h>
int add(int a, int b) {
return a + b;
}
int main(int argc, char **argv) {
if(argc == 3) {
int a = atoi(argv[1]);
int b = atoi(argv[2]);
printf("%d + %d = %d\n", a, b, add(a, b));
}
return 0;
}
Modify the function add and its invocation so that it takes two int pointer parameters. Examples of output:
./pointer 10 20
10 + 20 = 30
./pointer 154 -12
154 + -12 = 142
To check the correctness of your program, use a use a Linux distribution with check50 installed and write your solution in a file named pointer.c.
In a terminal, with that file in the local directory, check with this command:
check50 -l --ansi-log olivierpierre/comp26020-problems/2025-2026/week3-c-pointers-stdlib/01-pointer
Working with Pointers (2)
With a linked list, the programmer uses pointer chains to link together data structures. In the example program below, a simple linked list with 3 elements is constructed then the value of the last element is printed:
#include <stdio.h>
/* Typedef struct forward declaration for the pointer member */
typedef struct s_list_member list_member;
typedef struct s_list_member {
int value;
list_member *next;
} list_member;
int main(int argc, char **argv) {
list_member lm1, lm2, lm3;
lm1.value = 1; lm1.next = &lm2;
lm2.value = 2; lm2.next = &lm3;
lm3.value = 3; lm3.next = 0x0;
printf("third member value is: %d\n", lm3.value);
return 0;
}
Modify the second parameter of the call to printf in order to print the value of the third element by using the first member lm1 and following the pointer chain leading to the value of lm3. The expected output is:
./pointer2
third member value is: 3
To check the correctness of your program, use a use a Linux distribution with check50 installed and write your solution in a file named pointer2.c.
In a terminal, with that file in the local directory, check with this command:
check50 -l --ansi-log olivierpierre/comp26020-problems/2025-2026/week3-c-pointers-stdlib/02-pointer2
Dynamic Memory Allocation with malloc
Write a program taking a list of integers as command line parameters, storing them in an array allocated with malloc, and sorting that array in increasing order.
Output examples:
./malloc 5 4 3 2 1
1 2 3 4 5
./malloc 546 874 18 13 87 54 4651 54 877 8 46351 87 654 657 654
8 13 18 54 54 87 87 546 654 654 657 874 877 4651 46351
To check the correctness of your program, use a use a Linux distribution with check50 installed and write your solution in a file named malloc.c.
In a terminal, with that file in the local directory, check with this command:
check50 -l --ansi-log olivierpierre/comp26020-problems/2025-2026/week3-c-pointers-stdlib/03-malloc
Dynamic Memory Allocation with malloc (2)
Write a C program that takes two integers as command line parameter, x and y, and prints on the standard output y lines of x integers corresponding to the first (x * y) natural integers.
The numbers should be stored in a 2-dimensional array allocated with malloc before being printed.
# 3 rows, 4 columns
./malloc2 3 4
0 1 2 3
4 5 6 7
8 9 10 11
./malloc2 2 5
0 1 2 3 4
5 6 7 8 9
./malloc2 10 11
0 1 2 3 4 5 6 7 8 9 10
11 12 13 14 15 16 17 18 19 20 21
22 23 24 25 26 27 28 29 30 31 32
33 34 35 36 37 38 39 40 41 42 43
44 45 46 47 48 49 50 51 52 53 54
55 56 57 58 59 60 61 62 63 64 65
66 67 68 69 70 71 72 73 74 75 76
77 78 79 80 81 82 83 84 85 86 87
88 89 90 91 92 93 94 95 96 97 98
99 100 101 102 103 104 105 106 107 108 109
To check the correctness of your program, use a use a Linux distribution with check50 installed and write your solution in a file named malloc2.c.
In a terminal, with that file in the local directory, check with this command:
check50 -l --ansi-log olivierpierre/comp26020-problems/2025-2026/week3-c-pointers-stdlib/04-malloc2
Dynamic Memory Allocation with malloc (3)
Fix the memory leak contained in the following program:
#include <stdio.h>
#include <stdlib.h>
int main(int argc, char **argv) {
int *a = malloc(10 * sizeof(int));
if(!a) return -1;
for(int i=0; i<10; i++)
a[i] = i*2;
int *b = a;
for(int i=0; i<10; i++)
printf("%d ", b[i]);
printf("\n");
return 0;
}
The expected output is:
./malloc3
0 2 4 6 8 10 12 14 16 18
To check the correctness of your program, use a use a Linux distribution with check50 installed and write your solution in a file named malloc3.c.
In a terminal, with that file in the local directory, check with this command:
check50 -l --ansi-log olivierpierre/comp26020-problems/2025-2026/week3-c-pointers-stdlib/05-malloc3
Standard Input and String Comparison
Write a C program reading two strings from the standard input using fgets, and indicating if the strings are similar or not.
Output examples:
./string
input string1:
test
input string2:
test
strings are similar
./string
input string1:
hello world!
input string2:
goodbye
strings are different
To check the correctness of your program, use a use a Linux distribution with check50 installed and write your solution in a file named string.c.
In a terminal, with that file in the local directory, check with this command:
check50 -l --ansi-log olivierpierre/comp26020-problems/2025-2026/week3-c-pointers-stdlib/06-string
Sleeping and Measuring Execution Time
Write a C program taking an integer n as command line parameter and sleeping for n seconds.
The execution time of the sleep function is measured and displayed. Examples output:
./time 3
sleep duration: 3.000082 seconds
./time 5
sleep duration: 5.000108 seconds
To check the correctness of your program, use a
use a Linux distribution with check50 installed
and write your solution in a file named time.c. In a
terminal, with that file in the local directory, check with this command:
check50 -l --ansi-log olivierpierre/comp26020-problems/2025-2026/week3-c-pointers-stdlib/07-time
File I/O
Write a C program taking as command line parameter A) a file name f and B) a word w.
The program then creates the file f-processed which is a copy of f where all occurrences of the word w have been deleted.
Here is an example of execution:
cat sample-file-1
hello world
this is a test file containing the word hello several times
some lines do not contain that word
while others do: hello
./file sample-file-1 hello
cat sample-file-1-processed
world
this is a test file containing the word several times
some lines do not contain that word
while others do:
You download sample-file-1 here.
To check the correctness of your program, use a use a Linux distribution with check50 installed and write your solution in a file named file.c.
In a terminal, with that file in the local directory, check with this command:
check50 -l --ansi-log olivierpierre/comp26020-problems/2025-2026/week3-c-pointers-stdlib/08-file
Make sure that sample-file-1 is in the current directory alongside file.c
Additional Exercises
- Working with pointers (3)
- Working with pointers (4)
- Dynamic memory allocation with
malloc(4) - Dynamic memory allocation with
malloc(5) - String manipulation
- Copying data in memory with
memcpy - Math operations
- String to integer conversion with
strtol - Stream-based file I/O
Working with Pointers (3)
Write a program that takes an integer as parameter and places it in a variable of type int.
The program then proceeds to print the value as well as the address of the variable as follows:
./pointer3 5
Variable contains 5 and is located @0x7ffcc6d1d7fc
./pointer3 93
Variable contains 93 and is located @0x7fffec3b3dfc
Printing pointers. Pointer can be printed in hexadecimal and prefixed with
0xusing the%pformat specifier forprintf.
To check the correctness of your program, use a use a Linux distribution with check50 installed and write your solution in a file named pointer3.c.
In a terminal, with that file in the local directory, check with this command:
check50 -l --ansi-log olivierpierre/comp26020-problems/2025-2026/week3-c-pointers-stdlib/09-pointer3
Working with Pointers (4)
Consider the following program printing a string to the standard output character by character:
#include <stdio.h>
int main(int argc, char **argv) {
char *string = "hello, world!\n";
int i = 0;
while(string[i] != '\0')
printf("%c", string[i++]);
return 0;
}
Alter the loop to use a char * pointer as the iterator and as the way to access characters within the string for printing.
The source code should contain no square bracket.
The expected output is:
./pointer4
hello, world!
To check the correctness of your program, use a
use a Linux distribution with check50 installed
and write your solution in a file named pointer4.c. In a
terminal, with that file in the local directory, check with this command:
check50 -l --ansi-log olivierpierre/comp26020-problems/2025-2026/week3-c-pointers-stdlib/10-pointer4
Dynamic Memory Allocation with malloc (4)
Write a C program using malloc to allocate an array able to contain 10 int, fill this array with the 10 first natural number (starting with 0).
The expected output is:
./malloc4
0
1
2
3
4
5
6
7
8
9
To check the correctness of your program, use a use a Linux distribution with check50 installed and write your solution in a file named malloc4.c.
In a terminal, with that file in the local directory, check with this command:
check50 -l --ansi-log olivierpierre/comp26020-problems/2025-2026/week3-c-pointers-stdlib/11-malloc4
Dynamic Memory Allocation with malloc (5)
Consider the following program:
#include <stdio.h>
#include <stdlib.h>
void *my_realloc(void *ptr, size_t old_size, size_t new_size) {
/* complete here */
}
int main(int argc, char **argv) {
/* first malloc space for 5 int */
int *array = malloc(5 * sizeof(int));
if(!array) return -1;
for(int i=0; i<5; i++) {
array[i] = i*10;
printf("before realloc, array[%d] = %d\n", i, array[i]);
}
/* expand the size to 10 int */
array = my_realloc(array, 5*sizeof(int), 10*sizeof(int));
if(!array) return -1;
for(int i=5; i<10; i++)
array[i] = i*10;
for(int i=0; i<10; i++)
printf("after realloc, array[%d] = %d\n", i, array[i]);
free(array);
return 0;
}
Write the function my_realloc that changes the size of a buffer previously allocated with malloc while preserving all or part of the buffer content according to the requested size.
The function parameters are:
ptr: buffer addressold_size: current size of the buffernew_size: new size requested
The expected output is:
before realloc, array[0] = 0
before realloc, array[1] = 10
before realloc, array[2] = 20
before realloc, array[3] = 30
before realloc, array[4] = 40
after realloc, array[0] = 0
after realloc, array[1] = 10
after realloc, array[2] = 20
after realloc, array[3] = 30
after realloc, array[4] = 40
after realloc, array[5] = 50
after realloc, array[6] = 60
after realloc, array[7] = 70
after realloc, array[8] = 80
after realloc, array[9] = 90
Memory copy in C. Memory copy is achieved with the
memcpyfunction that takes 3 arguments: the destination address, the source address, and the number of bytes to copy. To use it you’ll need to#include <string.h>. See here for more information.
Realloc. Although this functionality already exists in the form of the standard function
realloc(see here – for the sake of the exercise it is asked to implement it manually here.
To check the correctness of your program, use a use a Linux distribution with check50 installed and write your solution in a file named malloc5.c.
In a terminal, with that file in the local directory, check with this command:
check50 -l --ansi-log olivierpierre/comp26020-problems/2025-2026/week3-c-pointers-stdlib/12-malloc5
String Manipulation
Write a C program reading a string from the standard input and capitalise the first letter of each word.
./string2
input a string:
we swears, to serve the master of the precious
We Swears, To Serve The Master Of The Precious
./string2
input a string:
and following our will and wind we may just go where no one's been
And Following Our Will And Wind We May Just Go Where No One's Been
Capitalising letters. See the
toupperfunction: https://linux.die.net/man/3/toupper
To check the correctness of your program, use a use a Linux distribution with check50 installed and write your solution in a file named string2.c.
In a terminal, with that file in the local directory, check with this command:
check50 -l --ansi-log olivierpierre/comp26020-problems/2025-2026/week3-c-pointers-stdlib/13-string2
Copying Data in Memory with memcpy
Write a C program taking an integer n as command line parameter, allocating an array of integer of size n, and filling that array with random integers – each between 0 and 100.
Next, a second array of size n is created and the content of the first array is copied into the second one with a single call to memcpy.
Finally, both arrays are printed.
Example output:
./memcpy 10
array1: 32 32 54 12 52 56 8 30 44 94
array2: 32 32 54 12 52 56 8 30 44 94
./memcpy 15
array1: 32 32 54 12 52 56 8 30 44 94 44 39 65 19 51
array2: 32 32 54 12 52 56 8 30 44 94 44 39 65 19 51
Random Numbers. See the
randfunction: https://linux.die.net/man/3/rand. For example to get a random integer between 0 and 9 (included):int random_int = rand()%10.
To check the correctness of your program, use a use a Linux distribution with check50 installed and write your solution in a file named memcpy.c.
In a terminal, with that file in the local directory, check with this command:
check50 -l --ansi-log olivierpierre/comp26020-problems/2025-2026/week3-c-pointers-stdlib/14-memcpy
Math Operations
Write a C program reading a double with scanf and asking the user if he wants this number to be floored or ceiled.
Next, the program performs the requested operation and displays the result. Output examples:
./math
Input a number:
12.4
Input 0 for ceil, 1 for floor
0
13.000000
./math
Input a number:
45.87
Input 0 for ceil, 1 for floor
1
45.000000
To check the correctness of your program, use a use a Linux distribution with check50 installed and write your solution in a file named math.c.
In a terminal, with that file in the local directory, check with this command:
check50 -l --ansi-log olivierpierre/comp26020-problems/2025-2026/week3-c-pointers-stdlib/15-math
String to integer conversion with strtol
The program strtol.c converts a string entered by the user into an integer and prints it on the standard output.
The conversion is realised with atoi, and as such it is not robust in case of malformed strings as well as under/overflows.
Modify the implementation of the function convert_and_print in this program to use strtol for the conversion rather than atoi, and make the program more robust against improper inputs.
Output examples:
$ ./strtol
please enter an integer number (base 10): 1234
you have entered: 1234
$ ./strtol
please enter an integer number (base 10): foo
invalid string
$ ./strtol
please enter an integer number (base 10): 100000000000000000000
under/overflow
$ ./strtol
please enter an integer number (base 10): -100000000000000000000
under/overflow
To check the correctness of your program, use a use a Linux distribution with check50 installed and write your solution in a file named strtol.c.
In a terminal, with that file in the local directory, check with this command:
check50 -l --ansi-log olivierpierre/comp26020-problems/2025-2026/week3-c-pointers-stdlib/16-strtol
Stream-Based File I/O
This is a variation of a previous exercise targeting file I/O.
The goal is similar: write a C program taking as command line parameter A) a file name f and B) a word w.
The program then creates the file f-processed which is a copy of f where all occurrences of the word w have been deleted.
This time, you should use the stream-based file I/O functions (fopen, fread, and fwrite) to write the program.
Here is an example of execution:
cat sample-file-1
hello world
this is a test file containing the word hello several times
some lines do not contain that word
while others do: hello
./stream sample-file-1 hello
cat sample-file-1-processed
world
this is a test file containing the word several times
some lines do not contain that word
while others do:
You download sample-file-1 here.
To check the correctness of your program, use a use a Linux distribution with check50 installed and write your solution in a file named stream.c.
In a terminal, with that file in the local directory, check with this command:
check50 -l --ansi-log olivierpierre/comp26020-problems/2025-2026/week3-c-pointers-stdlib/17-stream
Make sure that sample-file-1 is in the current directory alongside stream.c
The Preprocessor
Here we discuss a particular tool that is executed by the compiler during the build process of a C or C++ program, and performing textual transformations in the code: the preprocessor. You can access the slides 🖼️ for this lecture. All the code samples given here can be found online, alongside instructions on how to bring up the proper environment to build and execute them here.
Introducing the Preprocessor
The preprocessor is executed automatically by the compiler right before the source code is compiled into machine code:

It performs textual transformations on the sources, so it takes as input the C source file and produces as output a modified version of these sources, i.e. something that is still C source code. After that step the compiler transforms the modified sources into an executable containing machine code.
The preprocessor is used for doing mainly 3 things:
- Include header files, we have actually been using the preprocessor to do this since the beginning of the course.
- Expand textual tokens named macros into larger and more complex bits of source code.
- Conditionally enable or disable some code.
Header Inclusion
Header files are these files ending with the .h extension.
They generally contain what is necessary to use foreign libraries/source files.
They contain functions prototypes, custom types/structs definitions, etc.
For example stdio.h contains the prototype of printf, amongst other things.
There are two ways to include a header:
// In the .c source file, include headers like that:
#include <stdio.h> // Use <> to include a file from the default include path
#include "my-custom-header.h" // Use "" for the local and user-supplied include directories
We have been using the first method extensively.
It will search for the specified header file in a standard location on the filesystem.
An example of such standard location is /usr/include.
Another method is to use the double quotes.
This will search for the specified header file in the local directory, in other words the directory from which we call gcc when we build the program.
So here in the example we assume that there is a file named my-custom-header.h in the local directory.
The preprocessor will include the entire content of the header in the source file before compilation.
Si in our example here, #include <stdio.h> gets replaced by the content of stdio.h content, and #include "my-custom-header.h" gets replaced by that file’s content:

Macro Expansions
Macros are textual substitutions based on tokens. They are very useful for defining things like compile-time constants. Consider this example:
#include <stdio.h>
// If we want to change the array size,
// we only need to update this:
*#define ARRAY_SIZE 10
int main(int argc, char **argv) {
* int array[ARRAY_SIZE];
* for(int i=0; i<ARRAY_SIZE; i++) {
array[i] = i;
printf("array[%d] = %d\n", i, array[i]);
}
return 0;
}
We have a macro named ARRAY_SIZE.
We generally put constants in capital letters in C/C++.
ARRAY_SIZE will be replaced by the preprocessor with 10.
The macro is used both in the array definition to set its size, and in the loop header iterating over the array, to set the number of iteration.
The nice thing is that when we want to update the size of the array, one just needs to update the macro.
If, on the contrary, 10 was hardcoded in the source code, there is a possibility of e.g. updating just the array size in the definition and then forgetting to update the loop header, which can lead to bugs.
In general, it is important to try to have a less hardcoded values as possible. When writing a constant value more than once, the programmer should consider if using a macro is possible.
Macro functions can also be defined^[https://www.ibm.com/docs/en/i/latest?topic=directive-function-like-macros], although this can be error prone^[https://gcc.gnu.org/onlinedocs/cpp/Macro-Pitfalls.html].
Macro Expansions and Operator Precedence
It is important to consider operator precedence when using macros. Consider the following code:
#define SIZE_1 10
#define SIZE_2 10
// We can use a macro in another macro's
// definition:
#define TOTAL SIZE_1 + SIZE_2
int main(int argc, char **argv) {
// faulty, expands to:
// 10 + 10 * 2
printf("total twice = %d\n",
TOTAL * 2);
return 0;
}
We have two macros, SIZE_1 that is 10 and SIZE_2 that is also 10.
We define a macro TOTAL that is the sum of both macros.
Note that we can use a macro in another macro definition.
We expect TOTAL to be 20.
In the main function we multiply TOTAL by 2, so we expect the result to be 40.
Because the preprocessor realised a textual transformation, TOTAL * 2 actually expands to 10 + 10 * 2.
With the multiplication operator taking precedence over the addition one, we do not obtain the expected behaviour.
To avoid issues with operator precedence, parentheses should be used in the definition of the macro:
#define TOTAL (SIZE_1 + SIZE_2)
Overall, it is advised that if a macro is made of more than a single item, parentheses should be used.
Conditional Compilation
The preprocessor allows the conditional inclusion of code. Consider the following example:
#define DEBUG_MODE // controls the activation/deactivation of debug mode
#define VERBOSITY_LEVEL 4 // controls the debug verbosity level
#ifdef DEBUG_MODE
int debug_function();
#endif
int main(int argc, char **argv) {
printf("hello, world\n");
#ifdef DEBUG_MODE
debug_function();
#endif
return 0;
}
#ifdef DEBUG_MODE
int debug_function() {
printf("This is printed only if the macro DEBUG_MODE is defined\n");
#if VERBOSITY_LEVEL > 3
printf("Additional debug because the verbosity level is high\n");
#endif /* VERBOSITY_LEVEL */
return 42;
}
#endif /* DEBUG_MODE */
We define two macros DEBUG_MODE and VERBOSITY_LEVEL.
DEBUG_MODE is defined without a particular value.
Its goal is to control the inclusion of debug code.
Through the use of #ifdef and #endif directives, all the code enclosed will be included in the compilation only if the DEBUG_MODE macro is defined.
In other words, if we comment the definition of that macro, all the enclosed code will not be included in the resulting executable.
We have another macro, VERBOSITY_LEVEL, defined with a value, 4.
With the #if directive we also include some code conditionally.
We can use the > or < operators, but also the equality with == and inequality with !=.
Note that we use a comment to detail which #if the #endif corresponds to, as preprocessor directives are generally not indented, to avoid any confusion.
Modular Compilation
Here we discuss modular compilation, the process of decomposing a program’s sources into several files and compiling a single executable from these sources. You can access the slides 🖼️ for this lecture. All the code samples given here can be found online, alongside instructions on how to bring up the proper environment to build and execute them here.
Modular Compilation: Motivation
With large programs, it is necessary to organise the code in several source files.
The Linux kernel v6.4 is for example composed of more than 56K C source files.
One cannot run gcc <56K source files>: not only it is impossible to write manually, but also would take an enormous amount of time to compile each time one do just a small update to one or a few source files.
Hence, here we will answer the following question: how to break up the program code into well isolated compilation units?
In the next lecture we will see how to automate efficiently the build process?.
A Closer Look at the Compilation Phase
Until now we saw that when we compile a source file into an executable, set aside the preprocessor phase, the compiler directly transforms the source code into the executable. Actually things are a bit more complicated under the hood. The compiler produces (sometimes transparently) an intermediate format: object files. And then we have a second tool named the linker, called under the hood by the compiler, that transforms object files into executables:

We can trigger these steps manually with the following commands:
$ gcc -c src.c -o src.o
$ gcc src.o -o executable
$ ls
executable src.c src.o
First we generate the object file with the -c switch when invoking the compiler.
The object file here is src.o.
Then we link it into an executable.
With only one source file, the linker does little work, but it plays an important role with modular compilation.
The object files are binary files: they contain compiled machine code, however that code is not ready for execution and needs linking.
Generally, object files have the .o extension.
Breaking Down the Program into Modules
Running Example
Now let us study how to break down the program sources into several source files. It is good to regroup code into source files (named modules in C) by functionality. Let’s assume that we have a hypothetical simple server application that works as follows:

When it is launched, the server initialises and enters its main loop. In this loop the server waits for a request from a client. When such a request is received, the server first parses it to extract its content, then it processes the request. Once done with that request, the server continues its main loop and wait for the next request to arrive.
The server is built from 3 source files:
network.ccontains the code related to networking operations.parser.ccontains the code to parse the requests received by the server.main.ccontains themainfunction, initialisation/exit code, and the main server loop.
We can compile each into the corresponding object file as we saw previously, and link all the object files together into an executable as follows:

On the command line:
$ gcc -c main.c -o main.o # build main.o
$ gcc -c parser.c -o parser.o # build parser.o
$ gcc -c network.c -o network.o # build network.o
$ gcc main.o network.o parser.o -o prog # link executable
Application Programming Interfaces
Each source file exposes a set of functions that can be called from other files: an application programming interface, API.
This interface should be as small as possible to hide internal module code and data.
For example if we have a function implemented in network.c and this function is only supposed to be called internally within the network module, there is no reason to give main.c the possibility to call that function.
We assume the following interactions between the 3 source files composing our program:
- When the program starts, in order to initialise networking,
main.ccallsinit_network()which is implemented innetwork.c. main.cthen runs the main sever loop:main.ccallsrcv_request()implemented innetwork.cto wait for the next request.- When a request is received,
main.ccallsparse_req()which is implemented byparser.cto process the request. - Rinse and repeat.
These interactions can be illustrated as follows:

Defining APIs with Header Files
To define the APIs exposed by each module that can be called externally, we use header files (with *.h extension) and the #include preprocessor directives to realise this compartmentalization.
Let’s assume that the external interface offered by the network module is constituted of 2 functions, init_network and receive_request, both supposed to be called from main.c.
The interface offered by the parser module is a single function, parse_request, also supposed to be called from main.c.
We create one header file per module exporting an interface: network.h and parser.h.
These header files will be included in several source files, so it is important that they contain only declarations: function prototypes, struct/typedef/enum declarations, variable declarations, etc.
They should contain no definitions.
On the filesystem our source code now looks like that:

This is network.h:
#ifndef NETWORK_H // include guard
#define NETWORK_H
typedef struct {
int id;
char content[128];
} request;
void init_network();
int rcv_request(request *r);
#endif /* NETWORK_H */
It contains everything that the world outside the network module needs to know in order to use the network interface.
We have the prototypes of the two functions of the interface, and also the declaration of the struct that is used as parameter in one of these functions.
Note the enclosing #ifdef NETWORK_H, it’s call an include guard.
It avoids the problem of double declaration when we include in a C file several files that themselves include this header.
Below is the content of network.c, also called its implementation:
/* std includes here */
#include "network.h"
// this function and variable are internal
// so they are not declared in network.h
// the keyword static force their use
// to be only within the network.c file
static void generate_request(request *r);
static int request_counter = 0;
void init_network() {
/* init code here ... */
}
int rcv_request(request *r) {
generate_request(r);
/* ... */
}
static void generate_request(request *r) {
/* ... */
}
We need to include the corresponding header to get access to the struct definition.
We have a function generate_request and a global variable request_counter that are internal to the module, and they are not supposed to be called/accessed from outside, we can enforce that with the static keyword.
And we have the implementation of the 2 functions that are exported by the network module.
parser.h and parser.c follow the same principles:
/* parser.h */
#ifndef PARSER_H
#define PARSER_H
/* needed for the definition of request: */
#include "network.h"
void parse_req(request *r);
#endif
/* parser .c */
#include "parser.h"
static void internal1(request *r);
static void internal2(request *r);
void parse_req(request *r) {
internal1(r);
internal2(r);
}
static void internal1(request *r) {
/* ... */
}
static void internal2(request *r) {
/* ... */
}
We have an external interface function declared in the header.
We also need the declaration of the struct so we include network.h in the parser header.
And in the module implementation we include the parser header.
We have a couple of internal functions, as well as the exported function.
Finally, main.c looks like that:
/* main.c */
#include "network.h"
#include "parser.h"
int main(int argc, char **argv) {
request req;
/* call functions from network module */
init_network();
rcv_request(&req);
/* call function from parser module */
parse_req(&req);
/* ... */
}
It’s including both headers to get access to the interface function prototypes. And within the main function the functions from the interface can be called.
Automated Compilation
Here we introduce a tool called make, that allows to automate the compilation of programs composed of multiple and potentially many source files.
You can access the slides 🖼️ for this lecture.
All the code samples given here can be found online, alongside instructions on how to bring up the proper environment to build and execute them here.
Incremental Build
When we have a program composed of several modules, there is no need to rebuild the entire program when just one or a few source files are changed.
Let’s take the example from the following lecture in which we build our program from 3 source files, network.c, parser.c and main.c.
A possible scenario is:
# Initial build:
$ gcc -c network.c -o network.o
$ gcc -c parser.c -o parser.o
$ gcc -c main.c -o main.o
$ gcc main.o network.o parser.o -o prog
# Assume we update parser.c, to rebuild we don't need to recompile everything:
$ gcc -c parser.c -o parser.o
$ gcc main.o network.o parser.o -o prog
# Now we update parser.h, remember it's included in both parser.c and main.c, so:
$ gcc -c parser.c -o parser.o
$ gcc -c main.c -o main.o
$ gcc main.o network.o parser.o -o prog
We have an initial build in which we compile each file and link the object files into the program.
Now assume we update parser.c, to rebuild the entire program we only need to recompile that source file and relink all object files.
We don’t need to recompile network.c and main.c.
Same thing if we modified parser.h, we only need to recompile the files including that header, parser.c and main.c, then relink.
We compile and link the program as follows:

And the dependencies between source/object/executable files can be represented as follows:

Keeping track of all these dependencies manually to avoid rebuilding the entire program each time we modify a subset of the source files is difficult though. Thankfully there exists a tool that can automatically manage all that process.
Makefiles: Automated Build and Dependency Management
This tool is called make.
It relies on configuration files named Makefiles.
They live alongside the sources, describing the build and its dependencies, following a particular format.
Let’s consider the build dependencies for our server application example:
- The final executable
progis produced by the link stage that requires the 3 object files,network.o,parser.o, andmain.o. network.ois the result of compilingnetwork.c, which also includenetwork.h.parser.ois the result of compilingparser.cthat also includesnetwork.handparser.h.- Finally,
main.ois the result of compilingmain.c, which includes both headers.
Now that we have reasoned about the dependencies we know what needs to be done when a given file is modified.
For example, if parser.h is modified, then main.o and parser.o need to be rebuilt, and prog needs to be relinked.
An Example of Makefile
We describe these dependencies in a file named Makefile:
# The first rule is executed when the
# command make is typed in the local folder:
all: prog
# executable deps and command to build it:
prog: main.o network.o parser.o
gcc main.o network.o parser.o -o prog
# network.o deps and command to build it:
network.o: network.c network.h
gcc -c network.c -o network.o
parser.o: parser.c parser.h network.h
gcc -c parser.c -o parser.o
main.o: main.c network.h parser.h
gcc -c main.c -o main.o
# Special rule to remove all build files
clean:
rm -rf *.o prog
It contains rules describing dependencies and actions with the following format:
- We have the target file on the left, followed by
:, followed by the file the target depends on. For examplemain.odepends onmain.c,network.hand parser.h; The final executableprogdepends onmain.o,network.oandparser.o; etc. - Below each target and list of dependencies, we have the command used to rebuild the target.
For example
main.ois created by compilingmain.c, andprogis created by linking the 3 object files. We also have a special ruleallthat will be executed when we typemakein the local directory. And another special rulecleanthat removes all build file.
After this file is properly set up, typing make in the local directory will trigger the rebuild of only what is needed to rebuild the target referenced by all.
Type Conversion and Casting
Here we discuss type conversion and casting in C. You can access the slides 🖼️ for this lecture. All the code samples given here can be found online, alongside instructions on how to bring up the proper environment to build and execute them here.
Implicit Type Conversions
In many situations the compiler performs implicit conversions between types. With arithmetic operations, it applies integer promotion, converting smaller types to larger ones. Consider this example:
char char_var = 12; // 1 byte, -128 -to 127
int int_var = 1000; // 4 bytes, -2*10^9 to 2*10^9
long long ll_var = 0x840A1231AC154; // 8 bytes, -9*10^18 to 9*10^18
// here, char_var is first promoted to int, then the result of the first
// addition is promoted to long long:
long long result = (char_var + int_var) + ll_var;
We declare signed integers of various sizes.
We have a char, note that we can store integers in chars, on x86-64 char size is one byte so it can store only 256 values.
We also have a regular int, on x86-64 its size is 4 bytes so it can store about 4 billions values.
And we also have a long long int, on x86-64 its size is 8 bytes, so it can store much more numbers.
Considering the operation computing the value of result, when the char is first added to the int, the char is automatically promoted to an int, and what is between parentheses evaluates to an int.
This value is then promoted to a long long because it’s added with a long long, and the resulting value is a long long.
We can store it in a long long variable (result) without fear of loosing precision or data truncation due to the intermediary operations and types.
These implicit conversions, with an operation applied to integers of different types, are called integer promotion.
Integer Promotion
The key idea behind integer promotion is that no information is lost when going from smaller to larger types. Integer types are given ranks. In decreasing order of rank we have:
long long int,unsigned long long int(highest rank).long int,unsigned long int.int,unsigned int.short int,unsigned short int.signed char,char,unsigned char(lowest rank).
The promotion rules for 2 operands of an operation are as follows, in order:
- If the operands have the same type there is no need for promotion.
- If both operands are signed or both operands are unsigned, the operand of lesser rank is promoted to the type of the operand of higher rank.
- If the rank of the unsigned operand is superior or equal to the rank of the other operand, the signed operand is promoted to the type of the unsigned operand.
- If the signed operand type can represent all the values of the unsigned operand type, the unsigned operand gets promoted to the signed type.
- Otherwise, both operands are converted to the unsigned type corresponding to the signed operand’s type.
It is important to keep these rules in mind, otherwise bugs may arise when mixing signed and unsigned integers. Consider this example:
int si = -1;
unsigned int ui = 1;
printf("%d\n", si < ui); // prints 0! si converted to unsigned int
We have a comparison between a signed int which is -1 and an unsigned int.
According to the rules the signed int gets converted to an unsigned int.
And the binary representation of -1 in memory when interpreted as an unsigned int, corresponds to the maximum value that can be stored in an unsigned int, which is about 4 billions
So the expression evaluates to false, which is 0 in C.
This is very counter-intuitive.
Integer Overflows
It is important to keep in mind the storage size of all types when mixing them in operations. Here’s another example of behaviour that can be surprising:
int main(int argc, char **argv) {
int i = -1000;
unsigned int ui = 4294967295;
printf("%d\n", i + ui); // prints -1001
// i: 11111111111111111111110000011000 (A)
// ui: 11111111111111111111111111111111 (B)
// i + ui: 111111111111111111111110000010111 (C)
// final: 11111111111111111111110000010111 (D)
// (A) originally 2's complement promoted to unsigned
// (B) standard unsigned representation, max number an unsigned int can store
// (C) addition result
// (D) result overflows 32 bits as an int (expected by %d), loosing MSB
// Solution: use %ld rather than %d to store the result on 64 bits
return 0;
}
We add a signed int, i, equal to -1000, to an unsigned int, ui, that is actually the maximum value we can store with that type.
i is promoted to an unsigned int, and because signed numbers are encoded with 2’s complement we have the leading ones in the binary representation.
ui being the maximum number that can be stored in an unsigned int, it is 32 bits full of ones.
The addition overflows and the most significant bit gets truncated.
What we obtain is the binary representation of -1001.
Integer to Floating-Point Conversion
Regarding floating point numbers, if an operand is float/double, the other gets converted to float/double.
This is another implicit conversion realised by the compiler.
Conversion spreads from left to right.
See the following examples with explanation in comments:
//prints 7: 25/10 rounds to 2; 2 * 15 = 30; 30/4 rounds to 7
printf("%d\n", 25 / 10 * 15 / 4);
// prints 7.5: 25/10 rounds to 2; 2*15 = 30; 30 gets converted to
// 30.0 (double) and divided by 4.0 (double) giving result 7.5 (double)
printf("%lf\n", 25 / 10 * 15 / 4.0);
// prints 9.375: 25.0 / 10.0 (converted from 10) is 2.5, multiplied by 15.0
// (converted from 15) gives 37.5, divided by 4.0 (converted from 4) gives
// 9.375
printf("%lf\n", 25.0 / 10 * 15 / 4);
// prints garbage, don't try to interpret a double as an int!
printf("%d\n", 25.0 / 10 * 15 / 4);
Implicit Conversion When Passing Parameters
Conversion also happens implicitly when calling functions. Consider this example:
void f1(int i) {
printf("%d\n", i);
}
void f2(double d) {
printf("%lf\n", d);
}
void f3(unsigned int ui) {
printf("%u\n", ui);
}
int main(int argc, char **argv) {
char c = 'a';
unsigned long long ull = 0x400000000000;
f1(c); // prints 97 (ascii code for 'a')
f2(c); // prints 97.0
f3(ull); // overflows int ... prints 0 (lower 32 bits of 0x400000000000)
return 0;
}
Here we have a character variable c containing 'a', passed as parameter to functions expecting int (f1) and double (f2).
Characters are encoded with ascii code, so when this data is interpreted as an int or a double, we get the ascii code for 'a': 97 or 97.0.
We also have a long long unsigned variable, ull, that is passed to a function expecting an unsigned int, but ull is too large for that.
So when printed within the function body we only see its lower 32 bits.
Note that this code, and all the faulty programs presented in this lecture, is perfectly legit from the compiler point of view: it will produce no warnings. Hence, it is really important to be aware of the various implicit conversion rules to avoid bugs, some of which may be quite hard to investigate and fix.
Type Casting
Type casting lets the programmer force a conversion. It is achieved by writing the target type between parentheses in front of the expression one wish to covert. For example here we cast an int into a float:
// prints 3.75: 4 gets converted to 4.0
printf("%lf\n", (float)15/4);
Here we cast a floating point number into an integer:
// prints 4: 2.5 converted to 2 (int), multiplied by 12 gives 24, divided by 5 gives 4
printf("%d\n", ((int)2.5 * 12)/5);
Another example:
// prints 4.8: 2*12 = 24, converted to 24.0, divided by 5.0 gives 4.8
printf("%lf\n", ((int)2.5 * 12)/(double)5);
Recall the example above in which an unsigned int equal to 1 was evaluated as not inferior to an int equal to -1 due to integer promotion.
This can be fixed that with a cast:
int si = -1;
unsigned int ui = 1;
printf("%d\n", si < (int)ui); // prints 1
We force the unsigned variable to be converted to a signed one, and we now compare two signed int.
Generic Pointers
In combination with the special type void *, casting also allows us to implement generic pointers in C.
Generic pointers allow a pointer parameter or return value to point to data of different types.
Consider the following code:
typedef enum {
CHAR, INT, DOUBLE
} type_enum;
void print(void *data, type_enum t) {
switch(t) {
case CHAR:
printf("character: %c\n",
*(char *)data);
break;
case INT:
printf("integer: %d\n",
*(int *)data);
break;
case DOUBLE:
printf("double: %lf\n",
*(double *)data);
break;
default:
printf("Unknown type ...\n");
}
}
We have a function that takes a void *`` generic pointer as parameter. According to a second parameter that is an enum, the function prints the value of what is pointed by the pointer. It can be a char, an int, or a double. When we call the function, we cast the pointers to these data types to void *. Of course, we need to indicate the type somewhere, in this case we use the enum`.
When printing the value, we use another cast to get the proper type.
Debugging with GDB
Here we discuss how to debug C programs with GDB, the GNU Debugger. You can access the slides 🖼️ for this lecture. All the code samples given here can be found online, alongside instructions on how to bring up the proper environment to build and execute them here.
Buggy Program
Consider the following program:
/* buggy-program.c: */
#include <stdio.h>
#include <stdlib.h>
#define ARRAY_SIZE 100
int fill_array(int *array, int size) {
for(int i=0; i<size; i++)
array[i] = rand()%10;
}
/* array[slot] = value */
int update_slot(int *array, int slot, int value) {
array[slot] = value;
printf("Updated index %d to %d\n", slot, value);
}
int process_array(int *array, int size) {
int ii = 1000000;
for(int i=0; i<size; i++) {
/* If the value is even, change it to 1000000 */
if(!(array[i] % 2)) {
update_slot(array, ii, i);
}
}
}
int main(int argc, char **argv) {
int *array = malloc(ARRAY_SIZE * sizeof(int));
fill_array(array, ARRAY_SIZE);
process_array(array, ARRAY_SIZE);
free(array);
return 0;
}
It contains a bug and crashes at runtime:
$ gcc buggy-program.c -o buggy-program
$ ./buggy-program
[2] 9983 segmentation fault ./buggy-program
This behaviour gives very little information about what actually went wrong.
Blindly debugging, e.g. by adding printf statements, to try to understand what happens is useful but very cumbersome, especially on large codebases.
We’ll use a debugger to easily find the bug.
Fixing the Issue with GDB
GDB is the GNU debugger, a command line tool that helps inspect the state of the program at runtime to understand and fix bugs.
To use it, the program should be compiled with debug symbols using the -g flag passed to the compiler:
$ gcc -g buggy-program -o buggy-program
$ gdb buggy-program
To launch the execution of the program within the debugger, use the run command:
(gdb) run
Program received signal SIGSEGV, Segmentation fault.
0x00005640b87c51fe in update_slot (array=0x56..., slot=1000000, value=1) at buggy-program.c:13
13 array[slot] = value;
The debugger executed the program until the crash happened.
It indicates us the faulty line of code, line 13 in buggy-program.c.
Something wrong happens when trying to write in a slot of the array.
We can see from the value of update_slot’s parameters that slot is way too large (1000000) with respect to the array size (100).
In effect the program tries to access the memory at address array + 1000000 * sizeof(int), which is probably not mapped, so a page fault happens, and the operating system kills the program.
That’s our bug, the programmer inverted the second and third arguments when calling update_slot.
Other Basic GDB Features
Breakpoints
Breakpoints can be placed at various locations (referenced by their line number in the source files) in the program.
When a breakpoint is hit during execution under the debugger, the program will pause and the debugger will let the user inspect the state of the program.
Here is an example, still using our buggy program, we want to pause the execution when entering the function fill_array which is at line 6:
(gdb) br buggy-program.c:6
Breakpoint 1 at 0x5640b87c5178: file buggy-program.c, line 7.
(gdb) run
Breakpoint 1, fill_array (array=0x5568886282a0, size=100) at buggy-program.c:7
7 for(int i=0; i<size; i++)
The execution starts and pauses when fill_array is called.
Notice that the debugger corrected the line to 7 of the source file, i.e. the first instruction of the function.
The user can then choose different ways to continue the execution of the program:
- The
continuecommand will resume execution until the next breakpoint/crash is hit. - The
stepcommand will execute the next line of code and will pause right after that. If that line of code is a function call, the debugger will dive into the function and the pause will happen on the first instruction of that function. - The
nextcommand will execute the next line of code and will pause right after that. If that line of code is a function call, the debugger will execute the entire function call before pausing on the next line of code of the calling context.
Breakpoints can be deleted with the del command, followed by the breakpoint identifier (e.g. 1 for the one seen above).
Printing Values and Addresses
During execution, when a breakpoint/crash is hit, the user can print values and addresses to inspect the state of the program with the p command:
(gdb) p array
$1 = (int *) 0x5568886282a0
(gdb) p array[0]
$2 = 0
(gdb) p size
$3 = 100
(gdb) p &size
$4 = (int *) 0x7ffdde0ba444
Navigating the Call Stack
When inspecting the state of the program, the user can go up and down the call stack with the up and down commands:
(gdb) up
#1 0x0000556886ba22ac in main (argc=1, argv=0x7ffdde0ba5a8) at buggy-program.c:31
31 fill_array(array, ARRAY_SIZE);
(gdb) down
#0 fill_array (array=0x5568886282a0, size=100) at buggy-program.c:7
7 for(int i=0; i<size; i++)
Conditional Breakpoints
The user can instruct GDB to pause execution when a breakpoint is hit only under certain condition, e.g. a variable having a certain value.
Here is an example in which we put a breakpoint in fill_array at the 42nd iteration of the loop:
br buggy-program.c:8 if i==42
Breakpoint 1 at 0x1181: file buggy-program.c, line 8.
(gdb) run
Breakpoint 1, fill_array (array=0x5586448b22a0, size=100) at buggy-program.c:8
8 array[i] = rand()%10;
(gdb) p i
$1 = 42
Further Resources
You can find a plethora of resources online regarding GDB, including its official documentation, as well as a reference card listing the most important commands for the tool. GDB’s interface can be heavily customised and made more user-friendly, see an example here.
Case Study: High Performance Computing
In this lecture we discuss a first case study of the application of C: High Performance Computing (HPC). You can access the slides 🖼️ for this lecture. All the code samples given here can be found online, alongside instructions on how to bring up the proper environment to build and execute them here.
C in HPC
C is extensively used in HPC because it is fast. This speed is due to many reasons. Contrary to more high-level programming languages (e.g. Python):
First, C is close to the hardware, there are few layers to traverse when calling system functions:

With Python your script need to run through the interpreter. With Java, things are similar with the JVM: these additional layers in high-level languages introduce many overheads compared to low-level ones such as C.
Another source of overheads in high-level languages like Python or Java is automatic memory protection and management. For example languages such as Java or Python have a garbage collector, that automatically takes care of dynamic memory management tasks. To enforce memory safety these languages also perform bounds checking e.g. when indexing an array. In C memory management is manual: there is no garbage collector, and there is also no memory protection. Although this creates more burden for the programmer, C avoids the related overheads with the goal of execution speed.
Another advantage of C is that it is very easy to integrate with assembly, which sometimes needs to be used to optimise specific operation for performance.
And last but not least, C gives the programmer control over the data memory layout. We discuss this particular aspect in this lecture, showing how useful it can be when optimising a program for performance.
Memory Hierarchy 101
Here is a quick recap about a subset of the memory hierarchy present on all computers:

The CPU has local memory in the form of registers, there are very few of these, between 10 and 30, and accessing them is very fast: data present in registers is instantaneously available for computations. Main memory stores most of the program data because it is large so bringing data from memory to registers for computations is slow: it can take hundreds of CPU clock cycles So we have this intermediary layer named the cache, it is made of a relatively small amount of fast memory (faster than the RAM, slower than registers) that holds a subset of the program’s data. Data is loaded in the cache from memory on demand when requested by the CPU, and the unit of transfer between memory and the cache is a cache line, generally 64 contiguous bytes, to exploit the principle of locality. So, to get the best performance possible for a program – and this is the goal in HPC – it is important to fit as much as possible of the program’s data in the cache.
Cache-unfriendly Program Example
Let’s discuss an example. Consider the following program:
typedef struct {
char c[60];
int i;
double d;
} my_struct;
#define N 100000000
my_struct array[N];
int main(int argc, char **argv) {
struct timeval start, stop, res;
my_struct s;
gettimeofday(&start, NULL);
/* Randomly access N elements */
for(int i=0; i<N; i++)
memcpy(&s, &array[rand()%N], sizeof(my_struct));
gettimeofday(&stop, NULL);
timersub(&stop, &start, &res);
printf("%ld.%06ld\n", res.tv_sec, res.tv_usec);
return 0;
}
This program accesses a large array of data structures.
The data structure contains a string member, an int member, and a double member.
In a relatively long loop the program uses memcpy to read from the array a given member from a random index.
We use gettimeofday to measure the execution time of the loop.
This program is extremely memory intensive, there is not much computation: it is memory-bound by the memory copy operations.
It turns out that this program is not very cache friendly.
If we look at the size of one member of the array, that is the sizeof my_struct, we can see that it’s 60 + 4 + 8 = 72 bytes.
This is slightly larger than a cache line which is 64 bytes, and the array is likely laid out into memory like that:

So most calls to memcpy in the program’s inner loop will require to fetch 2 cache lines from memory to be brought into the cache.
Fitting Data into the Cache
We can fix that issue by updating the structure and array definitions as follows:
typedef struct {
char c[52]; // down from 60, we have 52 + 4 + 8 == 64 bytes i.e. a cache line
int i;
double d;
} my_struct;
// force alignment of the array base address:
my_struct array[N] __attribute__ ((aligned(64)));
We reduce the size of the structure to be equal to that of a cache line.
More precisely we reduced slightly the size of the string so that the size of one instance of the data structure is 64 bytes.
Then we use the special keyword attribute to make sure that the array is aligned to a cache line.
In effect this will make that each member of the array is fully contained in a cache line:

On the computer this code was tested, this effectively speeds up the program by about 25%:

Such optimisations are possible in C because the language gives the programmer a large area of control over the program’s memory layout, in other word one can control the placement and sizes of data structures in memory.
Case Study: C Standard Library
Here we discuss another case study: the implementation of the C standard library. You can access the slides 🖼️ for this lecture. All the code samples given here can be found online, alongside instructions on how to bring up the proper environment to build and execute them here.
The C Standard Library
The C standard library, also abbreviated libc, is the library providing the implementation of functions declared in stdio.h, stdlib.h, etc., that we have been using since the beginning of the course.
It is written mostly in C, with a few bits of assembly.
The default library coming with Linux distribution such as Ubuntu/Debian or Fedora is the GNU Libc, Glibc.
It is very complex and difficult to study, so in this lecture we will rather have a look at a simpler C standard library named Musl.
Musl is a production-ready C standard library, and is widely used: for example the Alpine Linux container-oriented distribution ships with Musl as libc.
Using Musl
It is very easy to try out Musl. It can be downloaded, built, and used to build a small hello world C program as follows:
# Download musl
$ git clone https://github.com/ifduyue/musl.git
# Compile it and install it locally
$ cd musl
$ ./configure --prefix=$PWD/prefix
$ make
$ make install
# Write a hellow world and compile it against Musl rather than Glibc
# Don't forget the -static
$ ./prefix/bin/musl-gcc hello-world.c -o hello-world -static
$ ./hello-world
hello world!
In the rest of this document we take a brief look at how the libc works, and why it makes sense for it to be written in C.
The main job of the C library is to interface the application with the operating system.
To study this, let’s see how Musl implements the function we have been using the most, printf.
But before that, we need to understand how the C Library request services from the OS, through system calls.
System Calls
Letting application access the hardware directly is too dangerous.
So applications use system calls (abbreviated syscalls) to ask for services from the kernel, which is the only privileged entity that can directly manipulate the hardware to do things like reading and writing from/to disk, sending and receiving packets to/from the network card, printing to the console, etc.
Syscalls are rarely made directly by the user code: the programmer rather calls functions from the libc, which in turn takes care of invoking syscalls.
For example, to print to the console, the programmer calls printf, and if we look at its implementation within the libc code, we can see that it calls the write syscall (or a variant of it like writev).
Therefore, the libc provides wrappers to the user code around system calls.
Some wrappers have the same name as the system call in question such as write.
When a syscall is made, what happens under the hood is a bit more complex than a simple function call. There is a world switch of the CPU execution state, from user mode to privileged (kernel) mode. There is a particular convention on how this switch should happen, i.e. what are the machine instruction that user mode should issue to indicate to the kernel what syscall to run, and with what parameters.
The System Call Application Binary Interface
On Intel x86-64, an application wishing to issue a Linux system call uses the following machine instructions:
- First the syscall number is put in the
%raxregister. This number identify uniquely a given syscall, you can see the list of Linux syscalls and their numbers for x86-64 here. - The syscall parameters are put in
%rsi,%rdx,%r10,%r8, and%r9(in order). - Then the “syscall” instruction should be executed, this triggers a trap to the kernel and the OS will process the syscall.
- When done the kernel place the syscall return value in
%rax.
This is a convention put in place for communication between 2 entities: the program (that includes the libc) invoking the system call, and the kernel receiving the call and processing it. These 2 entities are compiled separately, hence for interacting they cannot use application programming interfaces (APIs), i.e. language level constructs such as functions, like one would normally do within a single program or between a program and a library it compiles against. They rather use directly machine instructions: it’s an application binary interface, ABI.
The Linux system call ABI is architecture-specific, but for other ISAs the principles are similar: the system call identifiers and arguments are set up in a set of predefined registers, then a special instruction is executed to trap to the kernel. Once the kernel is done, the system call return value will be placed by the kernel in a predefined register.
Musl’s Implementation of printf
printf is implemented in Musl’s sources in the src/stdio/printf.c file.
It calls vfprintf, which calls printf_core, which itself calls out.
All of these functions are in src/stdio/vfprintf.c.
Their job is to expand the token in the string passed to printf (e.g. %d) with the value of the corresponding variables.
For example, they transform "hello: %d, %lf", 12, 12.0" into "hello: 12, 12.00000".
out calls __fwritex which is in src/stdio/fwrite.c.
In __fwritex there is a call to a function pointer: f->write(f, s, i);.
We do not describe function pointers in details here (for more information please check the description of function pointers from Wikipedia), just know that this will lead at runtime to a call to __stdout_write(f, s, i).
That function is located in src/stdio/__stdout_write.c and calls __stdio_write in src/stdio/__stdio_write.c, which itself calls syscall(SYS_writev, f->fd, iov, iovcnt).
syscall is a macro expansion, defined in src/internal/syscall.h. This macro expands a series of other macro functions which, in the case of printf, will end up in a call to syscall3:
__syscall_3(SYS_writev, f->fd, iov, iovcount);
This will lead to a call to the writev system call with parameters f->fd, iov, and iovcount.
writev realises several write operations at once in a file descriptor, each characterised by a memory address to write from, and the amount of bytes to write: in other words it is equivalent to a series of calls to write on the same file descriptor.
The series of operation is described in an array of iovec data structures:
struct iovec {
void *iov_base; /* Starting address */
size_t iov_len; /* Number of bytes to transfer */
};
writev takes as parameter the file descriptor to write to, (in the call above, f->fd), the array of iovec structs (iov), and its size (iovcount).
At runtime f->fd will be 1, a special file descriptor representing the standard output.
Indeed, in UNIX-like operating systems such as Linux, everything is a file, and printing to the console is realised by writing to a (pseudo-) file representing the standard output.
syscall3 is a function defined in arch/x86_64/syscall_arch.h:
static __inline long __syscall3(long n, long a1, long a2, long a3) {
unsigned long ret;
__asm__ __volatile__ ( "syscall" : // 5) the syscall instruction
"=a"(ret) : // 6) we'll get the return value in rax
"a"(n), // 1) syscall number in rax
"D"(a1), // 2) argument 1 in rdi
"S"(a2), // 3) argument 2 in rsi
"d"(a3) : // 4) argument 3 in rdx
"rcx", "r11", "memory");
return ret;
}
This function will be inlined by the compiler wherever it is called, as indicated by the __inline keyword, hence it is fine to have its body implemented in the syscall_arch.h header file.
We will not go into the details of how inline assembly works here, but know that this generates the code adhering to the ABI previously described. In assembly and in the proper order, instructions will look approximately like this:
mov $20, %rax
mov $1, %rdi
mov <address of the iovec array>, %rsi
mov $1, %rdx
syscall
The steps are:
- The system call identifier of
writev(n, i.e.SYS_writev, i.e.20) is placed in%rax. - The 3 parameters (file descriptors, array of struct
iovec, size of the array) are placed in%rdi,%rsi, andrdx. - The
syscallinstruction is invoked. At that point the kernel starts to run to process the system call. We will discuss what happens there further in the next lecture. - When the kernel returns to the application from the system call execution, the return value of the system call (an
unsigned long) is present in%rax. In__syscall3it is placed in theretvariable, and returned up the call stack.
Hello World without Libc
Now that we know how to issue a system call to print on the console, an interesting exercise is to achieve that without the libc, i.e. without printf.
This can be done with the following program (that will work on Intel x86-64 CPUs only):
// nolibc.c
// Print "hello!" to the standard output without the C library, directly making a
// write syscall to stdout file desccriptor (by convention 1)
// Notice the abscense of '#include': we don't want to use the libc
/* Without libc the default entry point is _start */
void _start() {
unsigned long ret;
/* Write syscall */
__asm__ __volatile(
"syscall" : // the syscall instruction
"=a"(ret) : // we'll get the return value in rax
"a"(1), // syscall number (1 for write)
"D"(1), // argument1: file descriptor (1 for stdout)
"S"((long)"hello!\n"), // argument2: char array to print
"d"(7) : // argument3: number of bytes to write
"rcx", "r11", "memory");
/* exit syscall to quit properly */
__asm__ __volatile( "syscall" : : // syscall instruction
"a"(60), // exit's syscall number
"D"(0) : // exit parameter: 0
"rcx", "r11", "memory");
}
This program issues 2 system calls: one write to the standard output, followed by exit to terminate the program.
It can be compiled without the libc and executed as follows:
$ gcc -nostdlib nolibc.c -o nolibc
$ ./nolibc
hello!
Case Study: Operating System Kernel
Here we discuss a last and third use case where using C is appropriate: the implementation of an operating system (OS) kernel. You can access the slides 🖼️ for this lecture. All the code samples given here can be found online, alongside instructions on how to bring up the proper environment to build and execute them here.
System Calls and Context Switches
Because of its proximity with the hardware and performance, C is heavily used in OS kernels. Here we will study how two key OS operations are implemented: system call and context switch. We already talked about how user space programs invoke system calls in the previous lecture regarding the C standard library. Here we’ll get an overview of how they are handled on the kernel side. Regarding context switches, it corresponds to the action of replacing a task running on the CPU by another one:

We’ll see an overview of how the kernel manages that, by studying the Linux kernel code. Linux is used absolutely everywhere: in all Android phones and most embedded or IoT systems, on the majority of server computers, as well as super computers. Linux also happens to be the operating system currently running on my computer.
System Calls in a Nutshell
When a user space task is executing on the processor, the CPU state of this task consists in the values present in the processor registers:

We have general purpose registers used for computations, but also special-purpose ones such as stack and instruction pointers. As its name suggests, the stack pointer points to the stack, a contiguous memory area used to store various things such as local variables. The instruction pointer (also known as program counter) points to the instruction currently executed by the CPU, located inside the program code in memory. When running user programs the CPU is in user mode, i.e. for security reasons it cannot perform privileged operations which execution is reserved to the kernel, such as installing a new page table or shutting down the CPU.
When the system call instruction is issued (e.g. syscall for x86-64), the CPU switches to supervisor mode, also known as kernel mode, giving it the permission to execute every operation supported by the CPU, including privileged ones.
The CPU also jumps to a predefined system call handler in the kernel, which switches to the kernel stack:

The kernel starts by saving the application state by pushing all registers on the kernel stack:

Then the kernel determines which system call is invoked (e.g. on x86-64 by looking at the system call identifier in %rax) and starts processing it.
When the system call has been processed, the kernel restores the task state by popping all the registers from the kernel stack:

And then user space execution resumes at the next instruction following the system call invocation instruction:

Context Switches in a Nutshell
Let’s assume a single core CPU, with a task running (scheduled) on the CPU, we’ll call it task A. We also assume a task B that is currently sleeping, i.e. it is not scheduled. Each task has its code and data (including its stack) in memory. In memory, we also have the kernel code, as well as a kernel stack for each task A and B:

Context switch should be done by the kernel, so let’s assume at some point there is a trap to the kernel, either due to a system call or a hardware interrupt:

After the interrupt is treated, in many OSes the scheduler will check if there is a task ready with a higher priority than the one currently running. Let’s assume task B is ready, and its priority is higher than the currently running task A. The scheduler then decides to run B instead of A and a context switch is needed.
The context switch operation starts by saving the state of the task getting scheduled out of the CPU, A, pushing all of its registers’ values on its kernel stack:

Next the state of task getting scheduled, B, is restored from its own kernel stack, where it was previously saved the last time that task was scheduled out:

Then the execution of B can resume, in kernel mode first:

Then the kernel returns to user space, and B resumes:

System Call and Context Switch Implementations in a Real OS
Let’s explore in a real world operating system how system call handling and context switching are implemented. We are going to have a look at how the Linux kernel code. Its code is obviously relatively complex, and we will not discuss most of the code present in the files and functions we will look at here: we will only focus on the key operations for you to get a good idea of how things work from a high level point of view.
A great way to browse the Linux kernel source is Elixir. All the references to the code we make below will point to this website.
We are going to study the code path in the kernel when an application calls the sleep function.
It is implemented by the C standard library which will invoke the nanosleep system call to ask the kernel to put the calling program to sleep, which will force a context switch on the CPU to schedule in another task ready to run.
So it’s an exact illustration of the scenario we have depicted earlier.
1. System Calls: Entering the Kernel
1.1. System Call Entry Point
We have seen in the previous lecture on the C standard library that a user space program invokes a system call on x86-64 with the syscall instruction.
When it is executed by the C library wishing to invoke the nanosleep system call, there is an exception and the user space program’s execution is interrupted.
The CPU switches to supervisor mode, and jumps to a predefined piece of kernel code, the system call entry point.
When kernel code runs following a system call or any other form of interruption of user space code execution (e.g. a hardware interrupt received while a user task is running), we say that the kernel is running in the context of the task that was interrupted, and that task is named the current task.
The overwhelming majority of kernel code invocations are made in the context of a user space task.
The kernel defines the system call entry point as the label entry_SYSCALL_64 in an assembly file.
The assembly code starts by saving the user stack pointer in a scratch space and switching the stack pointer register (%rsp) to a kernel stack, as sharing a stack between user and kernel space would be unsafe:
movq %rsp, PER_CPU_VAR(cpu_tss_rw + TSS_sp2) // save user stack pointer
/* ... */
movq PER_CPU_VAR(pcpu_hot + X86_top_of_stack), %rsp // load kernel stack pointer
Next, through a series of stack push (pusq instruction) operations, the values of many CPU registers that correspond to the current task’s user state when it invoked syscall are pushed on the kernel stack.
The user CPU state needs to be saved so that it can be restored later when the application resumes: doing so the interruption that corresponds to handling the system call will have been completely transparent to the application’s execution.
Most of that state saving job is realised with the macro PUSH_AND_CLEAR_REGS which expands among other things into a series of pushq for the general purpose registers:
PUSH_AND_CLEAR_REGS rax=$-ENOSYS
After that the system call entry point is going to jump to a function in C code.
This function takes 2 arguments.
The first parameter is a pointer to a data structure of type pt_regs containing the state of the CPU that was just pushed to the stack (register’s values at the time the application invoked syscall).
The second is the identifier for the system call being invoked: in the case of nanosleep it will be 35.
Remember the calling conventions: the first parameter of a function is passed in the %rdi register, and the second in %rsi.
movq %rsp, %rdi
movslq %eax, %rsi
Here, the value of the stack pointer, which is a pointer to the task user state pt_regs that was just pushed to the stack is written in %rdi.
Also remember that the system call convention states that the system call identifier should be set in %rax: its lower 32 bits (aliased as %eax, there are only about 400 system calls, so 32 bits is largely enough to identify them all) are moved to %rsi.
The system call entry point finally jumps to C code by calling the do_syscall_64 function:
call do_syscall_64
Assembly files can be assembled into object files which can be linked with other object files resulting from the compilation of C code into an executable program. As seen above symbols (e.g. function names, global variables) can be shared: C functions can be called from assembly, and C code can jump to assembly labels.
1.2. System Call C Handler
As mentioned earlier, do_syscall_64 takes the registers’ state and system call identifier as parameters:
__visible noinstr bool do_syscall_64(struct pt_regs *regs, int nr);
It calls do_syscall_x64 which itself calls x64_sys_call.
That function looks like this:
long x64_sys_call(const struct pt_regs *regs, unsigned int nr)
{
switch (nr) {
#include <asm/syscalls_64.h>
default: return __x64_sys_ni_syscall(regs);
}
};
It’s a switch case on the identifier of the system call that was invoked by the current task.
The code embedded in the middle with #include is a jump table mapping each system call identifier to the corresponding C function handling that system call in the kernel.
The included code is automatically generated at compile time from the Linux system call table.
For example for the nanosleep system call we have the following entry:
35 common nanosleep sys_nanosleep
So in the case of that system call being invoked, the switch in x64_sys_call will jump to sys_nanosleep.
1.3. Implementation of nanosleep
sys_nanosleep calls hrtimer_nanosleep, itself calling do_nanosleep that contains the core logic of the sleep operation: the function schedule is called in a loop as long as the nanosleep delay is not spent.
That function is implemented by the Linux scheduler, and will effectively set the current task to sleep and trigger a context switch to another task ready to run.
2. The Scheduler
2.1. Grabbing Task Structs
schedule calls __schedule_loop, which itself calls the main scheduler function: __schedule.
It is called on 2 occasions:
- When a user programs explicitly blocks, e.g. our example with
nanosleep. - Upon return from interrupt or system call.
This function first obtain a data structure of type task_struct representing the current task into a variable named prev:
cpu = smp_processor_id();
rq = cpu_rq(cpu);
prev = rq->curr;
Here cpu identifies the core executing the code, and rq is its runqueue: the list of tasks ready to run on that core.
Next the scheduler gets the task_struct of the next task that should run on this core:
next = pick_next_task(rq, prev, &rf);
The rules based on which the next task to run is selected are many, and depend on the model of the scheduler used (Linux has several schedulers): it can be based on priorities, fair division of time between tasks, etc.
Here just know that next is the task struct of whatever task the scheduler decided was going to run on the current core next.
In the rest of this document we will refer to the task being scheduled out of the CPU as the previous task (here
prev), and to the task to be scheduled as the next task (next).
2.2. Disabling Interrupts
A bit earlier in the __schedule function, interrupt are disabled with local_irq_disable, which ends up calling native_irq_disable which is an architecture specific function.
For x86-64 it looks like this:
static __always_inline void native_irq_disable(void)
{
asm volatile("cli": : :"memory");
}
Here inline assembly is used to call the cli x86-64 instruction that effectively disables interrupts.
As a side note we have here what may look like a function implementation within a header file, something we previously said was not OK. In this case this is actually fine, because the function in question is declared as inline.
2.3. Determining if a Context Switch is Needed
Let’s go back to __schedule.
At that stage the kernel checks if the next task is different from the previous one:
if (likely(prev != next)) {
If prev and next represent the same task, there is no need for a context switch: the function will return, and soon the kernel will return to the current task for it to resume.
If the tasks are different, then the kernel needs to context switch to the next task.
To that aim the context_switch function is called.
3. Context Switch
As explained earlier the context switch consists in switching the content of many CPU registers from the state that corresponds to the execution of the previous task to that of the next task. Notable registers which value is switched include:
- The general purpose registers.
- The stack pointer (each task has its own kernel stack).
- The register holding the root of the page table, because each task has its own address space.
Note that here we are running kernel code and the context switch happens in kernel context: we’ll be switching the CPU state of the kernel running in the context of the previous task to the state of the kernel running in the context of the next task. This is not to be mixed up with the user to kernel state switching we have seen earlier, that happens upon system calls and other forms of interrupts.
3.1. Switching Page Tables
context_switch takes as parameters the runqueue for the current core, pointers to the previous and next tasks, as well as to some flags.
It starts by checking what type of task we are switching to:
if (!next->mm) {
Tasks can be either standard user space programs, or kernel threads.
Switching to a kernel thread (when next->mm is 0) does not require a page table switch because the memory corresponding to the kernel is mapped in the address space of all user programs (although for obvious security reasons not directly accessible from user code): the address space currently in use is that of the previous task, and it will contain all the kernel memory that any kernel thread may need to address.
If we are switching to a standard user space task, we need to switch page tables to install its address space.
This is the job of switch_mm_irqs_off, which executes a bunch of code and in particular switches the content of the %cr3 x86-64 register holding the root of the page table with native_write_cr3:
static inline void native_write_cr3(unsigned long val)
{
asm volatile("mov %0,%%cr3": : "r" (val) : "memory");
}
Here the inline assembly takes val (root of the page table of the next task) and use the mov instruction to write it in %cr3.
3.2. Switching Stack Pointer and General Purpose Registers
Now that the page table is taken care of we have loaded the address space of the next task.
The CPU state corresponding to this task now needs to be switched too.
If we go back to context_switch, at that stage it will call switch_to to handle that, which itself will call the x86-64 architecture-specific function __switch_to_asm.
This function is defined in an assembly file, and contains the core logic of the CPU state switch:
pushq %rbp
pushq %rbx
pushq %r12
pushq %r13
pushq %r14
pushq %r15
movq %rsp, TASK_threadsp(%rdi)
movq TASK_threadsp(%rsi), %rsp
popq %r15
popq %r14
popq %r13
popq %r12
popq %rbx
popq %rbp
jmp __switch_to
At the beginning of the function the stack pointer (register %rsp) still references the previous task’s stack.
The callee-saved registers representing the previous task’s CPU kernel state are saved on that stack with a series of push instructions.
Then the previous task’s stack pointer is saved on the stack with a movq instruction, and the next task’s stack pointer is installed with another movq.
Now that the stack pointer references the stack of the next task, with a series of pop instructions the values of the callee-saved registers for that task are loaded.
These values were previously saved on the next task’s stack the last time it was scheduled out of the CPU (i.e. it is the next task’s CPU kernel state), similarly to what we just described for the previous task.
Finally, the code goes back to C by jumping to __switch_to.
__switch_to takes care of saving/restoring more CPU state including segment registers, floating point registers, among others.
When __switch_to returns, the next task is now the current task.
In other words the kernel now executes in the context of the next task: as you know the return path is defined by the values of return addresses stored on the stack, so we take the next task’s return path up to schedule, which itself returns to whatever part of the kernel code invoked it the last time the next task was scheduled out.
4. System Call: Exiting the Kernel
Let’s assume that at this occasion the next task was scheduled out following an explicit system call to nanosleep.
schedule returns back to do_nanosleep, which exits its waiting loop and returns to hrtimer_nanosleep, which itself return to the top level implementation of nanosleep, i.e. sys_nanosleep.
The system call handling code returns back from do_syscall_64 in the assembly system call entry point.
The user space state of the next task is then popped from the stack where it was saved the last time the task entered the kernel (when it called nanosleep):
POP_REGS pop_rdi=0
POP_REGS expands into a series of popq instructions restoring the value for general purpose registers.
The kernel stack pointer is then saved to a scratch space, and from that scratch space the user space stack pointer is popped into %rsp:
movq %rsp, %rdi
movq PER_CPU_VAR(cpu_tss_rw + TSS_sp0), %rsp
pushq RSP-RDI(%rdi) /* RSP */
/* ... */
popq %rsp
Finally, we exit kernel code to return to user space:
sysretq
The sysretq instruction switches the processor mode from supervisor to user (i.e. unprivileged) mode, and jumps to the first user space instruction after syscall: the application resumes its execution.
Conclusion
And that’s it! Through this example we have seen how C is a very practical language for writing operating systems as they require, for some very specific operations such as system call handling and context switching, close interactions with assembly code (inline as well as in the form of assembly files) as well as full control over the location/layout of data structures in memory.
Building C Programs: Exercises
See here how to set up a development environment to do these exercises.
- You should complete the essential exercises if you want to claim you know how to program in C.
- If you want to go further and make sure you understand everything, you can also complete the additional exercises.
Essential Exercises
- Using macros
- Conditional code inclusion
- Modules: breaking down a program into several source files
- Using makefiles
- Type casting
Using Macros
The program macro.c generates a series of random numbers and outputs the distribution of their value into several bins:
./macro
bin 0: [000 - 020[ *******************
bin 1: [020 - 040[ *******************
bin 2: [040 - 060[ *******************
bin 3: [060 - 080[ **********************
bin 4: [080 - 100[ ******************
There are several redundant hardcoded numbers in the code of macro.c that should rather be defined as macros (constants) to ease the code clarity and the possibilities of evolution.
Fix this problem by introducing at least 2 macros:
SAMPLE_SIZEdefining the size (i.e. number of integers) of the array manipulated by the program – currently 1000 in the provided code sampleMAX_VALdefining the value that the generated random integers can take as the range[0 - MAX_VAL[, currently 100 in the code sample.
Define these macros to be 10 for SAMPLE_SIZE and 50 for MAX_VAL.
An example of expected output is:
./macro
bin 0: [000 - 010[
bin 1: [010 - 020[ **********
bin 2: [020 - 030[ ********************
bin 3: [030 - 040[ **************************************************
bin 4: [040 - 050[ ********************
To check the correctness of your program, use a use a Linux distribution with check50 installed and write your solution in a file named macro.c.
In a terminal, with that file in the local directory, check with this command:
check50 -l --ansi-log olivierpierre/comp26020-problems/2025-2026/week4-compilation/01-macro
Conditional Code Inclusion
The program macro-conditional.c is a variant of the program presented in the previous exercise, where many debug messages are printed on the standard output:
./macro-conditional
[DEBUG] Allocating memory
[DEBUG] Allocation successfull
[DEBUG] Filling array
[DEBUG] Generated 1000 random numbers
[DEBUG] Dividing numbers into bins
[DEBUG] Printing results
bin 0: [000 - 020[ ********************
bin 1: [020 - 040[ *******************
bin 2: [040 - 060[ ********************
bin 3: [060 - 080[ ********************
bin 4: [080 - 100[ *******************
[DEBUG] Printing done
[DEBUG] Memory freed
Update the program so that the display of the debug output happens only when the macro DEBUGMODE is defined.
Do not define the macro itself in the code, we will rather use the -D gcc parameter to do so at compile time:
gcc -DDEBUGMODE macro-conditional.c -o macro-conditional
./macro-conditional
# Debug output displayed
gcc macro-conditional.c -o macro-conditional
./macro-conditional
# Debug output suppressed
To check the correctness of your program, use a use a Linux distribution with check50 installed and write your solution in a file named macro-conditional.c.
In a terminal, with that file in the local directory, check with this command:
check50 -l --ansi-log olivierpierre/comp26020-problems/2025-2026/week4-compilation/02-macro-conditional
Modules: Breaking Down a Program into Several Source Files
The objective is to break down the program module.c into several modules:
module1.cand the corresponding headermodule1.h, containingmodule1_function1andmodule1_function2module2.candmodule2.hcontainingmodule2_function1module3.candmodule3.hcontainingmodule3_function1andmodule3_enummain.ccontaining themainfunction.
Take care of including in C files only the necessary headers. The expected output is:
./module
module3_function1 called with parameter CASE2
res1: 84
res2: 1.000000
res3: 1595255563434
To check the correctness of your program, use a use a Linux distribution with check50 installed. In a terminal, with all the mentioned source files in the local directory, check with this command:
check50 -l --ansi-log olivierpierre/comp26020-problems/2025-2026/week4-compilation/03-module
Using Makefiles
Consider the program compiled from the following files:
- main.c
- module1.c and the corresponding header module1.h
- module2.c and the corresponding header module2.h
Write a Makefile automating the compilation of this program.
It should contain intermediate rules compiling 1) C source files into object file and 2) linking object files into the final executable which name should be prog.
Include also a clean rule to delete the executable and intermediate object files.
You can download all the aforementioned source filed in a compressed archive here.
To check the correctness of your program, use a use a Linux distribution with check50 installed. In a terminal, with all source files as well as the Makefile in the local directory, check with this command:
check50 -l --ansi-log olivierpierre/comp26020-problems/2025-2026/week4-compilation/04-makefile
Type Casting
Complete the program cast.c by writing the generic array printing function array_print:
#include <stdio.h>
typedef enum {
INT,
CHAR,
FLOAT
} array_type;
void array_print(void *ptr, int size, array_type type) {
/* complete here */
}
int main(int argc, char **argv) {
int int_tab[3] = {1, 2, 3};
char char_tab[2] = {'a', 'b'};
float float_tab[3] = {2.5, 1.1, 12.42};
array_print(int_tab, 3, INT);
array_print(char_tab, 2, CHAR);
array_print(float_tab, 3, FLOAT);
return 0;
}
The expected output is:
[1, 2, 3]
[a, b]
[2.500000, 1.100000, 12.420000]
To check the correctness of your program, use a use a Linux distribution with check50 installed and write your solution in a file named cast.c.
In a terminal, with that file in the local directory, check with this command:
check50 -l --ansi-log olivierpierre/comp26020-problems/2025-2026/week4-compilation/05-cast
Additional Exercises
Header Inclusion
Consider the program constituted of the following two source files: preprocessor.c and preprocessor.h.
This program fails to compile due to missing header inclusions. Correct these issues by writing the proper include preprocessor directives. The expected output is:
./preprocessor
Please enter the amount of random number to generate:
10000000
Generated 10000000 numbers in 0.084871 seconds
To check the correctness of your program, use a use a Linux distribution with check50 installed. In a terminal, with the source file in the local directory, check with this command:
check50 -l --ansi-log olivierpierre/comp26020-problems/2025-2026/week4-compilation/06-preprocessor
Type Casting (2)
In C, characters are encoded in memory using ascii code.
Knowing that there is a constant offset between the code for a given letter in lowercase and the code for that letter in capital, complete the capitalize function in the program ascii.c presented below:
#include <stdio.h>
char *alphabet = "abcdefghijklmnopqrstuvwxyz";
char capitalize(char c) {
/* complete here */
}
int main(int argc, char **argv) {
for(int i=0; i<26; i++)
printf("capital %c: %c\n",
alphabet[i], capitalize(alphabet[i]));
return 0;
}
Ascii code in C.
- When printed as an integer with the
%dmarker, the ascii code for a givencharvariable can be displayed.- You can also check out some ascii tables such as this one.
The expected output is:
capital a: A
capital b: B
capital c: C
capital d: D
capital e: E
capital f: F
# ...
capital z: Z
To check the correctness of your program, use a
use a Linux distribution with check50 installed
and write your solution in a file named ascii.c. In a
terminal, with that file in the local directory, check with this command:
check50 -l --ansi-log olivierpierre/comp26020-problems/2025-2026/week4-compilation/07-ascii
Investigating a Bug with GDB
The following program, bug.c, contains several memory corruption bugs:
#include <stdio.h>
#include <stdlib.h>
int array[1000];
int main(int argc, char **argv) {
int x;
for(int i = 0; i < 10000; i++){
int ran_num = rand()% 1000;
array[i] = ran_num;
}
printf("Please enter an integer between 0 and 9999: ");
scanf("%d", x);
printf("array[%d] = %d\n", x, array[x]);
}
Use GDB to debug this program and fix the bugs. An example of expected execution is as follows:
Please enter an integer between 0 and 9999: 10
array[10] = 362
Note that you won’t necessarily get 362 as the array’s content is generated randomly, the important part is that the program does not segfault.
To check the correctness of your program, use a use a Linux distribution with check50 installed and write your solution in a file named bug.c.
In a terminal, with that file in the local directory, check with this command:
check50 -l --ansi-log olivierpierre/comp26020-problems/2025-2026/week4-compilation/08-bug
Memory Safety
Here we discuss a problem that is inherent to C: the fact that the language is not memory-safe. You can access the slides 🖼️ for this lecture. All the code samples given here can be found online, alongside instructions on how to bring up the proper environment to build and execute them here.
Memory Unsafety in C Programs
C is not memory-safe.
This means that there is no protection against a range of bugs when dealing with memory accesses.
These bugs can relate to spatial safety: in C the programmer is free to read or write anywhere he/she wants to in memory.
Bugs in this category include out of bound array accesses and bad pointer dereference (e.g. pointer being NULL or mistakes in pointer arithmetics).
Other bugs relate to temporal safety: the compiler cannot check things like accessing a dynamically-allocated buffer after it has been freed: this is a use-after-free.
These bugs lead to undefined behaviour: it can be a crash if the memory accessed is not mapped (remember the virtual address space is overall scarce), or incoherent (and hard to debug) behaviour when the memory accessed is mapped but does not contain what the programmer expects.
C is not memory safe for various reasons, including performance: adding runtime checks against these bugs is in theory possible, but it hurts performance. There is no bound check on buffers and array accesses. Uninitialised variables generally contain random garbage. Dynamic memory allocation can lead to a lot of mistakes that won’t be caught by the compiler. Such as memory leaks, double free, use-after-free, and so on. All these issues are hard to detect and to debug. They can also be hard to reproduce: sometimes the bug only manifest after a long time, several executions, or on a particular platform. An important thing to note is that, in addition to crashes, which in some sense are a good outcome because they indicate something needs to be fixed, these memory issues can have dramatic implication in terms of security.
The lack of memory safety in C/C++ is very problematic: recent numbers by Google and Microsoft show that about 70% of the security vulnerabilities found stem from memory safety-related bugs. The NSA reports that the most prevalent type of disclosed software vulnerabilities are memory safety ones, and encourage, among others, the transition to memory safe languages. That transition is however not going to happen overnight given the huge amount of legacy/existing software written in memory unsafe languages.
Below we study 4 examples of memory bugs that lead to security issues.
Example 1: Infoleak
The first example regards the leak of confidential information. Let us assume the following scenario: a security-sensitive program is distributed in binary-only form. It contains sensitive data: a password. An attacker has access to the binary of the program (not to the sources), and aims to figure out the password.
This is the program in question:
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
char *welcome_message = "Hi there! How is it going?\n"; // 27 char
char *password = "secret";
char entered_password[128];
int main(int argc, char **argv) {
// Print welcome message character by character
for(int i=0; i<27; i++) {
printf("%c", welcome_message[i]);
}
printf("Please input the password:\n");
scanf("%s", entered_password);
if(!strcmp(entered_password, password)) {
printf("Passowrd ok!\n");
/* ... */
} else {
printf("Wrong password! aborting\n");
}
return 0;
}
The program checks a platform entered by the user using scanf.
It starts by printing a welcome message character by character.
Then asks for a password from the user and compares the input to the correct password.
If the password is correct, the program then goes on to do something important.
As the program is distributed in binary-only form, unauthorised users do not have access to the sources and cannot see the password.
Let’s assume that during an update, the welcome message is updated as follows:
char *welcome_message = "Hi there!\n"; // shortened welcome message, only 11 chars now
Let’s assume that the programmer forgets to update the number of iteration of the for loop printing that message.
The message being now much smaller, the printing loop will overflow the welcome_message string and print whatever bytes are present next in memory.
It may just be garbage… or not: due to how the compiler lays out variables in memory, there are actually good chances that the password is very close to the welcome message in memory.
The password is in fact located right after it.
So the printing loop overflows the welcome message and reads bytes from password, and the password is leaked to the standard output:

Running the faulty program gives:
$ ./infoleak-updated
Hi there!
secretPlease inPlease input the password:
Example 2: Sensitive Data Tampering
Let’s consider a second example, regarding the same type of program performing a password check. We assume a scenario similar to the precedent example: a user attempting to authenticate will first input the password, that value will be compared to the ground truth stored somewhere in the program. The difference is in the attack: the attacker will not try to leak the password, but rather to bypass the password check.
Consider this program:
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
char user_input[32] = "00000000000";
char password[32] = "secret";
int main(int argc, char **argv) {
if(argc != 2) {
printf("Usage: %s <password>\n", argv[0]);
return 0;
}
strcpy(user_input, argv[1]); // oopsie!
if(!strncmp(password, user_input, strlen(password))) {
printf("login success!\n");
/* do important stuff ... */
} else {
printf("wrong password!\n");
exit(-1);
}
return 0;
}
You can find the full version of this program here.
It takes the password as command line parameter.
The password is copied in a buffer user_input.
The content of that buffer is then compared with the correct password, and if they match the program continues.
The issue is that there are no checks done by strcpy regarding the sizes of the source and destination strings.
In memory, it is very likely that the compiler will place the correct password right after the user_input buffer:

If the user passes a string as command line parameter which size is larger than the 32 bytes of that buffer, strcpy will overflow user_input and start overwriting the password:

The user hence has the capacity to rewrite the correct password with the value of his/her choice.
That value should be the same as the first 25 bytes that will go into user_input, so that when strcmp is called the strings will match:

An example of execution:
$ ./tampering xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
login success!
Example 3: Stack Smashing
Stack smashing is an old attack where a buffer overflow can be exploited on the stack to take over the control flow of an application. It was originally presented in 1996. Before going over the attack with an example, we first have to understand how the machine uses the stack to manage function call and return operations.
Functions from the Machine Code Point of View
The stack is a dynamic data structure in memory.
It holds, among other things, local variables as well as function parameters and return values.
The space on the stack dedicated to a function’s data (local variables, etc.) is contiguous in memory, it is called the function’s stack frame.
When a function is called, the stack’s size is increased to create the corresponding frame.
In addition to the function’s data, its frame also contains the return address.
This is the address in the program’s code (that is present somewhere else in memory) to which the CPU will jump once the function returns.
The central idea of stack smashing is to overwrite the return address of a function f with the address of code the attacker wishes to execute (e.g. the successful branch of a password check): when f returns, rather than returning to f’s caller, the program jumps to the target code.
In the example below we have the stack in the program’s memory on the left, the machine code executed on the right, and the corresponding C code in the middle.
Assume the CPU runs the machine code corresponding to the C function’s f at the point where the function g is called: on x86-64 this is a callq instruction.
This instruction pushes the return address on the stack, and jumps to g:

When g returns (ret x86-64 machine instruction), this return address is popped from the stack, and the CPU jumps to it, i.e. it jumps to the instruction in f that is right after the call to g:

Target Program
Consider this program:
char *password = "super-secret";
void caesar_encrypt(char* text) { /* ... */ }
void security_critical_function() {
printf("launching nukes!!\n");
}
void preprocess_input(char *string) {
char local_buffer[16];
strcpy(local_buffer, string); // Oopsie!
/* work on local buffer ... */
return;
}
int main(int argc, char **argv) {
if (argc != 2) {
printf("usage: %s <password>\n", argv[0]);
return -1;
}
preprocess_input(argv[1]);
if(!strncmp(password, argv[1], strlen(password)))
security_critical_function();
else
printf("Unauthorized user!\n");
return 0;
}
This program takes a password attempt as command line parameter.
It is passed through a function preprocess_input that copies the parameter value in a local buffer with strcpy, and perform some processing on that copy (what it does is not important here).
Back in main, the password attempt is checked against the correct password with strncmp.
If the authentication succeeds, we execute a security critical function.
There is a bug in this program: strcpy does not check for the size of string prior to copying it in local_buffer, letting the attacker overflow that buffer if data passed on the command line is larger than 16 bytes.
local_buffer is a local variable, hence it is allocated on the stack.
Similarly to the other examples, assume an attacker that only has access to the program’s binary, and that does not know the password.
The Attack
With stack smashing we will use this overflow to overwrite the return address of preprocess_input with the address of security_critical_function in order to bypass the password check.
This is possible because on x86-64 the stack grows down, from higher to lower addresses.
The return address is located after local_buffer on the stack:

Overflowing local_buffer it with strcpy allows overwriting the return address with whatever the attacker inputs from the command line:

The schema represents the state of the stack at the time preprocess_input runs and strcpy is called.
We have the calling context (main) local variables first.
Then the return address that was pushed when we called preprocess_input.
And then preprocess_input’s frame with its local variables including local_buffer.
Remember that because the stack grows down, lower addresses are on the bottom of this graph, so when we overflow local_buffer we are effectively writing up the top of the stack towards the return address
By using a carefully crafted input string, we can overwrite the return address with the address of a function we would like to execute.
For example the address of security_critical_function.
And when the execution returns from preprocess_input, the CPU will jump to security_critical_function rather than returning to main: the password check is bypassed.
See the complete program’s sources here for instructions on how to reproduce this attack. On the computer this code was tested, the payload (injected with echo -e and xargs to produce bytes and not ascii characters) looks like this:
$ echo -e "\x11\x11\x11\... (24 bytes of \x11 padding) ... \x5e\x17\x40\x00\x00\x00\x00\x00" \
| xargs --null -t -n1 ./stack-smashing
./stack-smashing ''$'\021\021\021\021\021\021\021\021\021\021\021\021\021\021\021\021\021\021
\021\021\021\021\021\021''U'$'\026''@'
launching nukes!!
xargs: ./stack-smashing: terminated by signal 11
Example 4: Use-After-Free
A use-after-free happens when the programmer mistakenly uses an object after it has been freed. Consider this program:
typedef struct {
double member1;
double member2;
void (*member3)(int);
} my_struct;
void print_hello(int x) {
printf("Hello, parameter: %d\n", x);
}
void security_critical_function() {
printf("Launching nukes!\n");
/* ... */
}
int main(int argc, char **argv) {
/* allocate and init ms */
my_struct *ms = malloc(sizeof(my_struct));
ms->member1 = 42.0; ms->member2 = 42.0;
ms->member3 = &print_hello;
/* call the function pointer */
ms->member3(12);
free(ms);
char *buffer = malloc(12);
strcpy(buffer, argv[1]);
ms->member3(12); // Oopsie!
exit(0);
}
Here ms is allocated with malloc, then freed, then mistakenly used right before the call to exit(0).
This issue is not caught by the compiler, and in many scenarios will not manifest either at runtime.
If we look at the data structure declaration, it has an int member and a second member that is a function pointer.
A function pointer is a variable that can store the address of a function, see how it is assigned in main: ms->member3 = &print_hello;.
We put the address of the print_hello function in the member.
And this function can be called through the function pointer, as it also done later: ms->member3(12);.
Between the moment what is pointed by ms is freed and the use-after-free, a buffer pointed by buffer is allocated with malloc and a command line parameter is copied in that buffer with strcpy.
Note the lack of check on the size of the command line argument: once again the attacker can overflow the memory pointed by buffer.
Let’s see how we can exploit use this program to force the execution of security_critical_function, that is not supposed to be called in this particular program. The central idea behind many attacks leveraging a use-after-free vulnerability is to replace the data structure being used after free with a payload that will corrupt the behaviour of the program once the use-after-free happens.
buffer, as well as what is pointed by ms, are allocated on the heap:

ms is then freed:

malloc manages allocations on the heap, and to avoid memory waste malloc will reuse freed memory to serve new allocation requests: in other words, it is very likely that the memory used to hold what was pointed was ms will be reused for buffer.
Recall that through the buffer overflow, the attacker has control over the content of buffer.
The attacker is going to write inside buffer the address of security_critical_function, at the precise location where, if interpreted as an ms data structure, the function pointer would be located:

Once the function pointer is dereferenced, the CPU will in effect jump to security_critical_function:

Please see the full source code for instruction on how to reproduce that attack.
On the computer this code was tested, the payload looks like that:
echo -e "\x11\x11\x11\ ... (16 bytes of \x11 padding) ... \x7c\x16\x40\x00\x00\x00\x00\x00" \
| xargs --null -t -n1 ./use-after-free
./use-after-free ''$'\021\021\021\021\021\021\021\021\021\021\021\021\021\021\021
\021''|'$'\026''@'
Hello, parameter: 12
Launching nukes!
# program continues to misbehave after that
Conclusion
C is not memory safe. The memory safety bugs introduced by programming mistakes lead not only crashes, but more importantly to security vulnerabilities that can have very serious consequences.
Secure Coding Practices
Here we discuss a problem that is inherent to C: the fact that the language is not memory-safe. You can access the slides 🖼️ for this lecture. All the code samples given here can be found online, alongside instructions on how to bring up the proper environment to build and execute them here.
Here we will give a brief overview of some good C coding practices which minimise the amount of bugs one may introduce when writing software with that programming language.
Context
We have seen that memory safety and undefined behaviour issues are common in software written in C, and that these issues lead to security vulnerabilities that can be exploited by attackers to do various forms of bad things. What can we do about it? We can mainly do three things:
- When we develop we need to adhere to good coding practices to minimise as much as possible the changes of introducing such bugs.
- We have techniques that can help analyse our code during development and detect some bugs.
- We also have techniques that can help protect our programs in production, making exploitation more difficult and limiting the damage from successful exploits.
Here we focus on the first point, while the two others are covered next.
Array/Buffer/Integer Overflows
To prevent array buffer overflows, in C remember that they do not embed their sizes so make sure to keep track of the size of each array/buffer you use. You need to know the size of an array to know when to stop iterating, and the size of a destination buffer to know how many bytes you can copy in there.
When manipulating integers, make sure to be aware of the size reserved by the compiler to hold them in memory according to the architecture you are compiling for.
You can use sizeof() to determine these sizes.
While an unsigned integer will never overflow but rather wrap around, overflowing a signed integer leads to undefined behaviour and must be avoided. The compiler has some builtin functions that can tell you if an integer operation overflows. Here is an example of such function:
bool __builtin_add_overflow (type1 a, type2 b, type3 *res)
This function sums the integers a and b and place the result in *res.
It returns true if the addition resulted in an overflow, and false if that is not the case.
These builtin function that check for overflows are available for integer addition, subtraction, and multiplication.
See here for more details.
Unsafe Libc Functions
| Unsafe Function | Why It Is Unsafe | Safe Alternative(s) |
|---|---|---|
gets() | No bounds checking; allows buffer overflows | fgets() |
strcpy() | No bounds checking; can overflow destination buffer | strncpy(), strlcpy() (if available) |
sprintf() | No bounds checking; leads to buffer overflows | snprintf() |
scanf() | No bounds checking e.g., %s with no width | fgets() + sscanf() with width specifiers |
memcpy() | No bounds checking; can cause overflows | Use with care; consider memmove() for overlapping memory |
bcopy() | Obsolete; unsafe due to no bounds checking | memmove() |
strlen() | Not inherently unsafe, but must not be used on untrusted or unterminated buffers | Ensure string is null-terminated before use |
Above you can find a few functions of the C standard library which use should be avoided as much as possible.
You can see the reason why they are unsafe, as well as safe alternatives.
We have seen the strcpy and friends, that does not check for overflow on the buffers they write to.
You should use the safe versions as much as possible, which all have a way to indicate the size of the receiving buffer to avoid overflows.
To move memory you should not rely on bcopy but rather use memcpy with care if the source and target areas do not overlap, and memmove if they do.
Be careful with strlen, it can return numbers larger than the size of a string if that string is not properly terminated.
These are not the only functions to avoid, see this page for more.
Libc: String Manipulation Functions
Once again, regarding string manipulation functions, make sure to use the n versions that force you to indicate a maximum number of characters to process.
These are not perfect though, for example strncpy won’t add the termination character '\0' at the end of the target buffer.
See for example this code in which we wish to replace string2 that is composed of 32 x’s with hello world:
char string1[] = "hello, world";
char string2[32] = "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx";
strncpy(string2, string1, strlen(string1));
printf("%s\n", string2); // prints "hello, worldxxxxxxxxxxxxxxxxxxx"
Because strncpy is not adding the termination character, we end up with a mix of both strings which is probably not what the programmer intended.
Dynamic Memory Allocation
When using dynamic memory allocation, make sure to always check malloc’s return value, for reasons we have previously discussed.
Remember that after free is called upon a pointer, that pointer is invalid and should not be reused in any way.
It should obviously not be dereferenced, but its value should not be used for anything else too.
Be careful with realloc: this function will return NULL upon failure so make sure it does not overwrite the original pointer to the buffer you want to increase the size, otherwise you’ll get a leak.
For example consider this code:
ptr = realloc(ptr, new_size)
This guarantees a leak if realloc fails, which is always a possibility: ptr will be overwritten with NULL, and if you don’t have another pointer referencing the buffer ptr was pointing to, you will never be able to call free on that buffer.
malloc does not zero out memory returned to allocation request, so if you initialise only partially a data structure located in a dynamically allocate buffer, and you pass that data structure to a context that you do not trust, for example by sending it through the network, you may be leaking memory content to that untrusted party.
So for buffers sent to untrusted context it is better to use calloc which will zero out memory allocated.
Of course, note that this comes at the cost of a performance slowdown.
Further Readings
What we saw here are just a few examples of secure coding practices, and we do not have the time to cover them all exhaustively. Here is a list of further resources, make sure to check them out if you want to learn more:
- SEI CERT C Coding Standard
- Robert C. Seacord, Secure coding in C and C++ (book)
- ISO/IEC TS 17961 (C Secure Coding Rules)
- NASA JPL C Coding Standard
- Fedora’s Defensive Coding Guide
Applying these secure coding practices is unfortunately insufficient for preventing 100% of the bugs we may introduce. After all as programmers we are human, and we can’t assume every line of code we write is bug free. So we need more automated tools to detect programming mistakes.
Detecting Bugs
You can access the slides 🖼️ for this lecture. All the code samples given here can be found online, alongside instructions on how to bring up the proper environment to build and execute them here.
We previously saw how to adopt some good practices when writing code to avoid introducing bugs that could translate in security issues. Here we are going to cover a complementary approach, which is the use of automated tools to detect programming mistakes and bugs into existing code bases.
Detecting Coding Mistakes
Here we cover techniques that are slow to execute, or that make the application slow. As a result they cannot run in production, and are rather used during development. These techniques fall within 2 main categories:
- Static analysis, which consists in scanning program’s source code or binary for bugs without executing it.
- Dynamic analysis, which consists in checking for the presence of bugs by running the program.
Static Analysis
Static analysis tools scan the source code of the program for possible bugs without actually running the program. The benefit of this approach is that it has good coverage, it goes over the entirety of the program’s code, which lends itself well to automation. In terms of downsides, static analysis generally suffers from false positives: it means it may identify issues in the code that actually do not represent programming mistakes or security vulnerabilities. Because it does not run the program, the efficiency of static analysis suffers from a limited amount of context, for example most of the memory content is not determined until runtime. Finally, some static analysis techniques are quite slow and do not scale well to the large code bases of certain systems software.
Many static analysis approaches are implemented at the level of the compiler.
A first thing you should do is enable high degrees of compiler warnings.
You can use, by increasing order of pickiness, -Wall to get additional warnings, -Wextra to get even more warnings, and -pedantic to add even more warnings.
See here for details about what warnings are added by each option.
A few example of static analysis tools helping to detect coding mistakes in C programs include:
- The Clang static analyser
- Linthttp://squoze.net/UNIX/v7/files/doc/15_lint.pdf
- Coverity
- Cppcheck
- Among others
Let’s go over an example with the Clang static analyser.
The Clang Static Analyser
Consider the following code:
// includes omitted
int c;
int main() {
int a = INT_MAX;
int b = 1;
c = a + b; // Integer overflow!
char buffer[8];
char str[] = "this string is too long";
strcpy(buffer, str); // Buffer overflow!
int *ptr = (int *)malloc(sizeof(int));
*ptr = 42;
free(ptr);
*ptr = 99; // Use-after-free!
return 0;
}
This program is faulty and contains 3 bugs:
- The first bug is an integer overflow, we add in
c1 to the largest integer that can be stored on an intINT_MAX. - The second bug is a buffer overflow, we copy in
buffer, which size is 8 bytes, a string that is larger than 8 bytes. - And the last bug is a use after free, where we dereference the pointer
ptrafter having freed the buffer it points to.
Notice that with the default level of warnings, this program compiles fine, and also it runs without any visible error. Can static analysis help detect these issues? If we run the Clang static analyser over our program, we get the following output:
$ clang --analyze faulty.c
faulty.c:22:10: warning: Use of memory after it is freed [unix.Malloc]
*ptr = 99; // Use-after-free!
~~~~ ^
1 warning generated.
The tool is able to detect the use after free bug, however it does not detect the two other bugs. For that we need to use dynamic analysis.
Dynamic Analysis
Dynamic analysis tries to detect errors while running the program. Doing so it gets access to more information than static analysis, that is runtime information. It’s also useful when the sources of the program we wish to analyse are not available.
A very popular type of dynamic analysis is achieved through compiler based instrumentation. These are called sanitisers. The most widespread is address (ASan), that will detect a wide range of memory errors that would not be caught at compile time or at runtime without the instrumentation. You also have the undefined behaviour sanitiser (UBSan) that detects things like integer overflows, invalid casts, and so on. Check out this link for more information about sanitisers.
Using Sanitisers
We can enable address sanitiser instrumentation at compile time on our faulty program as follows:
$ clang -fsanitize=address faulty.c -o faulty
Next, if we launch the program, we can see that ASan catches the buffer overflow:
$ ./faulty
=================================================================
==21543==ERROR: AddressSanitizer: stack-buffer-overflow on address 0x7ffcc881f268 # ...
Once we have fixed that particular overflow we can recompile the program, still with address sanitiser, and launch it again. This time we can see that it detects the use after free:
clang -fsanitize=address faulty.c -o faulty
$ ./faulty
./faulty
=================================================================
==22504==ERROR: AddressSanitizer: heap-use-after-free on address 0x602000000010 # ...
And finally, when we enable undefined behaviour sanitiser, and launch the program, the integer overflow is detected:
$ clang -fsanitize=undefined faulty.c -o faulty
$ ./faulty
faulty.c:12:11: runtime error: signed integer overflow:
2147483647 + 1 cannot be represented in type 'int'
Valgrind
There are other dynamic analysis tools available. Most of what came before the sanitisers has been rendered more or less obsolete by them. We have seen Valgrind previously, in addition to reporting about memory leaks, it can also detect certain memory errors. Given that sanitisers also detect memory leaks, that makes Valgrind quite redundant. However, note that with Valgrind there is no need to recompile the program to insert instrumentation, as one do with the sanitisers. So Valgrind is still useful in context where we have only access to the application’s binary and not its sources.
Fuzz Testing AKA Fuzzing
Fuzzing consists in blasting a trust boundary with malformed inputs with the hope to trigger bugs. Examples of trust boundaries that are good candidates for fuzzing include the command line arguments, input files, network packets, and so on. Fuzzing is highly popular these days, and has help uncover a very large number of bugs in many projects.
Let’s see an example of fuzzing with the widely popular toot American Fuzzy Lop (AFL).
Consider this vulnerable program:
int main(int argc, char *argv[]) {
char name[32]; // Vulnerable buffer (too small for unchecked input)
if (argc < 2) {
printf("Usage: %s <input file>\n", argv[0]);
return 1;
}
FILE *f = fopen(argv[1], "r");
if (!f) {
printf("Error, can't open %s\n", argv[1]);
return 1;
}
fread(name, 1, 512, f); // Reads up to 512 bytes into a 32-byte buffer!
fclose(f);
printf("hello %s\n", name);
return 0;
}
This program opens a file and reads its content into a buffer. It reads 512 bytes, however the destination buffer is only 32 bytes long, so there is a possibility of overflow here. The name of the file to read comes from the command line.
By fuzzing this program with AFL, we are going to inject many different types of files as its first command line argument, and hope that some will trigger the bug.
To install AFL on a Debian/Ubuntu system, install this package:
$ sudo apt install afl # or afl++ on very recent ubuntu/debian distributions
Next let’s compile our vulnerable program and instrument it for fuzzing with AFL.
That instrumentation will include enabling ASan to detect a maximum amount of bugs, and code coverage statistics to measure the progress of the fuzzing process.
This is done with a compiler wrapper named afl-clang:
$ afl-clang fuzzme.c -o fuzzme
Before we start to fuzz we need to create some seed input file to kick-start the fuzzing process:
$ mkdir input
$ echo "testname" > input/seed
We can now start the fuzzing process:
$ AFL_SKIP_CPUFREQ=1 afl-fuzz -i input -o output -- ./fuzzme @@
After a few seconds, stop the fuzzing with ctrl+c.
If AFL found any bugs, which should be the case for our example, the output (here, files) that generated the crashes will be saved in output/default/crashes.
You can reproduce the crashes by compiling the target program normally, and injecting the output in question:
$ clang -g -fsanitize=address fuzzme.c -o fuzzme
$ ./fuzzme output/default/crashes/id:000000,sig:11,src:000000,op:havoc,rep:128
You should get a nice ASan crash report pointing out the overflow in the program.
Fuzzing is a vast field, here are a few pointers if you want to dig deeper:
- Sutton et al., Fuzzing: Brute Force Vulnerability Discovery
- The Fuzzing Book
- Fuzzing 101: https://github.com/antonio-morales/Fuzzing101
Other Static and Dynamic Analysis Approaches
There are other static and dynamic analyses techniques that are worth mentioning. You are probably already familiar with unit testing and manual code reviews, as well as with tools to check that your code follows a certain style that maximises clarity and reduces the chances of introducing bugs.
There are other advanced/researchy techniques to find bugs or prove the correctness of software, such as taint analysis, symbolic execution, abstract interpretation, formal verification, or model checking.
To conclude, we covered the use of various automated tools to try to detect bugs in existing code. They belong in two main categories, static and dynamic analysis approaches. Unfortunately, even if you combine these with the secure coding practices we saw previously, none of these approaches will allow you to get rid of 100% of the bugs and vulnerabilities. We also need defences executing at runtime in production, to make exploits harder and limit their damage.
Runtime Defences
You can access the slides 🖼️ for this lecture. All the code samples given here can be found online, alongside instructions on how to bring up the proper environment to build and execute them here.
We have previously covered good coding practices to avoid introducing bugs, and analysis techniques to detect bugs in existing code bases. Here we discuss defences running at runtime in production.
Non-Executable Memory
Back in the days a large part of the address space use to be accessible with execution right. That included the stack, which was really awful from the security point of view: indeed it meant that an attacker could write malicious machine code in there, for example through an overflow on the stack, and then have the CPU jumps to it. That is called a code injection attack.
In the early 2000s hardware support appeared for setting part of the address space as non-executable. It was used to set everything that should not be accessed i executable mode as non-executable: the stack, heap, static data sections, and so on:

Such non-executable memory made code injection attacks much less likely in the corresponding areas. Today modern systems software aim to enforce the write XOR execute principle for each memory area. That principle states that you cannot have an area of memory be both writable and executable at the same time.
Address Space Layout Randomisation (ASLR)
Another defence that is present in almost every system today is address space layout randomisation. With ASLR each invocation of the program will have a different layout for the address space, in other words code and variable won’t be at the same location in memory for subsequent invocations:

The goal is to make it harder for the attacker to determine where is what in the address space Recall from the attacks we have seen that many of them require us to know exactly where a buffer to overflow is present or the stack, or exactly where we need to jump in the code segment. This is achieved by observing one invocation of the program, for example with a debugger. And then starting the attack upon a second invocation of the program. With ASLR that won’t work anymore because the locations of the data and code we determine with the first invocation are not the same for the second.
ASLR Granularity
Please note that the granularity of ASLR is coarse-grained: for performance reasons we cannot really randomise the location of each variable independently. So randomisation is realised at the level of large areas of the virtual address space called program’s segments, as illustrated above. It is realised at load time for the main program, and for dynamic libraries it’s also realised when they are loaded.
To illustrate the granularity of ASLR on Linux and understand the relevant security implications, consider the following program:
int global1 = 42;
int global2 = 43;
int main() {
int local1 = 24;
int local2 = 25;
int *heap_ptr1 = malloc(sizeof(int));
int *heap_ptr2 = malloc(sizeof(int));
printf("data addr 1: %p\n", &global1);
printf("data addr 2: %p\n", &global2);
printf("stack addr 1: %p\n", &local1);
printf("stack addr 2: %p\n", &local2);
printf("heap addr 1: %p\n", heap_ptr1);
printf("heap addr 2: %p\n", heap_ptr2);
free(heap_ptr1);
free(heap_ptr2);
}
This program simply prints the addresses of two local variables, 2 global variables, and 2 heap pointers. An example of execution will output the following:
$ ./aslr # First execution
data addr 1: 0x55aa68336028
data addr 2: 0x55aa6833602c
stack addr 1: 0x7ffdf6d8bbac
stack addr 2: 0x7ffdf6d8bba8
heap addr 1: 0x55aaa113a2a0
heap addr 2: 0x55aaa113a2c0
$ ./aslr # Second execution
data addr 1: 0x562632aec028
data addr 2: 0x562632aec02c
stack addr 1: 0x7ffd2ffe4fbc
stack addr 2: 0x7ffd2ffe4fb8
heap addr 1: 0x56264178d2a0
heap addr 2: 0x56264178d2c0
As you can see the relative distance between 2 variables located in a different segment is randomised across different executions of the same program. However, the relative distance between 2 variables belonging to the same segment stays the same across executions. That is before only the base address of each segment is randomised at load time. What that means is that if the attacker can leak the value of a single pointer, it is easy for them to compute the address of all other data or code within the containing segment. Hence, the coarse grained nature of ASLR on modern system makes it easy to break.
Stack Canaries
The stack canary is a technique that aims to protect the return address on the stack. The key idea is to place a magic value named the canary right before the return address in a callee’s stack frame. And to compare the canary’s value to a ground truth when the callee’s return:

More precisely, canaries work as follows. First, at build time the compiler generates code to push the canary on the stack upon certain function calls. Here the canary’s value is 0x1234:

When the callee returns, the canary’s value is checked to make sure it is still 0x1234:

The key idea is that an overflow aiming at rewriting the return address would also overwrite the canary:

The check of an overwritten canary value against the ground truth will fail, which in effect detects the attack and stops the program.
By default, canaries will be applied only to certain functions.
You can use the -fstrack-protector-strong to apply it to a larger subset of your program’s functions, and -fstack-protector-all to apply it to every function in your program.
More canaries will increase the security of your program, but also will increase performance and code size overheads.
Stack canaries are not a perfect protection. With current implementations, the same canary value is used to protect all function calls. This means that if the attacker can leak the canary value, for example if there is a an overflow in read mode on the stack, then the protection is broken for the entire program.
Other Common Hardening Techniques
Stripping Binaries
Other common protection techniques include stripping your program from symbols and debug information:
strip <binary>
This makes reverse-engineering a program available in binary form only, a crucial step in many attacks, much more difficult.
Read-Only Relocations (RELRO)
Read only relocations is a protection technique against attacks aiming at overwriting the relocation, which is the method used to resolve calls to shared libraries at runtime. You can see these as a form of function pointers. Partial and full read-only relocation sets part or all of the corresponding area of the address space read only. Once again here you have a trade-off to chose between security and performance overhead, as full RELRO will make load time much longer.
Partial RELRO is enabled by default with modern compilers. To enable full RELRO, add these compiler flags:
-Wl,-z,relro,-z,now
_FORTIFY_SOURCE Macro
The FORTIFY_SOURCE macro enables some buffer overflow protection checks before sensitive functions such as the string manipulation ones and memcpy.
There are 2 levels for it, the second one adding more checks but coming at the risk of breaking your program, so only use it if you can fully test that things run OK.
Add the following flags to the compiler to enable it:
--D_FORTIFY_SOURCE=1(level 1)--D_FORTIFY_SOURCE=2(level 2)
checksec
You can analyse a binary to check for the presence or absence of all the hardening techniques we covered with the checksec tool.
Here is an example of usage:
$ gcc -fstack-protector-strong -D_FORTIFY_SOURCE=2 -O2 -Wl,-z,relro -Wl,-z,now myapp.c -o myapp
$ strip myapp
$ checksec --file myapp
RELRO STACK CANARY NX PIE Symbols FORTIFY
Full RELRO Canary found NX enabled PIE enabled No Symbols Yes
We have covered all the protections here. Regarding PIE, it means position independent executable, and it is a prerequisite for the binary to be compatible with ASLR.
Control Flow Integrity (CFI)
Let’s talk a bit more in details about a last, more advanced, technique, named control flow integrity. We have seen previously how control flow hijacking attacks force the program to take code paths that were not intended by the programmer. CFI enforce that the code paths executed by the program conform to the control flow graph originally intended by the programmer. CFI generally involves two protections. Forward edge CFI, checking that function pointers and C++ virtual table always have a legitimate target. And backward edge CFI, checking that return addresses also always have a legitimate target.
Forward Edge CFI
Regarding forward edge protection, CFI enforce that when a function pointer or an entry in a C++ virtual table is called, the target should be a valid function. What valid means depends on the implementation. With coarse grain CFI, the protection will just check that the target is the beginning of a function. With fine grain CFI, the protection will make sure that only the functions which addresses are assigned to the function pointer or virtual table in the code can be called.
The Clang/LLVM compiler has a software implementation of CFI, to enable it use the following compiler flags:
clang -g -fsanitize=cfi -flto -fvisibility=hidden program.c -o program
This will instruct the compiler to insert the necessary instrumentation for CFI checks.
Recent Intel processors also have CFI in hardware, implemented as a technology called Control Flow Enforcement: there is a special instruction endbranch64 that indicate valid targets for function pointers of virtual table member invocation.
Backward Edge CFI
Regarding backward edge protection, which protect the return address on the stack, this is achieved for CFI with what is called a shadow stack. It’s a separate stack that is that stores a copy of the return address upon function call. When that callee returns, the return address to jump to is checked against the copy in the shadow stack: if they don’t match, something fishy is going on.
Let’s unroll an example to understand how the shadow stack works.
Assume we are running the code of a function f1, we have its frame on the stack, and the shadow stack which is empty for now:

When f1 calls f2, it pushes the return address on the stack normally, but also a copy of it on the shadow stack:

When f2 calls f3, the process is repeated, and same thing when f3 calls f4:

When f4 returns in f3, the return address on the stack is checked against the corresponding entry in the shadow stack.

If they match it’s all good.
If there was an overflow, they would be different.
f3 then returns in f2, and we get another check:

And f2 returns in f1, another check:

Of course the shadow stack needs to be placed by the compiler at a location in memory that is very hard for an attacker to read or write.
To conclude, we have seen defences that can be applied at runtime and that are commonly used in production to detect exploits, make them much harder to achieve, and limit the damage that an attacker can do with exploits that succeed. Because these things run in production, their performance overhead needs to be low, generally just a few percents.
C Programming: Going Further
There is no exercise for this week.
Below you can find a list of exercises representing examples of C projects that are more ambitious than the autocorrected tests you have done until now, while still being quite didactic. They are fully optional and do not need to be done to complete the unit: check these out if you would like to go further. Due to the nature of these exercises, COMP26020 instructors cannot provide support to complete them, so you are on your own!
If you find that kind of low-level programming exciting, please consider doing your Y3 project with me 🙂.
- Writing a Linux kernel module. In this exercise you will write a bit of code and load it at runtime within the Linux kernel. Consider starting to read from the introduction in order to understand how to set up your distribution for kernel development. The rest of the book is great too, covering many aspects of Linux kernel programming.
- Writing a simple web server. In less than 200 lines of code!
- Using Linux’s optimised
io_uringI/O API. Here you will build various simple applications (2 programs equivalent to thecatandcpcommands and a simple web server) using the optimisedio_uringAPI which provides significant enhancements vs. using what we saw in the unit i.e.read/writeand their variants. - Emulate a simple device in Qemu and write a driver for it in Linux. Here you will emulate a simple device in Qemu and will access it from a virtual machine through a driver you’ll write. This is part of an assignment for another course I am running, please disregard anything regarding submission/deadlines/marking scheme.
- Writing a minimal OS kernel. This OS contains the bare-bones code (assembly for the boot process, then C) to print on the console. You can access more cool OS tutorials here.
- Writing a compiler. This is a relatively ambitious project in which you’ll build a self-compiling compiler, i.e. a compiler that can compile itself (yes, after all the compiler is itself a program, and is built from source code!).